
前端效率工程化
https://vkc4zz0ocm.feishu.cn/wiki/wikcnsDyZCFIbm2W0KhEncxGZke#mindmaphttps://github.com/ruanyf/jstraining/blob/master/docs/engineering.md
一个中高级前端工程师
- 完成业务功能开发目标
- 对所开发项目的效率、性能、质量等工程化维度去制定和实施技术优化目标
以提升效率为目标的优化技术和工具属于效率工程化的范畴
效率提升通常会被作为技术层面的一个重点优化方向。面试中,对效率工程化的理解程度和实践中的优化产出情况,是衡量前端工程师能力高低的常见标准。
投身在业务开发中的前端同学,在效率工程化方面经常面临的困扰
- 缺乏系统化知识,对于项目中的效率问题常常不知从何处着手,甚至找错解决方向
- 缺少工程化的视野,难以发现工作中的效率提升点和制定针对性的提升方案
- 技术晋升和面试求职中,缺少方法论和深度思考,很难在能力表现上脱颖而出
找到自己的短板来做针对性提升:
全面、系统地掌握效率的影响因素以及其中的技术细节
在这一节中,梳理了前端开发工作流程中和效率提升相关的知识点和案例
希望借此帮你构筑一个系统性的前端效率知识体系,建立正确的问题解决思路
一、开发效率
1.项目基石:前端脚手架工具探秘
1.1 脚手架工具
- 利用脚手架工具,可以经过几个简单的选项快速生成项目的基础代码
- 使用脚手架工具生成的项目模板通常是经过经验丰富的开发者提炼和检验的
- 脚手架工具支持使用自定义模板,可以根据项目中的实际经验总结、定制一个脚手架模
1.2 前端工程师要掌握的基本能力
通过技术选型来确定所需要使用的技术栈然后根据技术栈
选择合适的脚手架工具,来做项目代码的初始化
1.3 什么是脚手架?
工程施工领域:**脚手架 (Scaffold)**一一为了保证施工过程顺利而搭建的工作平台
软件开发领域:脚手架指通过各种工具来生成项目基础代码的技术。代码中通常包含项目开发流程中所需的工作目录内的通用基础设施
对于日常的前端开发流程,项目内有哪些部分属于通用基础设施呢?
1.4 进入开发前的准备
- 1.需要有 package.json ,它是 npm 依赖管理体系下的基础配置文件
- 2.然择使用 npm 或 Yarn 作为包管理器
- 3.确定项目技术栈,在明确选择后安装相关依赖包并在 src 目录中建立入口源码文件
- 4.选择构建工具,主流选择是 webpack (除非项目已先锋性地考虑尝试 nobundle 方案)
- 对应项目里需要增加相关的 webpack 配置文件,可以考虑针对开发/生产环境使用不同配置文件
- 5.打通构建流程,安装与配置各种 Loader、插件和其他配置项
- 6.优化构建流程,针对开发/生产环境的不同特点进行各自优化
- 7.选择和调试辅助工具,例如代码检查工具和单元测试工具,安装相应依赖并调试配置文件
- 8.检查各主要环节的脚本是否工作正常,编写说明文档 READMEmd
- 不需要纳入版本管理的文件目录记入 gitignore 等
1.5 示例项目模板
package.json 1)npm 项目文件
packagelock.json 2)npm 依赖lock 文件
public/ 3)预设的静态目录
src/ 3)源代码目录
main.ts 3)源代码中的初始入口文件
router.ts 3)源代码中的路由文件
store/ 3)源代码中的数据流模块目录
webpack/ 4)webpack配置目录
common.config.js 4)webpack 通用配置文件
dev.config.js 4)webpack 开发环境配置文件
prod.config.js 4)webpack 生产环境配置文件
.browserlistrc 5)浏览器兼容描述 browserlist 配置文件
babel.config.js 5)ES 转换工具 babel配置文件
tsconfig.json 5)TypeScript 配置文件
postcss.config.js 5)CSS后处理工具 postcss 配置文件
eslintrc 7)代码检查工具eslint 配置文件
jest.config.js 7)单元测试工具iest 配置文件
.gitignore 8)Git 忽略配置文件
README.md 8)默认文档文件1.6 代表性的脚手架工具
| 名称 | 模板框架 | 多选项生成 | 支持自定义模板 | 特点 |
|---|---|---|---|---|
| Yeoman | - | 是 | 是 | 庞大的生成器仓库 |
| Create-React-App | React | 否 | 是 | React 官方维护 |
| Vue CLI | Vue | 是 | 是 | Vue 官方维护 |
- Yeoman 由 Googlel/0 在 2012 年首次发布功能:基于特定生成器(Generator)来创建项目基础代码它提供足够的开放性和自由度。
- 但缺乏某一技术栈的深度集成和技术生态。
- Yeoman 更多用于一些开发流程里特定片段代码的生成
- Create React App (简称 CRA) 是 Facebook 官方提供的 React 开发工具集
- create-react-app 用于选择脚手架创建项目.
- react-scripts 提供了封装后的项目启动、编译、测试等基础工具
- CRA 将一个项目开发运行时的各种配置细节 完全封装在一个 react-scripts 依赖包中 但为后期的用户自定义优化带来了困难
- Vue CLI 由 Vue.js 官方维护,其定位是 Vue.js 快速开发的完整系统完整的 VueCLI 由三部分组成
- 作为全局命令的 @vue/cli
- 作为项目内集成工具的 @vue/cli-service
- 作为功能插件系统的 @vue/cli-plugin-
- VueCLI 保留了创建项目开箱即用的优点提供了用于覆盖修改原有配置的自定义构建配置文件和其他工具配置文件
- VueCLI 提供了通过用户交互自行选择的一些定制化选项例如是否集成路由、 TypeScript 等
三者的理念和优缺点
Yeoman 代表一般开源工具的理念
- 它专注于实现脚手架生成器的逻辑和提供展示第三方生成器,主要目标群体是生成器的开发者
CRA 代表面向某一技术栈降低开发复杂度的理念
- 它提供一个包含各开发工具的集成工具集和标准化的开发-构建测试三步流程脚本
Vue CLI 代表更灵活折中的理念
- 继承了 CRA 降低配置复杂度的优点
- 在创建项目的过程中提供更多交互式选项来配置技术栈的细节,允许在项目中使用自定义配置
了解脚手架模板中的技术细节
对脚手架足够熟悉,能减少花费的时间,提升开发效率要了解一个脚手架,需要学会如何使用脚手架来创建项目还需要了解它提供的具体功能边界,提供了哪些功能、哪些优化
除了通过脚手架模板生成项目外项目内部分别使用 react-scripts 和 vue-cli-service 作为开发流程的集成工具
1.7 webpack 工具系统
webpack loades 工具系统
webpack plugins 插件系统
webpack.optimize
两者在代码优化配置中相同的部分包括:
- 都使用 TerserPlugin 压缩 JavaScript ,都使用 splitChunks 做自动分包 (参数不同)
- CSS 的压缩分别采用 OptimizeCssAssetsWebpackPlugin 和 OptimizeCssNanoPlugin
- react-scripts 中开启了 runtimeChunk 以优化缓存
webpack resolve
在 resolve 和 resolveloader 部分
- 两者都使用 PnpWebpackPlugin (pnp)
- 来加速使用 Yarn 作为包管理器时的模块安装和解析
1.8 如何定制一个脚手架模板
对通过这些脚手架创建的模板项目进行定制化,例如:
- 1.为项目引入新的通用特性
- 2.针对构建环节的 webpack 配置优化,来提升开发环境的效率和生产环境的性能等
- 3.定制符合团队内部规范的代码检测规则配置
- 4.定制单元测试等辅助工具模块的配置项
- 5.定制符合团队内部规范的目录结构与通用业务模块,例如业务组件库、辅助工具类、页面模板等
通过将实际项目开发中所需要做的定制化修改输出为标准的脚手架模板
- 最大程度减少大家在开发中处理重复事务的时间
- 减少因为开发风格不一导致的团队内项目维护成本的增加
1.9 使用创建定制脚手架模板
为 create-react-app 创建自定义模板
个最简化的 CRA 模板中包含如下必要文件:
- README.md:用于在 npm 仓库中显示的模板说明
- packagejson:用于描述模板本身的元信息 (例如名称、运行脚本、依赖包名和版本等)
- template.json:用于描述基于模板创建的项目中的 package.json 信息
- template 目录:用于复制到创建后的项目中,其中.gitignore 在复制后重命名为 gitignorepublic/index.html 和 src/index 为运行 react-scripts 的必要文件
将模板通过 npm link 命令映射到全局依赖中,或发布到 npm 仓库中然后执行创建项目的命令
npx create-react-app [app-name] --template [template-name]为 VueCLI 创建自定义模板
meta.js/json 文件:描述创建过程中的用户交互信息以及用户选项对于模板文件的过滤等
[template-name]/
README.md(for npm)
meta.js or meta.json
template使用自定义模板创建项目的
npm install-g @vue/cli-init
vue init [template-name] [app-name]2.界面调试:浏览器热更新(HRM)技术如何开着飞机修引擎?
2.1 什么是浏览器的热更新
看见浏览器热更新,很容易想到 webpack 和 webpack-dev-server 简单地执行 npm start(cra) 或 npm run serve(vue cli),就能体验到热更新的效果
浏览器的热更新,指的是
在本地开发的同时打开浏览器进行预览,当代码文件发生变化时,浏览器自动更新页面内容的技术
自动更新,表现上分为:
- 自动刷新整个页面
- 页面整体无刷新而只更新页面的部分内容
以 webpack 工具为例,来看下四种不同配置对结果的影响:完整示例代码:https://github.com/fe-efficiency/lessons_fe_efficiency/02_webpack_hmr
一切依赖手动模式(Auto Compile)
src/index0.js
function render() {
div = document.createElement("div");
div.innerHTML = "Hello Worldo";
document.body.appendChild(div);
}
render();webpack.config.basic.js
module.exports = {
entry: "./src/index0.js",
mode: "development",
};package.json
"scripts": {
"build:basic":"webpack --config webpack.config.basic.js"
}wath 模式
webpack.config.watch.js
{
"watch": true
}package.json
"script": {
"build:watch": "webpack --config webpack.config.watch.js"
}为了看到执行效果,需要在浏览器中进行预览
但在预览时会发现,即使产物文件发生了变化
在浏览器里依然需要手动点击刷新才能看到变更后的效果
Live Reload
webpack.config.reload.js
{
"devServer": {
"contentBase": "/dist", // 为./dist目录中的静态页面文件提供本地服务渲染
"open": true // 启动服务后自动打开浏览器网页
}
}package.json
"script": {
"build:watch": "webpack --config webpack.config.reload.js"
}在浏览器中输入网址:http://localhost:8080/index.html
(也可以在 devServer 的配置中加入 open 和 openPage 来自动打开网页)并打开控制台网络面板
在开发调试过程中会在网页中进行一些操作
例如输入了一些表单数据想要调试错误提示的样式、打开了一个弹窗想要调试其中按钮的位置
切换回编辑器,修改样式文件进行保存
网页刷新后回到了初始化的状态,不得不再次重复操作才能确认改动后的效果
Hot Module Replacement
src/index1.js
import ./style.csssrc/style.css
div {
color: red;
}webpack.config.hmr.js
{
entry: './src/index1.js',
// ...
devServer:{
hot: true
}
module:{
rules:[
{
test: /\.csss$/,
use: ['style-loader', 'css-loader']
}
]
}
}package.json
"script": {
"build:watch": "webpack --config webpack.config.hmr.js"
}浏览器打开页面后,查看网页源码,会发现 css 会添加在页面 head 标签里面的 style 里
浏览器打开页面后新增了两个请求: hot-update.json 和 hot-update.js
热更新是保存后自动编译 (Auto Compile) 吗? 还是自动刷新浏览器(Live Reload) ? 还是指 HMR(Hot Module Replacement,模块热替换) ?
这些不同的效果背后的技术原理是什么呢?
为什么导入的 CSS 能触发模块热替换而 JS 文件的内容修改就失效了呢?
webpack 中的热更新原理

可以基于 Node.js 中提供的文件模块 fs.watch 来实现对文件和文件夹的监控
也可以使用 sockjs-node 或 socket.io 来实现 Websocket 的通信
2.2 webpack 中的打包流程
- module: 指在模块化编程中我们把应用程序分割成的独立功能的代码模块
- chunk: 指模块间按照引用关系组合成的代码块,一个 chunk 中可以包含多个 module
- chunk group: 指通过配置入口点 (entry point) 区分的块组一个 chunk group 中可包含一到多个 chunk
- bundling: webpack 打包的过程 asset/bundle: 打包产物
.......等等 webpack 的热更新功能
3.构建提速:如何正确使用 SourceMap?
为什么我的项目在开发环境下每次构建还是很卡?每次保存完代码都要过 1~2 秒才能看到效果?这是怎么回事呢?
前端库开发基础中,编写的源代码会经过多重处理 (编译、封装、压缩等),最后形成产物代码
什么是 Source Map
source-map 的基本原理,在编译处理的过程中:在生成产物代码的同时生成产物代码中被转换的部分与源代码中相应部分的映射关系表
通过 Chrome 控制台中的"Enable Javascript source map"来实现调试时的显示与定位源代码功能
- 对于同一个源文件,根据不同的目标,可以生成不同效果的 source map
- 在构建速度、质量(反解代码与源代码的接近程度以及调试时行号列号等辅助信息的对应情况)
- 访问方式(在产物文件中或是单独生成 source map 文件)和文件大小等方面各不相同
对于 source map 功能的期望不同:
- 在开发环境中,通常关注的是构建速度快,质量高,以便于提升开发效率
- 在生产环境中,通常更关注是否需要提供线上 source map 生成的文件大小和访问方式是否会对页面性能造成影响等,其次才是质量和构建速度
webpack 中的 source map 预设
webpack/lib/WebpackOptionsApply.js:232
Source Map 名称关键字
- false:不开启 source map 功能,其他不符合上述规则的赋值也等价于 false
- eval: 在编译器中使用 EvalDevToolModulePlugin 作为 sourcemap 的处理插件
- [xxx-...]source-map: 根据 devtool 对应值中是否有 eval 关键字来决定使用 EvalSourceMapDevToolPlugin 或 SourceMapDevToolPlugin 作为 sourcemap 的处理插件其余关键字则决定传入到插件的相关字段赋值
- inline: 决定是否传入插件的 filename 参数,作用是决定单独生成 source map 文件还是在行内显示该参数在 eval- 参数存在时无效
- hidden: 决定传入插件 append 的赋值,作用是判断是否添加 SourceMappingURL 的注释该参数在 eval- 参数存在时无效
- module: 为 true 时传入插件的 module 为 true ,作用是为加载器(Loaders) 生成 source map
- cheap: 当 module 为 false 时,它决定插件 module 参数的最终取值,最终取值与 cheap 相反决定插件 columns 参数的取值,作用是决定生成的 source map 中是否包含列信息在不包含列信息的情况下,调试时只能定位到指定代码所在的行
- nosource: 决定插件中 noSource 变量的取值,作用是决定生成的 source map 中是否包含源代码信息不包含源码情况下只能显示调用堆栈信息
Source Map 处理插件
- EvalDevToolModulePlugin: 模块代码后添加 sourceURL=webpack:///+ 模块引用路径不生成 source map 内容,模块产物代码通过 eval()封装
- EvalSourceMapDevToolPlugin: 生成 base64 格式的 source map 并附加在模块代码之后 source map 后添加 sourceURL=webpack:///+ 模块引用路径,模块产物代码通过 eval()封装
- SourceMapDevToolPlugin: 生成单独的.map 文件,模块产物代码不通过 eval 封装
不同参数组合下的各种预设对 source map 生成又各自会产生什么样的效果呢?
不同预设的示例结果对比
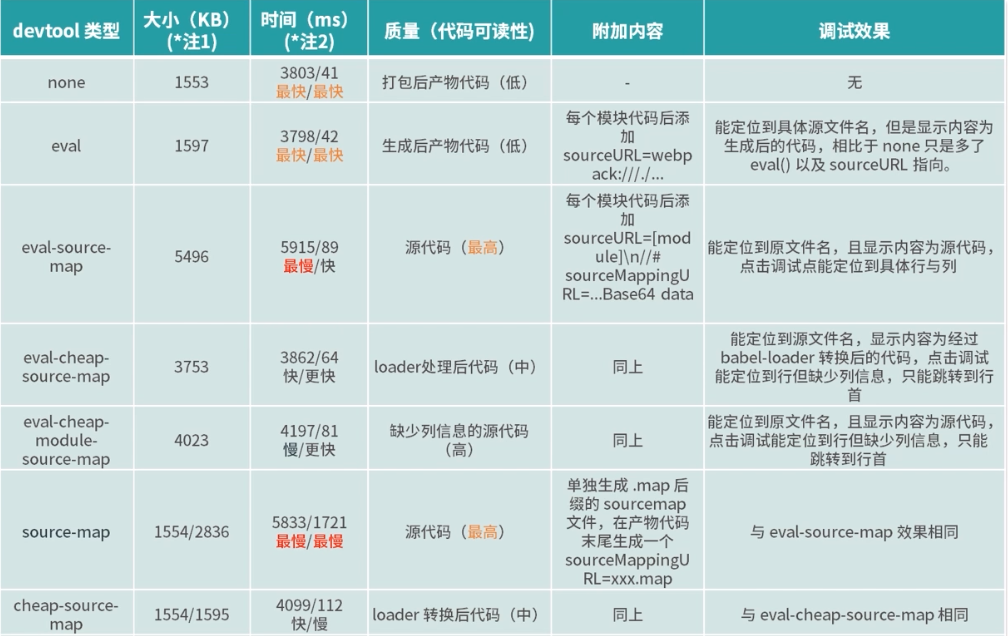
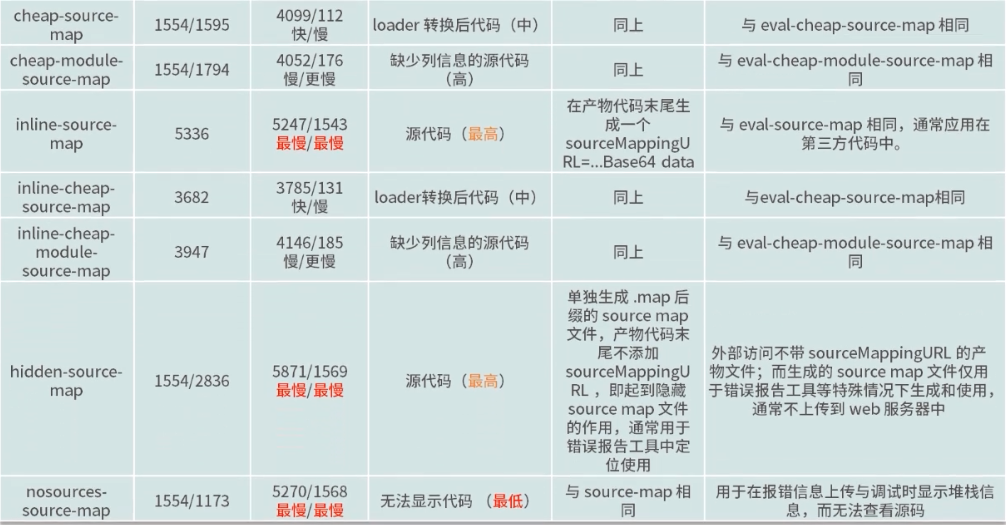
注 1:“/” 前后分别表示产物 is 大小和对应.map 大小
注 2:“/” 前后分别表示初次构建时间和开启 watch 模式下 rebuild 时间。对应统计的是 development 模式下的笔者机器环境下几次构建时间的平均值,只作为相对快慢与量级的比较
不同预设的效果总结
质量
对应的调试便捷性依次降低:
- 源代码>缺少列信息的源代码 >loader 转换后的代码>生成后的产物代码>无法显示代码
对应对质量产生影响的预设关键字优先级:
- souce-map = eval-source-map > cheap-module- > cheap- > eval= none > nosource-
构建速度
在开发环境下:一直开着 devServer ,再次构建的速度对效率影响远大于初次构建的速度 eval-对应的 EvalSourceMapDevToolPlugin 整体要快于不带 eval-的 SourceMapDevToolPlugin
在生产环境下:通常不会开启再次构建,初次构建的速度更值得关注对构建速度以外因素的考虑要优先于对构建速度的考虑
包的大小和生成方式
- 需要关注速度和质量来保证高效开发体验
- 其他的部分则是在生产环境下需要考虑的问题
不同质量的源码示例
1.源码且包含列信息
2.源码不包含列信息
3.loader 转换后代码
4.生成后的产物代码
开发环境下 Source Map 推荐预设
- 开发环境首选哪一种预设取决于 source map 对于我们的帮助程度
- 如果对项目代码了如指掌,可以关闭 devtool 或使用 eval 来获得最快构建速度
- 如果在调试时,需要通过 source map 来快速定位到源代码优先考虑使用 eval-cheap-modulesource-map ,它的质量与初次/再次构建速度都属于次优级
- 根据对质量要求更高或是对速度要求更高的不同情况可以分别考虑使用 eval-source-map 或 eval-cheap-source-map
几种工具和脚手架中的默认预设
- webpack 配置中,默认值 eval,模块代码后多了 sourceURL 以帮助定位模块的文件名称
- create-react-app 中
- 生产环境下,根据 shouldUseSourceMap 参数决定使用 source-map’或 false
- 开发环境下,使用 cheap-module-source-map(不包含列信息的源代码,但更快)
- vue-cli-service 中,与 creat-react-app 中相同
EvalSourceMapDevToolPlugin 的使用
EvalSourceMapDevToolPlugin 的传入参数
- 预设相关的 filename、append、module、columns
- 影响注释内容的 moduleFilenameTemplate 和 protocol
- 影响处理范围的 test、include、exclude
示例
webpack.config.js
//devtool: 'eval-source-map',
devtool: false,
plugins: [
new webpack.EvalSourceMapDevToolPlugin({
texclude: /node_modules/,
module: true,
columns: false
})
]4.接口调试: Mock 工具如何快速进行接口调试?
什么是 Mock?
- 在程序设计中使用模拟(Mock)的对象来替代真实对象以测试其他对象的行为
- 在前端开发流程中指模拟数据(俗称假数据)以及生成和使用模拟数据的工具与流程
在一个前后端分离的开发项目中
- 前端开发时间 t1,后端开发时间 t2,前后端联调时间 t3
- 整体的项目开发时间是
<=max (t1,t2) + t3 - 将整个开发流程按功能点进行更细粒度地拆分部分功能开发完成后立即进行联调
前端需要依赖一定的数据模型来组织页面与组件中的交互流程
数模型依赖着后端提供的 API 接口
如何实现前端的无依赖的独立开发以提升效率呢?
答案就是:使用 Mock 数据
- 假设在后端实际 API 功能完成之前
- 能获得对应的模拟数据作为接口的返回值来处理前端交互中的数据模型
- 待开发完成进入联调后将假数据的部分切换到真实的后端服务接口数据
选择 Mock 方案的考量标准
- 1.直接在代码中侵入式地书写静态返回数据来调试相关逻辑
- 方法的优缺点
- 2.使用后端开发服务作为 Mock 服务,将未实现的功能在后端返回 Mock 数据
- 方法的优缺点
- 3.通过一些本地 Mock 工具,使用项目本地化的 Mock 规则文件来生成 Mock 数据
- 方法的优缺点
- 4.使用功能更丰富的接口管理工具来提供独立的 Mock 能力
- 方法的优缺点
仿真度
- Mock 数据需要在接口定义上尽可能与后端实际提供接口的各方面保持一致
- 数据定义的仿真度是决定实际模拟过程效率和质量的首要因素
- 通常在开发初期通过接口文档的方式来提供,或由提供类似功能的 Mock 工具来提供
易用性
- 高效的 Mock 工具需要具备将接口文档自动转换为 Mock 接口的能力
- 当接口发生变化时会首先更新到文档中,并自动反映到提供的 Mock 数据中
- 后端提供的真实服务应当完整通过 Mock 接口的测试
灵活性
- 实际的接口调用中会根据不同的调用方式与传入参数等条件来输出不同的返回值
- 前端根据不同条件下返回值的差异做不同的交互处理
Mock.js
Mock.is 的核心能力是
定义了两类生成模拟数据的规范,以及实现了应用相应规范生成模拟数据的方法
数据模板定义规范 (Data Template Definition,DTD)
Mock.mock({
"number|1-100": 1,
});
// Result: number为1-100内随机数,例如fnumber: 73
Mock.mock({
"boo|1-100": true,
});
// Result: boo为true或false,其中true的概率为1%,例如boo: false
Mock.mock({
"str|1-100": "1",
});
// Result: str为1-100个随机长度的字符串1。例如{str:'111119'}数据占位符定义规范 (Data Placeholder Definition,DPD)
Mock.mock("@email"); // Result: 随机单词连接成的email数据,例如: n.clark@miller.io
Mock.mock("@city(true)"); // Result: 随机中国省份+省内城市数据,例如:“吉林省 辽源市
Mock.mock({
"aa|1-3": ["@cname()"],
}); // Result: aa值为随机3个中文姓名的数组,例如faa:['张三!李四,王五个
Random.image("200x100", "#894FC4", "#FFF", "png", "!");
// Result: 利用dummyimage库生成的图片url。"http://dummyimage.com/200x100/894FC4/FFF.png"占位符既可以用于单独返回指定类型的随机数据,又能结合数据模板作为模板中属性值的部分来生成更复杂的数据类型。Mock.js 中定义了 9 大类共 42 种占位符
其他功能
- 1.Ajax 请求拦截
- Mock.mock 方法中支持传入 Ajax 请求的 url 和 type
- Mock.setup 方法设置拦截 Ajax 请求后的响应时间
- 2.数据验证
- Mock.valid 方法验证指定数据和数据模板是否匹配
- 用于验证后端 API 接口的返回值与对应 Mock 数据的规则描述是否冲突
- 3.模板导出
- Mock.to.JSONSchema
- 用于将数据模板导入到支持 JSON Schema 格式的工具中
Faker.js
// 单独使用api方法
var randomName = faker.name.findName(); // Rowan Nikolaus
var randomEmail = faker.internet.email(); // Kassandra.Haley@erich.biz
var randomCard = faker.helpers.createCard(); // random contact card containing
// many properties
// 使用fake来组合api
faker.fake("{{name.lastName}}, {{name.firstName}} {{name.suffix}}");
// outputs: "Marks, Dean Sr."两种方法对比
两种工具都需要在项目本地编写数据生成模板或方法
根据一定的方式拦截 API 请求并指向本地生成的 Mock 数据
拦截的方法:
- 可以类似 Mock.js 的覆盖 API 调用对象
- 通过网络代理将后端域名指向本地目录
本地植入模拟数据生成器的方式从整体前后端工作的效率而言,并非最佳选择:
- 1.数据模板和 TypeScript 类型需要通过人工来保持一致,缺乏自动检验的功能 (基于 TypeScript 接口类型描述对象来自动生成模拟数据)
- 2.仍然需要后端编写完整的接口文档后才能开始编写数据生成逻辑
- 3.本地模拟数据规则本质上和接口文档脱离
- 2 和 3 (可以将接口文档和 Mock 数据服务以及接口测试工具结合在一起)
Mock 数据服务以及接口测试工具
YApi
Apifox
Apifox 解决了接口定义与 Mock 数据脱离的问题
- 1.在接口定义阶段,支持后端服务内定义的 OPEN API 风格的接口定义数据直接导入生成接口文档也支持在工具界面内填写字段创建,创建时支持设定返回值的 Mock 描述
- 2.在接口定义完成后,即可直接访问工具提供的 Mock 服务接口供前端调用
- 3.在后端接口开发过程中,可通过工具提供的接口调试功能进行开发调试
- 4.在接口完成后的任意时间点,支持接口的自动化测试来保证功能与描述的一致性
总结
讨论了 Mock 工具在前后端分离开发流程中起到的作用,以及选择 Mock 方案的一般考量标准
重点介绍了几种 Mock 工具:
- 专注于提供生成模拟数据这一核心能力的 Mock.js 和 Fakerojs
- 更平台化的内置 Mock 功能的 YApi 和 Apifox
5.编码效率:如何提高编写代码的效率?
5.1 通过脚手架生成一个项目的基础代码,免去了投入其中的时间
预处理语言:通过对应的预处理器将预处理语言在编译时转换为更完整的普通语法代码
- 预处理语言可以在原有语言的语法基础上提供更多新的内置功能及精简语法以便提高代码复用性和书写效率
- 三种目前主流的 CSS 预处理语言:Sass (2006) , Less (2009) 和 Stylus (2010)
- react-scripts 集成了 sass-loader ,vue-cli-service 同时支持这三种预处理器
- Bootstrap4、Antd 和 iView 使用 Less , ElementUl 使用 Sass
- 三种 CSS 的预处理语言都实现了:
- 变量 (Variables) 、嵌套 (Nesting) 、混合 (Mixins) 、运算 (Operators)父选择器引用 (Parent Reference) 、扩展 (Extend) 和大量内建函数 (Build-in Functions)
- 不同:
- Less 缺少自定义函数的功能 (可以使用 Mixins 结合 Guard 实现类似效果)
- Stylus 更有利于编写复杂的计算函数
- 语法对比:
- Sass 支持.scss 与 sass 两种文件格式
- Less 的整体语法更接近于.scss
- Stylus 同时支持类似.sass 的精简语法和普通 CSS 语法
- 安装方式:
- Sass 有两种 npm 编译安装包,基于 LibSass 的 node-sass 和基于 dart-sass 的 Sass
- 使用 webpack 构建,三种语言对应的预处理器是 sass-loader、less-loader、stvlus-loader 注意:sass-loader 和 stylus-loader 安装时需要同时安装独立编译包 Sass/node-sass 和 Stylussass-loader 处理 partial 文件中的资源路径时需要增加 resolve-url-loader(以及 sass-loader 中需要开启 sourceMap 参数) 以避免编译时的报错 stylus-loader 需要增加“resolve url”参数
- html 模板预处理生成语言
- Pug:Pug 的前身名叫 Jade (2010
- Pug 支持迭代、扩展 (Extend)(lteration) 、条件(Condition) 包含 (Include) 、混合(Mixins) 等逻辑功能
- 各个开发框架的支持:
- Vue 文件的 template 支持添加 lang="pug
- 在 vue-cli-service 的 webpack 配置中,内置了 pug-loader 作为预处理器
- 在 React 开发中,通过 babel 插件获得支持
- 其他:
- 具有精简语法功能的有--对应 JavaScript 的 CoffeeScript 和对应 JSON 的 YAML 等
- YAML 语言目前主要在一些配置上使用 例如 Dockerfile 和一些持续集成工具 (CI)的配置文件
代码生成:以达到在编写时自动生成代码的作用
1.使用 IDE (Integrated Development Environment,集成开发环境) 的相关预设功能帮助生成代码
- 功能主要包括:智能帮助、Snippet 和 Emmet 在 IDE 中会默认内置一些智能帮助功能,例如输入时的联想匹配、自动完成、类型提示、语法检查等
2.VSCode 的 Snippet 插件 一一 开发过程中用户在 IDE 内使用的可复用代码片段
自定义代码片段:sample.code-snippets
- json
{ "Typescript Interface":{ // 片段名称,下面描述不存在时显示在IDE智能提示中 "scope":"typescript", // 语言的作用域,不填写时默认对所有文件有效 "prefix":"tif", // 触发片段的输入前缀字符(输入第一个字符时即开始匹配) "body":[ // 片段内容 "interface ${1:IFName}{" // $1,$2..为片段生成后光标位置,通过tab切换 "t${2:key}: ${3:value}"// S{n:xx}的xx为占位文本 "}" ], "description": "output typescript interface" // 描述,显示在智能提示中 } } 任意.ts 文件中输入
tif + 回车即可生成下面的代码,同时兴标停留在 IFName 处- bash
interface IFName { key: value }
3.Emmet (前身为 Zen Coding) (VSCode 集成了)是一个面向各种编辑器的 web 开发插件用于高速编写和编辑结构化的代码
缩写代码块
- html
#main>h1#header+ol>.item-SS List ItemS]*3footer // 转换为 <div id="main"> <h1 id="header"></h1> <ol> <li class="item-01">List ltem1</li> <li class="item-02">List ltem2</li> <li class="item-03">List ltem3</li> </ol> <footer></footer> </div> CSS 缩写:支持常用属性和值的联合缩写
- css
m10 => margin:10px p100p => padding:100%? bdrsle => border-radius: lem; 自定义片段
- json
{ "html": { "snippets": { "dltd": "dl>(dt+dd)*2" } }, "css": { "snippets": { "wsnp": "white-space: no-wrap" } } }
5.2 上述工具的一般使用建议一 Html
- Html 语言作为一个组件的模板存在
- 组件模板中通常由框架提供了数据注入 (Interpolation) 以及循环、条件等语法
- 组件化本身解决了包含、混入等代码复用的问题
- 简化标签书写可以选择使用 Pug 语言,也可以使用 Emmet
- Emmet 取消缩进后作为替代需要通过关系标识符来作为连接
5.3 上述工具的一般使用建议一 CSS
- 使用预处理语言赋予的更强的代码抽象和组织能力,同时结合 Emmet 提供的属性缩写功能,能提升整体 CSS 开发的效率
- 项目中主要使用 UI 组件库来呈现界面,而只需要少量编写自定义样式的话,使用 Emmet 的优先级更高
- CSS 预处理语言的选择上,由于主要功能的相似性,团队统一选择其一即可
5.4 上述工具的一般使用建议一-JavaScript/TypeScript
JS/TS 的开发过程是非结构化的,提效工具主要是使用 Snippet
第三方扩展提供的常用语句的缩写,结合开发者自定义的常用片段,再次提升编码效率
5.5 总结
这一课时讨论了两种类型的提效工具: 预处理语言和代码生成工具
功能重叠的场景,例如 Pug 和 Emmet 中的 html 生成
6.团队工具:如何利用云开发提升团队开发效率?
6.1 软件开发环境的对比一一个人电脑开发环境
- 1.基础环境准备:准备开发环境所需设施,下载安装开发所需各种应用程序,调试各种配置文件,安装必要 IDE 插件并调试 IDE 配置项等
- 2.下载代码:将项目源代码从代码仓库 (例如 Git Repo) 中下载到个人电脑的开发目录下
- 3.安装项目依赖
- 4.运行开发服务
- 5.编码和调试
- 6.执行任务(Lint 检查、格式化检查、单元测试等)
6.2 软件开发环境的对比一一远程开发
将开发环境部署到远程服务器,通过个人电脑的 IDE(IntegratedDevelopment Environment ,集成开发环境)进行远程连接来进行开发的方式
远程开发优势
- 01.由远程的开发服务器来承载项目数据存储和运行计算的需求
- 02.减少了访问设备变更对于项目开发的影响
远程开发的主要问题
- 需要申请单独的开发机资源
- 新申请的开发机需要人工进行基础环境的准备工作
- 将开发机单独用于远程开发,资源分配上可能存在资源利用不充分的问题
6.3 云开发
- 1.云开发模式是将开发环境托管,由远程开发服务器变更为云服务
- 2.个人电脑通过 IDE 或云服务提供的浏览器界面访问云端工作区进行开发
云开发优势
- 1.提升开发环境准备的效率
- 2.简化使用流程
- 3.提升团队协作效率
- 4.有利于资源利用率的提升和硬件资产成本的降低
6.4 典型的云开发产品
| 产品 | 厂商 | 基础 IDE | IDE 类型 | 代码托管方式 |
|---|---|---|---|---|
| VS Codespace | 微软 | VS Code | Web/VS/VSC | 云端 (Asure) /自维护 |
| Gitpod | Eclipse | Theia | Web/Desktop | 云端/自维护(限制用户数量) |
| CloudIDE | 阿里云 | KAITIAN IDE | Web | 云端 |
| Cloud Studio | Coding.net(腾讯云) | VS Code | Web | 云端 (5 个工作空间) |
| Cloud9 | AWS | Cloud9 | Web | 云端(AWS) |
微软: Visual Studio Codespace
- 1.支持三种访问客户端:VS Code,Visual StudioIDE,Web
- 2.提供收费的云托管(Azure) 环境与免费的自维护环境两种服务方式
- 3.内置多人协作工具 Live Share 和 AI 智能代码提示功能 InteliCode
- 5.自定义个性化配置,定制环境中各类配置文件
- 4.自定义环境基础配置,可定制化开发环境基础设施
Eclipse: Theia
Eclipse Theia(以下简称 Theia) 的定位是以 NodeJS 和 TS 为技术栈开发的云端和桌面端的 IDE 基础架
2018 年发布了对应的 Web 端 IDE 产品 Gitpod
Theia 和 VS Code 的技术相同点
- 1.编辑器核心都基于 Monaco Editor
- 2.都支持 Language Server Protocol (LSP)
- 3.都支持 VSCode 的插件体系
- 4.都支持 DebugAdepterProtocol(DAP)
与 VS Code 相比,Theia 的不同之处在于
- 1.从一开始就被设计成同时运行于桌面和云端
- 2.架构上更模块化,更易于自定义
- 3.由厂商中立的开源基金会开发维护
- 4.开发独立的 WebIDE 是云开发产品的首选,但 Thiea 有开源可定制化的版本
6.5 云开发模式的技术要素
WebIDE
- 便于平台化定制
- 在团队使用时可通过定制 WebIDE 来实现通用的功能扩展和升级
- 流程体验上更平滑
- 通过和代码仓库以及 CI/CD 工具的对接,可以在很多流程节点上做到平滑的体验
容器化
- 1.每个用户的每个项目创建独立的工作空间
- 2.便于团队成员维护相同项目时提升环境创建效率
- 3.有利于提升资源利用率,同时环境搭建更便捷
对接其他云服务
- 与其他上下游服务的对接,例如在阿里云的 CloudIDE 产品中,包含了一键部署等功能
6.6 云开发的效率提升应用场景一一项目篇
- 加速创建新项目:在云开发模式下,可以将包含依赖安装的项目模板存储为镜像
- 项目依赖版本统一:免去安装依赖,以达到各环境下依赖版本的统一管理,同时也提升了各环境的处理效率
6.7 云开发的效率提升应用场景一一工具篇
- 开箱即用的开发环境:可以将开发所需的不同基础环境以及各种应用程序制作成开发环境镜像,供开发者自由选择
- 自定义辅助工具的快速共享和共建:辅助工具都可以在云平台的模式下快速落地,集成到各开发者的工作空间中
6.8 云开发的效率提升应用场景一一流程篇
- 连接代码仓库与开发环境:从代码仓库的任意 commit 直连创建云端工作空间或进入已有工作空间
- 连接 Pipeline 与开发环境:通过对应的提交信息,直连创建临时修复用途的项目工作空间
6.9 使用云开发的注意点
代码安全问题
- 在代码仓库中设置具体项目的访问权限
- 在使用云开发模式时应当首选支持内部部署的云服务或搭建自维护的云服务
服务搭建与维护
- 对于大厂,搭建自维护的云开发服务
- 对于中小规模的技术团队,购买使用一些支持内部部署的现有云开发服务
服务降级与备份
- 云开发模式下将开发环境与工作代码都存储于云端需要考虑当云端服务异常时的降级策略
6.10 总结
- 介绍了云开发的概念,以及它能解决哪些方面的问题
- 了解了几款有代表性的云产品,重点关注的是 VS Code 系的 Codespace 产品如果对定制 WebIDE 感兴趣,从 Theia 入手会较好
- 讨论了云开发这种模式的一般技术要素,以及使用它所能带来的
- 几个比较明确的效率提升场景几个新技术对应的风险点
7.低代码工具:如何用更少的代码实现更灵活的需求?
7.1 什么是低代码开发?
低代码开发(Low-Code Development 简称 LCD)
- 开发者主要通过图形化用户界面和配置来创建应用软件
低代码开发平台(Low-CodeDevelopment Platform 简称 LCDP)
低代码开发模式的开发者通过平台的功能和约束来实现专业代码的产出
1.在高度定制化的场景中,基于经验总结,找到那些相对固定的产品形态,开放少量的编辑入口,让非专业开发者也能使用
2.尝试以组件化和数据绑定为基础,通过抽象语法或 IDE 来实现自由度更高、交互复杂度上限更高的页面搭建流程
7.2 低代码开发的典型应用场景
低代码开发的一类典型应用场景是在 PC 端中后台系统的开发流程中
- 可以基于统一的 UI 组件库来实现搭建,通过组件拖拽组合即可灵活组织成不同形态功能的页面
- 中后台系统涉及到数据的增删改查,需要有一定的编码调试能力,不适用无代码开发模式
以中后台为开发目标,可以分为以下两种:
1.基于编写 JSON 的开发方式
- 01 一个项目的前端部分本质上呈现的是通过路由连接的不同页面
- 02 每一个页面的内容在浏览器中,最终都归结为 DOM 语法树(DOM Tree) +样式 (Style) +动态交互逻辑 (Dynamic Logic)
- 03 页面的内容可以定义为,组件树(Component Tree) +动态交互逻辑(Dynamic Logic)
基于 JSON-Schema 的低代码开发的切入逻辑
- 1.在特定场景下,例如开发中后台增删改查页面时,大部分前端手动编写的代码是模式化的
- 2.页面组件结构模板和相应数据模型的代码组织,可以替换为更高效的 JSON 语法树描述
- 3.通过制定用于编写的 JSON 语法图式(JSON Schema) ,以及封装能够渲染对应 JSON 语法树的运行时工具集,可以提升开发效率,降低开发技术要求
代码例子
编写 JSON 开发的高效性
- 由于只用编写 JSON ,隐藏了前端开发所需的大量技术细节 (构建、框架等等) ,降低了对开发人员的编码要求
- 大量的辅助代码集成在工具内部,整体上减少了需要生成的代码量
- 可以对中后台系统所使用的常用业务组件进行抽象,然后以示例页面或示例组件的方式,供用户选择
编写 JSON 开发的缺点
- 输入效率
- 学习记忆成本
- 复用性和可维护性
- 问题排查难度增加
2.基于可视化操作平台的开发方式
可视化操作平台的基本使用方式
- 1.首先,在左侧面板中选择组件
- 2.然后,拖入中间预览区域,并放置到合适的容器块内
- 3.最后,试右侧面板中新移入的组件属性
- 4.调试完成后,进行下一个组件的循环操作直到整个页面搭建完成
可视化操作平台的生产效率影响因素
编写 JSON 的产出效率更大程度上取决于编写页面的开发者的技术熟练度
- 平台的功能完备性直接决定了用户产出的上限
- 平台的逻辑自洽性决定了用户产出的质量
- 平台提供的交互易用性决定了用户的产出效率
低代码开发的产品
- 商用的产品:例如 Kony、OutSystems、Mendix、Appian、iVX(国内)等
- 开源类的产品:例如阿里飞冰、百度 Amis、贝壳河图 Vvvebjs、react-visual-editor 等
7.3 总结
介绍了低代码开发的概念和它的基本应用场景
了解了低代码开发的两种基本开发模式:基于编写 JSON 的方式和基于可视化操作平台的方式
- 基于编写 JSON 的方式:降低了使用者的技术要求提升了开发的效率,但是在一些方面仍然不甚理想
- 基于可视化操作平台的方式:解决了编写 JSON 模式下的一些问题,但搭建一个功能完备、使用逻辑自洽和交互性良好的平台并非易事
低代码工具主要面向什么样的用户群体呢
具有一定技术基础的开发人员:使用组件开发模式的人
8.无代码工具:如何做到不写代码就能高效交付?
8.1 无代码开发模式的出现
- 需求量大且更新频率快的小型项目
- 开发人员成本昂贵,供不应求
- 项目流程模式基本相同但又具有一定的定制性
- 非互联网企业缺少技术资源
8.2 无代码开发介绍
无代码开发
(No-Code Development/ Codeless Development) 指通过非手写代码工具来产出代码的方式
无代码开发平台
(No-Code Development Platform,NCDP)
8.3 无代码开发和低代码开发的区别
| 区别维度 | 低代码开发 | 无代码开发 (面向非开发) | 无代码开发 (面向准开发) |
|---|---|---|---|
| 目标人群 | 主要面向有一定技术基础的开发人员 | 主要面向非开发岗位人员 (例如运营人员,设计人员) | 主要面向准开发人员 (对开发思维的需求随项目难度递增) |
| 目标产品 | 主要为 B 端中后台 | 主要为 C 端活动或 H5 | 结合前两者 |
| 开发模式 | 编写 JSON/操作图形化交互平台(偏重前端) | 操作图形化交互平台 (偏重前) | 操作图形化交互平台(前端到后端) |
| 基础设施 | 通用的组件库与渲染流程 | 典型的页面/项目模板,以及与视觉呈现相关的组件 | 前后端组件 |
| 可自由定制的内容 | 组件的选择、布局、属性、数据交互 | 可视化数据 (文本、媒体、动画等)的编辑 | 前端可视化数据,后端数据与逻辑功能等 |
| 数据接口 | 通常由独立后端单独开发提供 | 无数据接口,或通常由平台方提供标准化的接口 | 基于云基础设施的数据功能 |
| 部署 | 可单独部署 | 通常由平台方提供云服务部署 | 通常由平台方提供云服务部署 |
8.4 典型产品分析
面向非开发人员的无代码开发产品
- 设计目标是将一些固定类型的项目生产流程由代码开发转变为操作图形化交互工具
企业内部的定制化搭建平台
- 1.产品确定活动流程,交付产品文档与原型
- 2.设计师设计页面,交付设计稿
- 3.前端工程师开发活动的前端代码
- 4.后端工程师开发活动的后端代码
- 5.前后端联调后交付测试
- 6.测试通过后部署上线
针对同一类型的活动项目前后端工程师可以开发出对应的可视化活动搭建平台
- 01 选择活动类型并预览效果的功能
- 02 文本、图片、活动金额、上下线时间等元素替换功能
- 03 数据统计等辅助模块
外部无代码搭建平台
百度 H5 生成平台
- 01 场景类型固定
- 02 设计模板丰富
- 03 定制化功能多样
- 04 后端功能较少
- 05 部署在云端
- 06 使用人群细化
面向准开发人员的无代码开发产品一一更为多样化的应用场景
面向准开发人员的无代码开发产品一一目标人群的变化
- 1.能够吸引更多有产品思维但缺少实际开发经验的个人或缺少开发资源的团队尝试使用
- 2.开发一个复杂的项目,对开发人员的要求不只体现在代码能力方面,还需要开发人员对产品全栈架构与交互逻辑层面有一定的认识和理解
- 3.使用者对这类全新的开发工具和流程的开发经验的掌握,很难迁移到其他开发工具和流程中
8.5 总结
对比了低代码开发和无代码开发两种开发模式不同维度的区别
介绍了无代码开发的两种不同方向: 面向非开发人员的产品 与 面向准开发人员的产品
面向非开发人员的无代码
在企业内部
- 将一些频率高的常用简易开发流程,固化为无代码开发产品,供运营或其他岗位人员使用
在企业外部
- 有免费或收费的无代码平台,将开发工具提供给缺乏技术资源的企业与个人
- 设计师可以制作自己的设计模板提供给用户
面向准开发人员的无代码产品
- 具有更广泛的使用场景
- 通过提供后端数据与逻辑的描述功能,用户可以通过 IDE 开发出具备前后端数据交互的复杂应用,近一步减少与普通代码开发的功能边界的差距
二、构建效率
1.构建总览:前端构建工具的演进
1.1 前端开发语言
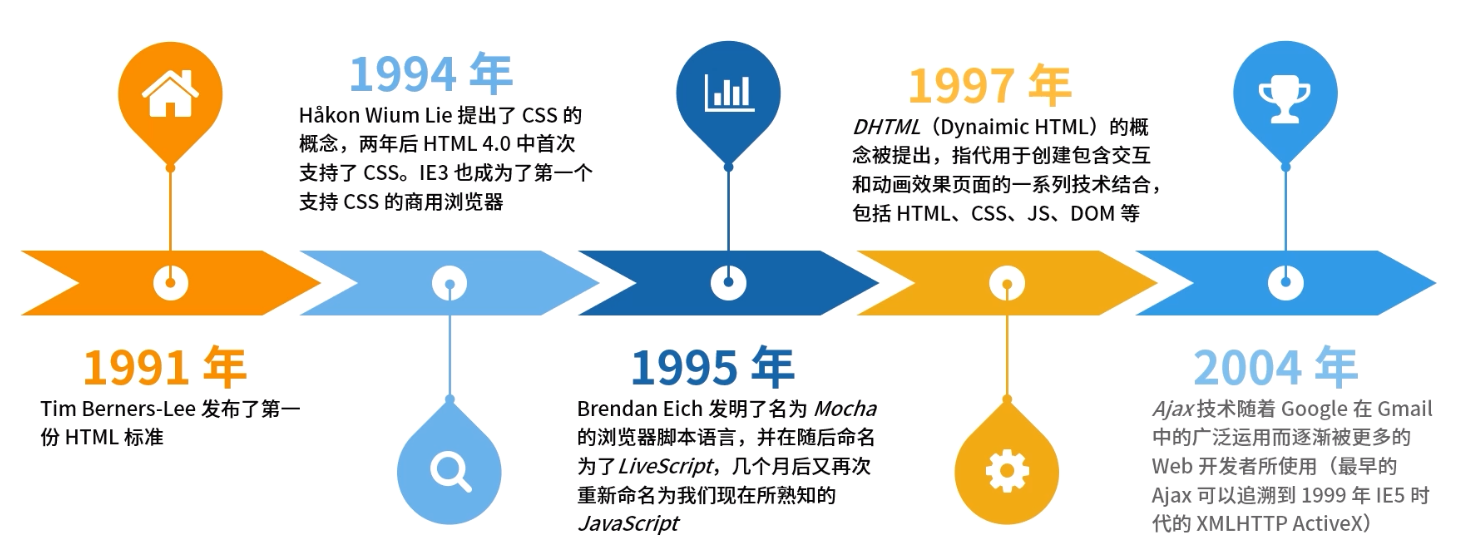
1.2 前端开发工具
1.文件压缩和合并工具
- 2001 年:Douglas Crockfold 发布了 JSMin 工具,用于去除 JS 代码中的注释和空格
- 2004 年:DaveShea 在他的文章中参考早期游戏开发中使用的 Sprite 图方案,提出了 CsS Sprite 的概念,即将多张小图合成为一张大图,然后通过 CSS 控制在不同元素中使用图片的局部区域,从而减少网络请求,提升网页性能
- 2006 年:Yahoo 发布了 YUI 库,其中包含了基于 Java 的代码压缩工具 YU Compressor
- 2009 年:Google 发布了 Closure Toolkit.其中包含的 Closure Compiler 提供了比 YUICompressor 更多的代码优化功能,并支持 Source Map 和多文件合并
- 2010 年:Mihai Bazon 发布了压缩工具 UglifyJS,并在 2012 年的升级版本 UglifyJS2 中增加了对 Source Map 的支持
文件压缩工具
从 JSMin、YUICompressor 到 ClosureCompiler 和 UglifyJS,压缩与优化的性能不断完善
在合并工具方面
CSS Sprite 技术解决了网页中大量素材图片的加载性能问题。代码文件的合并,可以在命令行中通过输出到文件手动完成; 在 Closure Compiler 工具中包含了将多个文件合并为一个的参数
2.包管理工具
- 2009:Ryan Dahl 发布了第一个版本的 Node.js
- 2010:Node.is 核心开发人员 lsaacZSchlueter 编写了对应环境的包管理工具 npm
- 2012:Twitter 发布了名为 Bower 的前端依赖包管理工具
- 2016:Facebook 发布了 npmregistry 的兼容客户端 Yarn
- pnpm
许多原先基于其他语言开发的工具包如今可以通过 NodeJS 来实现,并通过 npm (Node Package Manager,即 node 包管理器)来安装使用
安装到本地的依赖包在前端项目中如何引用开始受到关注
npm 工具的缺点
...
yarn 工具的优缺点
...
pnpm 工具的优缺点
...
3.任务式构建工具
- 2012 年:Eric Schoffstall 发布了流式的构建工具 Gulp
- 2013 年:BenAlman 发布了基于任务的构建工具 Grunt
Grunt 和 Gulp 两种任务式的构建工具的基本组成
- 配置文件(Gruntfile/Gulpfile)
- 核心的处理工具(grunt-cli/gulp-cli)
- 常用的任务插件(clean、Watch、Copy、Concat、Uglify、CssMin、Spritesmith.......)
Grunt vs Gulp
- 读写速度:在读写速度上 Gulp 要快于 Grunt
- 社区使用规模:Gulp 周下载量为 1,200,000+,约是 Grunt 的两倍。Grunt 社区提供超过 6000 个不同功能的插件,Gulp 社区插件数量是 4000 多个
- 配置文件的易用性:使用 pipe 函数描述任务处理过程的方式通常更配置文件易于阅读,但编写时需要对数据流有更深入的理解
4.模块化:模块定义与模块化的构建工具
- 2009 年:Kevin Dangoor 发起了 ServerJS 项目,后更名为 CommonJS,其目标是指定浏览器外的 JSAPI 规范以及模块规范 Modules/1.0。这一规范也成为同年发布的 NodeJS 中的模块定义的参照规范
- 2011 年:RequireJS 1.0 版本发布作为客户端的模块加载器提供了异步加载模块的能力。作者在之后提交了 CommonJS 的 Module/Transfer/C 提案,这一提案最终发展为了独立的 AMD 规范
- 2013 年:面向浏览器端模块的打包工具 Browserify 发布
- 2014 年:跨平台的前后端兼容的模块化定义语法 UMD 发布
- 2014 年:Sebastian McKenzie 发布了将 ES6 语法转换为 ES5 语法的工具 6to5,并在之后更名为 Babel
- 2014 年:Guy Bedford 对外发布了 SystemJS 和 jspm 工具,用于简化模块加载和处理包管理
- 2014 年:打包工具 Webpack 发布了第一个稳定版本
- 2015 年:ES6(ES2015) 规范正式发布,第一次从语言规范上定义了 JS 中的模块化
- 2015 年:Rich Harris 发布的 Rollup 项目基于 ES6 模块化,提供了 Treeshaking 的功能
模块化的不同规范--CommonJS
- 服务标识:一个模块即是一个 JS 文件,代码中自带 module 指向当前模块对象自带 exports=module.exports,且 exports 只能是对象,用于添加导出的属性和方法自带 require 方法用于引用其他模块
- 模块引用:通过引用 require()函数来实现模块的引用,参数可以是相对路径也可以是绝对路径在绝对路径的情况下,会按照 node modules 规则递归查找
- 模块加载:require()的执行过程是同步的,执行时即进入到被依赖模块的执行上下文中,执行完毕后再执行依赖模块的后续代码
模块化的不同规范--AMD
CommonJS 的 Modules/1.0 规范只能用于服务端,不能用于浏览器端
- 模块定义:通过 define(id?,dependencies?,factory)函数定义模块,id 为模块标识,dependencies 为依赖的模块,factory 为工厂函数
- 模块引用:最早需要通过 require([id],callback)方式引用,也支持类似 CommonJS 的 var a=require('a)的写法
模块化的不同规范--UMD
- UMD 本质上是兼容 CommonJS 与 AMD 这两种规范的代码语法糖通过判断执行上下文中是否包含 define 或 module 来包装模块代码适用于需要跨前后端的模块
模块化的不同规范--ES Module
模块定义:
- 通过 export 关键字导出任意个数的变量
- 通过 export default 导出,一个模块中只能包含一个 default 的导出类型
模块引用:
通过 import 关键字引用其他模块
- 静态引用格式为 importimportClause from ModuleSpecifierimport 表达式需要写在文件最外层上下文中
- 动态引用的方式是 import(),返回 promise 对象
5.模块化的构建工具
- Browserify:目标是让 CommonJS 风格的代码也运行在浏览器端
- RequireJS:核心功能是支持 AMD 风格的模块化代码运行
- Rollup:实现了 Tree Shaking 功能,以及天然支持 ES6 模块的打包
- Babel:定位是 Transformer,即语法转换器,它承担着将 ES6、JSX 等语法转换为 ES5 语法的核心功能
- SystemJS:兼容各种模块化规范的运行时工具
- Webpack:兼容各种模块化规范的标识方法;将模块化的概念延伸到其他类型的文件中
1.3 总结
前端构建工具的演进
- 01:单独功能的压缩与合并工具
- 02:NodeJS 与包管理工具
- 03:任务式构建工具的发展
- 04:模块化概念与工具
2.流程分解:Webpack 的完整构建流程
01:通过 Webpack 的源码来了解具体函数执行的逻辑
2.1 Webpack 的基本工作流程
// 第一种: 基于命令行的方式
webpack --config webpack.config.js
// 第二种:基于代码的方式
var webpack = require('webpack');
var config = require('./webpack.config');
webpack(config, (err, stats) => {});- 1.创建编译器 Compiler 实例
- 2.根据 Webpack 参数加载参数中的插件以及程序内置插件
- 3.执行编译流程:创建编译过程 Compilation 实例,从入口递归添加与构建模块,模块构建完成后冻结模块,并进行优化
- 4.构建与优化过程结束后提交产物,将产物内容写到输出文件中
2.1.1.webpack.js 中的基本流程
const webpack = (options, callback) => {
options = ... // 处理options默认值
let compiler = new Compiler(options.context)
// 处理参数中的插件等
// ...
// 分析参数,加载各内部插件
compiler.options = new WebpackOptionsApply().process(options, compiler);
if (callback){
// ...
compiler.run(callback)
}
return compiler
}2.1.2.Compiler.js 中的基本流程
readRecords
- 读取构建记录,用于分包缓存优化,在未设置 recordsPath 时直接返回
complie 的主要构建过程
- newCompilationParams
- 创建 NormalModule 和 ContextModule 的工厂实例,用于创建后续模块实例
- newCompilation
- 创建编译过程 Compilation 实例,传入上一步的两个工厂实例作为参数
- compiler.hooks.make.callAsync
- 触发 make 的 Hook,执行所有监听 make 的插件
- compilation.seal
- 编译过程的 seal 方法
- compilation.finish
- 编译过程实例的 finish 方法,触发相应的 Hook 并报告构建模块的错误和警告
emitAssets
- 调用 compilation.getAssets(),将产物内容写入输出文件中
emitRecords
- 对应第一步的 readRecords,用于写入构建记录,在未设置 recordsPath 时直接返回
addEntry
- 从 entry 开始递归添加和构建模块
seal
- 冻结模块,进行一系列优化以及触发各优化阶段的 Hooks
02:通过 Webpack 对外暴露的声明周期 Hooks,理解整体流程的阶段划分
读懂 Webpack 的生命周期
Compiler 和 Compilation 都扩展自 Tapable 类用于实现工作流程中的生命周期划分,其中所暴露出来的生命周期节点称为 Hook (俗称子)
Webpack 中的插件
class HelloWorldPlugin {
apply(compiler) {
compiler.hooks.run.tap("HelloWorldPlugin", (compilation) => {
console.log("hello world");
});
}
}
module.exports = HelloWorldPlugin;Hook 的使用方式
lib/Compiler.js
this.hooks = {
// ...
make: new SyncHook(['compilation''params']), // 1.定义Hook..
// ...
}
// ...
this.hooks.compilation.call(compilation, params); // 4.调用Hook
// ...lib/dependencies/CommonJsPlugin.js
// 2.在插件中注册Hook
compiler.hooks.compilation.tap("CommonJSPlugin", (compilation, { contextModuleFactory.normalModuleFactory }) => {
// ...
}lib/WebpackOptionsApply.js
// 3.生成插件实例,运行apply方法
new CommonJsPlugin(options.module).apply(compiler);Compiler Hooks
构建器实例的生命周期
- 初始化阶段
- environment、afterEnvironment 在创建完 compiler 实例且执行了配置内定义的插件的 apply 方法后触发
- entryOption、afterPlugins、afterResolvers 在 WebpackOptionsApply.js 中,这 3 个 Hooks 分别在执行 EntryOptions 插件和其他 Webpack 内置插件,以及解析了 resolver 配置后触发
- 构建过程阶段
- normalModuleFactory、 contextModuleFactory 在两类模块工厂创建后触发
- beforeRun、run、watchRun、beforeCompile、compile、thisCompilation.compilation、make、afterCompile 在运行构建过程中触发
- 产物生成阶段
- shouldEmit、emit、assetEmitted、afterEmit 在两类模块工厂创建后触发
- failed、done 在达到最终结果状态时触发
Compilation Hooks 一构建阶段
01:addEntry、failedEntry、succeedEntry
在添加入口和添加入口结束时触发 (Webpack 5 中移除)
02:buildModule、rebuildModule、finishRebuildingModule、failedModule、succeedModule
在构建单个模块时触发
03:finishModules
在所有模块构建完成后触发
Compilation Hooks 一一优化阶段
- 1.优化依赖项
- 2.生成 Chunk
- 3.优化 Module
- 4.优化 chunk
- 5.优化 Tree
- 6.优化 ChunkModules
- 7.生成 Module lds
- 8.生成 Chunklds
- 9.生成 Hash
- 10.生成 ModuleAssets
- 11.生成 ChunkAssets
- 12.优化 Assets
seal、needAdditionalSeal、 unseal、afterSeal:分别在 seal 函数的起始和结束的位置触发
optimizeDependencies、afterOptimizeDependencies:触发优化依赖的插件执行,例如 FlagDependencyUsagePlugin
beforeChunks、afterChunks:分别在生成 Chunks 的过程的前后触发
Optimize:在生成 chunks 之后,开始执行优化处理的阶段触发
optimizeModule、afterOptimizeModule:在优化模块过程的前后触发
optimizeChunks、afterOptimizeChunks:在优化 Chunk 过程的前后触发,用于 Tree Shaking
optimizeTree、afterOptimizeTree:在优化模块和 chunk 过程的前后触发
optimizeChunkModules、afterOptimizeChunkModules:在优化 chunkModules 的过程前后触发
shouldRecord、recordModules、recordChunks、recordHash:在 shouldRecord 返回为 true 的情况下,依次触发 recordModules、recordChunks、recordHash
reviveModules、beforeModulelds、modulelds、optimizeModulelds、afterOptimizeModuleld:在生成模块 ld 过程的前后触发
reviveChunks、beforeChunklds、optimizeChunklds、afterOptimizeChunklds:在生成 Chunkid 过程的前后触发 beforeHash、afterHash:在生成模块与 Chunk 的 hash 过程的前后触发
beforeModuleAssets、moduleAsset:在生成模块产物数据过程的前后触发 shouldGenerateChunkAssets、beforeChunkAssets、chunkAsset:在创建 Chunk 产物数据过程的前后触发
additionalAssets、optimizeChunkAssets、afterOptimizeChunkAssets、optimizeAssets、afterOptimizeAssets:在优化产物过程的前后触发
代码实践:编写一个简单的统计插件
class SamplePlugin {
apply(compiler){
var start = Date.now();
var statsHooks = ['environment', 'entryOption', 'afterPlugins', 'compile'];
var statsAsyncHooks = [ 'beforeRun', 'beforeCompile', 'make', 'afterCompile', 'emit', 'done' ];
}
statsHooks.forEach((hookName) => {
compiler.hooks[hookNamel].tap('Sample Plugin', () => {
console.log(`Compiler Hook ${hookName}, Time: ${Date.now() - start}ms`)
})
})
// ...
}
module.exports = SamplePlugin;执行插件:webpack --config webpack.config.js
Webpack 社区中有一些较成熟的统计插件,例如 speed-measure-webpack-plugin 等
总结
- 1.通过对三个源码文件的分析,让你对执行构建命令后的内部流程有一个基本概念
- 2.讨论了 Compiler 和 Compilation 工作流程中的生命周期 Hooks,以及插件的基本工作方式
- 3.编写了一个简单的统计插件
3.编译提效:如何为 Webpack 编译阶段提速?
在 Compiler 和 Compilation 的各生命周期阶段里通常耗时最长的分别是哪个阶段呢?
- 对于 Compiler 实例耗时最长的是生成编译过程实例后的 make 阶段
- 对于 Compilation 实例编译模块和后续优化阶段的生成产物并压缩代码的过程都比较耗时
编译模块阶段提速
优化前的准本工作
- 准备基于产物内容的分析工具:例如 speed-measure-webpack-plugin
- 准备基于时间的分析工具:使用 webpack-bundle-analyzer 分析产物内容
提升这一阶段的构建效率,大致分为三个方向
- 减少执行编译的模块
- 提升单个模块构建的速度
- 并行构建以提升总体效率
1.减少执行构建的模块
提升编译模块阶段效率的第一个方向。减少执行编译的模块
1.lgnorePlugin
new webpack.IgnorePlugin({
resourceRegExp: /^\.\/locale$/,
contextRegExp: /moment$/,
}),2.按需引入类库模块
- Tree Shaking 需要相应导入的依赖包使用 ES6 模块化,而 lodash 还是基于 CommonJS 需要替换为 lodash-es 才能生效
- 相应的操作是在优化阶段进行的,Tree Shaking 并不能减少模块编译阶段的构建时间
3.DllPlugin
略
4.Externals
- 1.Webpack 的配置方面,externals 更简单,DllPlugin 需要独立的配置文件
- 2.DllPlugin 包含了依赖包的独立构建流程,externals 配置中通常使用已传入 CDN 的依赖包
- 3.externals 配置的依赖包需要单独指定依赖模块的加载方式:全局对象、CommonJS、AMD 等
- 4.在引用依赖包的子模块时,DllPlugin 无须更改,而 externals 则会将子模块打入项目包中
2.提升单个模块构建的速度
提升编译阶段效率的第二个方向在保持构建模块数量不变的情况下,提升单个模块构建的速度
1.include/exclude
2.noParse
3.Source Map
- 对于生产环境的代码构建而言,会根据项目实际情况判断是否开启 Source Map 在
- 开启 Source Map 的情况下,优先选择与源文件分离的类型
- 有条件也可以配合错误监控系统,将 Source Map 的构建和使用在线下监控后台中进行
4.TypeScript 编译优化
- 由于 ts-loader 默认在编译前进行类型检查,因此编译时间往往比较慢
- 通过加上配置项 transpileOnly: true,可以在编译时忽略类型检查
- babel-loader 需要单独安装 @babel/preset-typescript 来支持编译 TS
5.Resolve
- resolve.modules:指定查找模块的目录范围
- resolve.extensions:指定查找模块的文件类型范围
- resolve.mainFields:指定查找模块的 package.json 中主文件的属性名
- resolve.symlinks:指定在查找模块时是否处理软连接
3.并行构建以提升总体效率
第三个编译阶段提效的方向使用并行的方式来提升构建的效率
HappyPack 与 thread-loader
parallel-webpack
总结
- 以减少执行构建的模块数量为目的的方向
- 以提升单个模块构建速度为目的的方向
- 通过并行构建以提升整体构建效率的方向
4.打包提效:如何为 Webpack 打包阶段提速?
准备分析工具
WebpackTimingPlugin.js
const lifeHooks = [
{
name: "optimizeDependencies",
start: "optimizeDependencies",
end: "afterOptimizeDependencies",
},
{ name: "createChunks", start: "beforeChunks", end: "afterChunks" },
// ...
];
// ...
let startTime;
compilation.hooks[start].tap(PluginName, () => {
startTime = Date.now();
});
compilation.hooks[end].tap(PluginName, () => {
const cost = Date.now() - startTime;
console.log(`[Step ${name}] costs: ${chalk.red(cost)}ms`);
});优化阶段效率提升的整体分析
- 1.优化依赖项
- 2.生成 Chunk
- 3.优化 Module
- 4.优化 chunk
- 5.优化 Tree
- 6.优化 ChunkModules
- 7.生成 Module lds
- 8.生成 Chunklds
- 9.生成 Hash
- 10.生成 ModuleAssets
- 11.生成 ChunkAssets
- 12.优化 Assets
以提升当前任务工作效率为目标的方案
针对某些任务,使用效率更高的工具或配置项,从而提升当前任务的工作效率
- 生成 ChunkAssets:即根据 chunk 信息生成 chunk 的产物代码
- 优化 Assets:即压缩 chunk 产物代码
第一个任务主要在 Webpack 引擎内部的模块中处理
面向 JS 的压缩工具
Webpack 4 中内置了 TerserWebpackPlugin 作为默认的 JS 压缩工具
之前的版本则需要在项目配置中单独引入,早期主要使用的是 UglifyJSWebpackPlugin
| 源文件 | 使用 Terser 的整体构建时间 | 使用 UglifyJS 的整体构建时间 |
|---|---|---|
| example-lodash.js | 2427ms | 3060ms |
| example-moment.js | 4730ms | 5010ms |
| example-antd.js | 16518ms | 19286ms |
Terser 和 UglifyJS 插件中的效率优化
Terser 原本是 Fork 自 uglify-es 的项目,其绝大部分的 API 和参数都与 uglify-es 和 uglify-js@3 兼容
- Cache 选项:默认开启,使用缓存能够极大程度上提升再次构建时的工作效率
- Parallel 选项:默认开启,并发选项在大多数情况下能够提升该插件的工作效率,但具体提升的程度则因项目而异
- terserOptions 选项:即 Terser 工具中的 minify 选项集合。这些选项是对具体压缩处理过程产生影响的配置项
// 源代码./src/example-terser-opts.js
function HelloWorld() {
const foo = '1234';
console.log(HelloWorld, foo);
}
HelloWorld();
// 默认配置项compress = {},mangle=true的压缩后代码
function(e, t){!function e(){console.log(e,"1234")}()};
// compress=false的压缩后代码
function(e,r){ function t(){ var e="1234"; console.log(t,e)}t()};
// mangle=false的压缩代码
function(module,exports) { !function HelloWorld(){console.log(HelloWorld,"1234")}()};
// compress=false,mangle=false的压缩后代码
function(module,exports){ function HelloWorld() { var foo="1234"; console.log(HelloWorld,foo)} HelloWorld()};| compress 参数 | mangle 参数 | 产物代码大小(MB) | 压缩阶段耗时 ms |
|---|---|---|---|
| {} (默认) | true (默认) | 1.45 | 4008 |
| false | true | 1.5 | 1794 |
| {} | false | 1.68 | 3258 |
面向 CSS 的压缩工具
- OptimizeCSSAssetsPlugin (在 Create-React-App 中使用)
- OptimizeCSSNanoPlugin (在 VUE-CLI 中使用)
- CSSMinimizerWebpackPlugin (2020 年 Webpack 社区新发布的 CSS 压缩插件)
| 插件名称 | 构建时间 (ms) | 带 sourceMap 的构建时间(ms) |
|---|---|---|
| OptmizeCSSAssetsPlugin | 1820 | 1936 |
| OptimizeCSSNanoPlugin | 1813 | 2059 |
| CSSMinimizerWebpackPlugin | 1938(*1645) | 2540 (-) |
以提升后续环节工作效率为目标的方案
提升特定任务的优化效果,以减少传递给下一任务的数据量,从而提升后续环节的工作效率
Split Chunks (分包)
Split chunks (分包) 是指在 chunk 生成之后将原先以入口点来划分的 chunks 根据一定的规则分离出子 chunk 的过程
./src/example-split1.js
import { slice } from 'lodash';
console.log('slice' slice([1])./src/example-split2.js
import { join } from "lodash";
console.log("join", join([1], [2]));./webpack.split.config.js
// ...
optimization: {
splitChunks: {
chunks: "all";
}
}
// ...对于示例中多入口静态引用相同依赖包的情况,设置为 chunks: 'all'
SplitChunksPlugin 的工作阶段是在 optimizeChunks 阶段
压缩代码是在 optimizeChunkAssets 阶段,从而起到提升后续环节工作效率的作用
| 执行语句 | 压缩代码阶段时长 | 产物大小 |
|---|---|---|
| import_from 'lodash' // 不调用 | 1013ms | 72.2KB |
| import_from 'lodash-es' / / 不调用 | 40ms | 951 bytes |
| importfrom 'lodash' console.log(.slice) | 1012ms | 72.2KB |
| importfrom 'lodash-es' console.log(.slice) | 1036ms | 85.5KB |
| import * as_from 'lodash-es' console.log(.slice) | 99ms | 3.32KB |
| import {slice} from 'lodash' console.log(slice) | 1036ms | 72.2KB |
| import {slice} from 'lodash-es' console.log(slice) | 97ms | 3.32KB |
| // use babel & rule.sideEffects: true import_from 'lodash' // 不调用 | 1039ms | 85.5KB |
| // optimizations.sideEffects: false import_from 'lodash' // 不调用 | 1029ms | 85.5KB |
| // use babel & babel-preset-env import_from 'lodash-es' // 不调用 | 2008ms (构建总时长 6478ms) | 275KB |
| // use babel & @babel/preset-env import_from 'lodash-es' // 不调用 | 39ms (构建总时长 3223ms) | 951 bytes |
Tree Shaking(摇树)
1.ES6 模块
只有 ES6 类型的模块才能进行 Tree Shaking
CommonJS 类型的模块 lodash,需要依赖第三方提供的插件才能实现动态删除无效代码
ES6 风格的模块 lodash-es,则可以进行 Tree Shaking 优化
2.引入方式
以 default 方式引入的模块,无法被 Tree Shaking
引入单个导出对象的方式,使用 import * as xxx 的语法,还是 import{xxx}的语法
都可以进行 Tree Shaking
3.sideEffects
在 Webpack 4 中,会根据依赖模块 package.json 中的 sideEffects 属性,来确认对应的依赖包代码是否会产生副作用
rule.sideEffects (默认为 false) :指代在要处理的模块中是否有副作用
optimization.sideEffects (默认为 true) :指代在优化过程中是否遵循依赖模块的副作用描述
4.Babel
在 Babel7 之前的 babel-preset-env 中,modules 的默认选项为'commonjs‘
在 Babel7 之后的 @babel/preset-env 中,modules 选项默认为 auto
总结
这节主要讨论了代码优化阶段效率提升的方向和方法
以提升当前任务工作效率为目标的方案
讨论了压缩 JS 时选择合适的压缩工具与配置优化项,以及压缩 CSS 时对优化工具的选择
以提升后续环节工作效率为目标的方案
讨论了 splitChunks 的作用和配置项,以及应用 Tree Shaking 的一些注意事项
要让引入的模块支持 Tree Shaking,需要注意
- 01:引入的模块需要是 ES6 类型的 CommonJS 类型的则不支持
- 02:引入方式不能使用 default
- 03:引用第三方依赖包的情况下,对应的 package.json 需要设置。sideEffects:false 来表明无副作用
- 04:使用 Babel 的情况下,需要注意不同版本 Babel 对于模块化的预设不同
5.缓存优化:那些基于缓存的优化方案
缓存优化的基本原理
terser-webpack-plugin/src/index.js:
if (cache.isEnabled()) {
let taskResult;
try {
taskResult = await cacheget(task); // 读取缓存
} catch (ignoreError) {
return enqueue(task); //缓存未命中情况下执行任务
}
task.callback(taskResult); // 缓存命中情况下返回缓存结果
// ...
const enqueue = async (task) => {
let taskResult;
if (cache.isEnabled() && !taskResult.error) {
await cache.store(task, taskResult); // 写入缓存
}
};
}编译阶段的缓存优化一-Babel-loader
- cacheDirectory:默认为 false,即不开启缓存。当值为 true 时开启缓存并使用默认缓存目录,也可以指定其他路径值作为缓存目录
- cacheldentifier:默认使用 Babel 相关依赖包的版本、babelrc 配置文件的内容,以及环境变量等与模块内容一起参与计算缓存标识符
- cacheCompression:默认为 true,将缓存内容压缩为 gz 包以减小缓存目录的体积。在设为 false 的情况下将跳过压缩和解压的过程
编译阶段的缓存优化--Cache-loader
./webpack.cache.config.js
module: {
rules: [
{
test: /.js$/,
use: ['cache-loader', 'babel-loader']
},
],
}上面两者的对比

优化打包阶段的缓存优化
生成 ChunkAsset 时的缓存优化
在 Webpack4 中,生成 ChunkAsset 过程中的缓存优化是受限制的
只有在 watch 模式下,且配置中开启 cache 时 (development 模式下自动开启),才能在这一阶段执行缓存的逻辑
代码压缩时的缓存优化
对于 JS 的压缩,TerserWebpackPlugin 和 UglifyJSPlugin 都是支持缓存设置的
对于 CSS 的压缩,目前最新发布的 CSSMinimizerWebpackPlugin 支持且默认开启缓存。其他的插件如 OptimizeCSSAssetsplugin 和 OptimizeCSSNanoplugin 目前还不支持使用缓存
缓存失效
如何最大程度地让缓存命中 成为我们选择缓存方案后首先要考虑的事情
缓存标识符发生变化导致的缓存失效
支持缓存的 Loader 和插件中,会根据一些固定字段的值加上所处理的模块或 Chunk 的数据 hash 值来生成对应缓存的标识符,例如特定依赖包的版本、对应插件的配置项信息、环境变量等
注意:在许多项目的集成构建环境中,特定依赖包由于安装时所生成的语义化版本导致构建版本时常自动更新,并造成缓存失效
编译阶段的缓存失效
偏译阶段的执行时间由每个模块的编译时间相加而成
在开启缓存的情况下,代码发生变化的模块将被重新编译旦不影响它所依赖的及依赖它的其他模块,其他模块将继续使用缓存
优化打包阶段的缓存失效
知道失效原因后,对应的优化思路尽可能地把那些不变的处理成本高昂的模块打入单独的 Chunk 中
使用 splitChunks 优化缓存利用率
./webpack.cache-miss.config.js
// ...
optimization: {
splitChunks: {
chunks: "all";
}
}
// ...其他使用缓存的注意事项
CI/CD 中的缓存目录问题
在许多自动化集成的系统中,项目的构建空间会在每次构建执行完毕后,立即回收清理
在集成化的平台中构建部署的项目,如果需要使用缓存
需要根据对应平台的规范,将缓存设置到公共缓存目录下
缓存的清理
缓存的便利性本质在于用磁盘空间换取构建时间
对于一个大量使用缓存的项目,随着时间的流逝,缓存空间会不断增大
对于上述多项目的集成环境而言,则需要考虑对缓存区域的定期清理
与产物的持久化缓存相区别
浏览器端加载资源的缓存问题
以及相对应的如何在 Webpack 中生成产物的持久化缓存方法 (hash、chunkhash、contenthash)
这一部分知识所影响的是项目访问的性能,而对构建的效率没有影响
总结
Webpack 的构建缓存优化分为两个阶段:
- 优化打包阶段的针对压缩代码过程的缓存优化
- 编译阶段的针对 Loader 的缓存优化
在使用缓存时还需要额外注意如何减少缓存的失效
针对不同的构建环境,还需要考虑到缓存目录的留存与清理等问题
上面介绍的几种支持缓存的插件 (TerserWebpackPlugin,CSSMinimizerWebpackPlugin) 和 Loader (babel-loader,cache-loader) 在缓存方面有哪些相同的配置项呢?
- 01:用于指定是否开启缓存以及指定缓存目录
- 02:用于指定缓存标识符的计算参数
6.增量构建:Webpack 中的增量构建
为什么我只改了一行代码,却需要花 5 分钟才能构建完成?
尽管只改动了一行代码,但是在执行构建时要完整执行所有模块的编译、优化和生成产物的处理过程
Webpack 中的增量构建
在开启 devServer 的时候,执行 webpack-dev-server 命令后,Webpack 会进行一次初始化的构建。构建完成后启动服务并进入到等待更新的状态
增量构建的影响因素一一 watch 配置
增量构建的影响因素一一 cache 配置
- 布尔值:般情况下默认为 false 在开发模式开启 watch 配置的情况下,默认值变更为 true
- 对象类型:表示使用该对象来作为缓存对象,用于多个编译器 compiler 的调用情况
体积最大的 react、react-dom 等模块和入口模块打入了同一个 Chunk 中
即使修改的模块是单独分离的 barjs 但它的产物名称的变化仍然需要反映在入口 Chunk 的 runtime 模块中
增量构建的实现原理
为什么在配置项中需要同时启用 watch 和 cache 配置才能获得增量构建的效果呢?
watch 配置的作用
lib/Watching.js
// ...
_go() {
// ...
this.compiler.hooks.watchRun.callAsync(this.compiler, err => {
const onCompiled = (err, compilation) => {
// ...
}
this.compiler.compile(onCompiled)
})
}cache 配置的作用
CachePlugin.js
compiler.hooks.thisCompilation.tap("CachePlugin", (compilation) => {
compilation.cache = cache;
// ...
});Compilation.js
addModule(module, cacheGroup) {
// ...
if (this.cache && this.cache[cacheName]) {
const cacheModule = this.cache[cacheName];
// ...
// 缓存模块存在情况下判断是否需要rebuild
rebuild = if (!rebuild) {
// ...
// 无需rebuild情况下返回cacheModule,并标记build:false
return {
module: cacheModule,
issuer: true,
build: false,
dependencies: true
}
}
// ...
createChunkAssets() {
if (this.cache && this.cachel[cacheName] && this.cache[cacheName].hash === usedHash ) {
source = this.cache[cacheNamel.source:
}else {
source = fileManifest.render();
// ...
}
}
}通过 Webpack 内置的 cache 插件,将整个构建中相对耗时的两个内部处理环节一一编译模块和生成产物进行缓存的读写处理,从而实现增量构建处理
生产环境下使用增量构建的阻碍
增量构建之所以快是因为将构建所需的数据都保留在内存中
对于管理多项目的构建系统,构建过程是任务式的:任务结束后即结束进程并回收系统资源
要想在生产环境下提升构建速度,首要条件是将缓存写入到文件系统中
Webpack 4
cache 配置只支持基于内存的缓存,并不支持文件系统的缓存
Webpack 5
正式支持基于文件系统的持久化缓存(Persistent Cache)
总结
增量构建在每次执行构建时,只编译处理内容有修改的少量文件,极大地提升构建效率
在 Webpack4 中,有两个配置项与增量构建相关: watch 和 cache
watch 保留进程,使得初次构建后的数据对象能够在再次构建时复用 cache 在添加模块与生成产物代码时可以利用 cache 对象进行相应阶段结果数据的读写
为什么在开启增量构建后,有时候 rebuild 还是会很慢呢?
1.Webpack 4 中的增量构建只运用到了新增模块与生成 chunk 产物阶段,其他处理过程仍需通过其他方式进行优化
2.过程中的一些处理会额外增加构建时间
7.版本特性:Webpack 5 中的优化细节
与构建效率相关的主要功能点:
1.Persistent Caching
持久化缓存的示例
./webpack.cache.config.js
// ...
module.exports = {
cache: {
type: "filesystem",
cacheLocation: path.resolve(__dirname, ".appcache"),
buildDependencies: {
config: [__filename],
},
},
// ...
};Cache 基本配置
Webpack 4 中
- cache 只是单个属性的配置,所对应的赋值为 true 或 false
Webpack 5 中
- cache 配置除了原本的 true 和 false 外,还增加了许多子配置项
Webpack 5 中新增配置
cache.type
- 值为'memory' 或'filesystem'分别代表基于内存的临时缓存以及基于文件系统的持久化缓存
cache.name
- 缓存名称。是 cacheDirectory 中的子目录命名,默认值为 Webpack 的 Sfconfignamel-Sfconfig.model
cache.cacheDirectory
- 缓存目录。默认目录为:node modules/.cache/webpack
cache.cacheLocation
- 缓存真正的存放地址默认使用的是:path.resolve(cache.cacheDirectory,cache.name)
单个模块的缓存失效
Webpack 5 会跟踪每个模块的依赖项
- fileDependencies
- contextDependencies
- missingDependencies
注意:对于 nodemodules 中的第三方依赖包中的模块 Webpack 会依据依赖包里 package.json 的 name 和 version 字段来判断模块是否发生变更
全局的缓存失效
当模块代码没有发生变化,但是构建处理过程本身发生变化时可能对构建后的产物代码产生影响在这种情况下需要让全局缓存失效,重新构建并生成新的缓存
buildDependencies
cache.buildDependencies一一用于指定可能对构建过程产生影响的依赖项
默认选项是:{defaultWebpack:["webpack/lib"]}
{config:[__filename]}:作用是当配置文件内容或配置文件依赖的模块文件发生变化时,当前的构建缓存即失效
version
使用 version 配置来防止在外部依赖不同的情况下混用了相同的缓存
- 传入 cache:fversion: process.env.NODE_ENVH
- 达到当不同环境切换时彼此不共用缓存的效果
name
缓存的名称除了作为默认的缓存目录下的子目录名称外,也起到区分缓存数据的作用
例如,可以传入 cache:{ name: process.env.NODE_ENV } 来防止在不同的环境中同时生成两个缓存文件。
- name 的特殊性:name 在默认情况下是作为缓存的子目录名称存在的,可以利用 name 保留多套缓存在 name 切换时,若已存在同名称的缓存,则可以复用之前的缓存
- 当 cacheLocation 配置存在时,将忽略 name 的缓存目录功能上述多套缓存复用的功能也将失效
其他
cache 还支持其他属性: managedPath、hashAlgorithm、store、idleTimeout
Webpack 4 中
部分插件默认启用缓存功能
Webpack 5 中
忽略各插件的缓存设置,由引擎自身提供构建各环节的缓存读写逻辑
2.Tree Shaking
Webpack4 中的 Tree Shaking 功能在使用上存在限制只支持 ES6 类型的模块代码分析,且需要相应的依赖包或需要函数声明为无副作用等
Nested Tree Shaking
// ./src/inner-module.js
export const a = 'inner_a'
export const b = 'inner_b'
// .src/nested-module.js
import * as inner from './inner-module'
const nested = 'nested'
export { inner, nested }
// ./src/example-tree-nested.js
import * as nested from './nested-module'
console.log(nested.inner.a)
// ./dist/tree-nest.js
(() => {
"use strict";
console.log("inner_a")})();
}Inner Module Tree Shaking
// .src/inner-module.js
export const a = 'inner_a'
export const b = 'inner_b'
export const c = 'inner_c'
// ./src/example-tree-nested.js 同上面示例
//.src/nested-module.js
// ...
const useB = function () {
return inner.b
}
export const usingB = function () {
return useB()
}
// ./dist/tree-nest.js (e??e??optimization.innerGraph = true)
// ...
const t="inner _a", n="inner_b"} ...
// ./dist/tree-nest.js (optimization.innerGraph = false)
// ...
const t = "inner_a"}
// ...CommonJS Tree Shaking
Webpack5 中增加了对一些 CommonJS 风格模块代码的静态分析功功能
- 01:支持 exports.xxx、this.exports.xxxmodule.exports.xxx 语法的导出分析
- 02:支持 obiect.defineProperty(exports, "xxxx",...) 语法的导出分析
- 03:支持 require('xxxx').xxx 语法的导入分析
// ./src/commonjs-module.js
exports.a =11
this.exports.b = 22
module.exports.c =33
console.log('module')
// ./src/example-tree-commonjs.js
const a = require('/commonjs-module').a
console.log(a)
// ./dist/tree-commonjs.js
()=>{ var o = { 263: function(o,r){ r.a = 11, console.log("module")}}
// ...3.Logs
webpack 4 中构建
LOG from webpack.buildChunkGraph.visitModules
<t> prepare: 0.581067ms
<t> visiting: 0.64386ms
<t> calculating available modules: 0.040637ms
<t> merging available modules: 0.011906ms
<t> visiting: 0.024662mswebpack 5 中构建
LOGfromweback.Comoiler
<t> make hook: 63.34753 ms
<t> finish make hook: @.875754 msfinish compilation: 2.163349 ms
<t> seal compilation: 153.249396 mst>ct>afterCompile hook: 0.105597 ms
<t> emitAssets: 1.965609 ms
<t> emitRecords: .085795 msdone hook: 0.226861 ms
<t> beginIdle: 0.090658 ms
LOG from webpack.ResolverCachePlugin0% really resolyed (0 real resolyes with 0 cached but invalid, 2 cached valid, 0 concurrent)
LOG from webpack.FlagDependencyExportsPluginctzrestore cached provided exports: 0.541466 mstsfiqure out provided exports: @.014885 ms%* of exports of modules have ben determined ( not cached, 0 flagged uncacheable, 2 from cache, 0 additional calculations due to dependencies
<t> store provided exports into cache: .048856 ms
LOG from webpack.Compilationfinish modules: 1.570761ct>ms
<t> report dependency errorsand warnings: 0.492546 ms
<t> optimize dependencies: 1.994 mscreate chunks: 3.077758 ms
<t> optimize: 11.360441 msmodules hashed (0.5 variants per module in average)
<t> module hashing: 1.54114 ms0% code generated (0 generated, 1 from cache)
<t> code generation: 1.01569 ms
<t> runtime requirements: 1.311863 msinitialize hash: 0.004017 ms
<t> hashing:hashing:
<t> sort chunks: .005157 ms
<t> hashing:hash runtimemodules: 0.091376 ms
<t> hashing:hash chunks: 1.713927 ms
<t> hash digest:0.062296 ms
<t> hashing:hashing:process fullhash modules: 0.001745 ms
<t> hashing: 2.201677 ms
<t> record hash: 0.029649 ms
<t> module assets: 0.13887 mscreate chunk assets: 1.693072 ms
<t> process assets: 127.357463 ms4.其他优化项
Webpack 5 中新增了改变微前端构建运行流程的 Module Federation 和对产物代码进行优化处理的 Runtime Modules 优化了处理模块的工作队列,在生命周期 Hooks 中增加了 stage 选项等
5.总结
Webpack5 的稳定版本将对外发布 (2020 年 10 月 10 日)
本节主要了解了 Webpack 最新版本与构建效率相关的几个优化功能点
重点是 Webpack 5 中引入的持久化缓存的特性
- 讨论了如何开启和定制持久化缓存
- 通过哪些方式可以让缓存主动失效,以确保在项目里可以安全地享受缓存带来的效率提升
- Webpack5 中对于 Tree Shaking 的优化能更好地优化项目依赖,减小构建产物的体积
Webpack 5 中的持久化缓存究竟会影响哪些构建环节呢?
- 编译模块:ResolverCachePlugin、Compilation/modules
- 优化模块:FlagDependencyExportsPlugin、ModuleConcatenationPlugin
- 生成代码:Compilation/codeGeneration、Compilation/assets
- 优化产物:TerserWebpackPlugin、RealContentHashPlugin
8.无包构建:盘点那些 No-bundle 的构建方案
1.什么是无包构建
- 打包工具:基于一个或多个入口点模块,通过依赖分析将有依赖关系的模块打包到一起最后形成少数几个产物代码包
- 无包构建:在构建时只需处理模块的编译而无须打包,把模块间的依赖关系完全交给浏览器来处理
./src/index.html
<script type="module" src="./modules/foo.js"></script>.src/modules/foo.js
import { bar } from '/bar.js'
import { appendHTML } from './common.js'
// ...
import('https://cdn.jsdelivr.net/npm/lodash-es@4.17.15/slice.js').then((module) => {
// ...
}浏览器会依次加载所有依赖模块
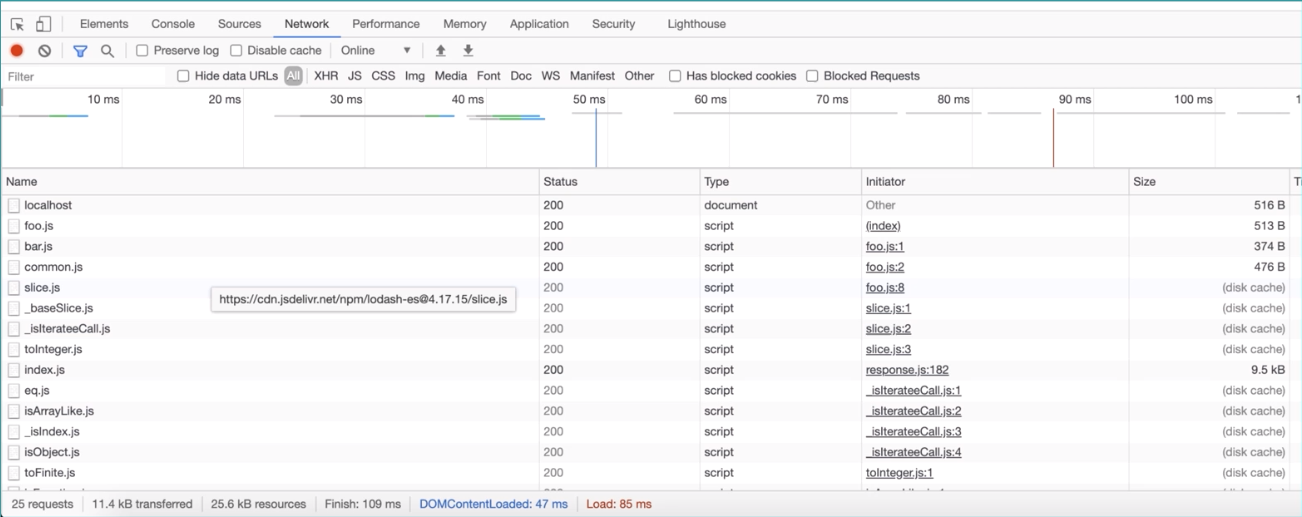
2.基于浏览器的 JS 模块加载功能
[图片来源: https://caniuse.com/es6-module]

HTML 中的 Script 引用
- 01:入口模块文件在页面中引用时需要带上 type="module"属性
- 02:带有 type="module"属性的 script 在浏览器中通过 defer 的方式异步执行
- 03:带有 type="module"属性且带有 async 属性的 script,在浏览器中通过 async 的方式异步执行
- 04:即使多次加载相同模块,也只会执行一次
模块内依赖的引用
- 只能使用 import...from ... 的 ES6 风格的模块导入方式,或者使用 import(...).then(..)的 ES6 动态导入方式,不支持其他模块化规范的引用方式 (例如 require、define 等)
- 导入的模块只支持使用相对路径('/xxx', './xxx', ''../xxx')和 URL 方式(https://xxx,http://xxx)进行引用,不支持直接使用包名开头的方式('xxxx','xxx/xxx')
- 只支持引用 MIMEType 为 text/iavascript 方式的模块,不支持其他类型文件的加载(例如 CSS 等)
为什么需要构建工具
- 01:许多第三方依赖包在通过第三方 URL 引用时过程烦琐,难以进行灵活的版本控制与更新
- 02:许多其他类型的文件需要编译处理为 ES6 模块才能被浏览器正常加载
- 03:对于现实中的项目开发而言,一些便利的辅助开发技术需要由构建工具来提供
3.Vite
Vite 是 Vue 框架的作者尤雨溪最新推出的基于 Native-ESM 的 Web 构建工具在开发环境下基于 Native-ESM 处理构建过程,只编译不打包,在生产环境下基于 Rollup 打包
npm init vite-app example-vite
cd example-vite
npm install
npm run dev对 HTML 文件的预处理
当启动 Vite 时,会通过 serverPluginHtml.ts 注入/vite/client 运行时的依赖模块该模块用于处理热更新,以及提供更新 CSS 的方法 updateStyle
对外部依赖包(Bare Modules) 的解析
...
对 Vue 文件的解析
通过 serverPluginVue.ts 处理的,分离出 Vue 代码中的 script/template/style 代码片段并分别转换为 JS 模块,然后将 template/style 模块的 import 写到 script 模块代码的头部
对 CSS 文件的解析
对 CSS 文件的解析是通过 serverPlugincss.ts 处理的
import { updateStyle } from " /vite/client";
const css = "...";
updateStyle('"..."', css); // id, cssContent
export default css;在 Vite 源码中还包含了其他更多文件类型的解析器,例如 JSON、TS、SASS 等
Vite 中的其他辅助功能
- 多框架:支持在 React 和 Preact 项目中使用。工具默认提供了 Vue、React 和 Preact 对应的脚手架模板
- 热更新 (HMR):默认的 3 种框架的脚手架模板中都内置了 HMR 功能,也提供了 HMR 的 API 供第三方插件或项目代码使用
- 自定义配置文件:支持使用自定义配置文件来细化构建配置,配置项功能参考 config.ts
- HTTPS 与 HTTP/2:支持使用--https 启动参数来开启使用 HTTPS 和 HTTP/2 协议的开发服务器
- 服务代理:在自定义配置中支持配置代理,将部分请求代理到第三方服务
- 模式与环境变量:支持通过 mode 来指定构建模式为 development 或 production 相应模式下自动读取 dotenv 类型的环境变量配置文件
- 生产环境打包:生产环境使用 Rollup 进行打包,支持传入自定义配置,配置项功能参考 build/index.ts
Vite 的使用限制
- 面向支持 ES6 的现代浏览器,在生产环境下,编译目标参数 esBuildTarget 的默认值为 es2019,最低支持版本为 es2015
- 对 Vue 框架的支持目前仅限于最新的 Vue 3 版本,不兼容更低版本
Snowpack
Snowpack 在生产环境下默认使用无包构建而非打包模式 Vite 仅在开发模式下使用
Snowpack 与 Vite 相同的功能点
Snowpack 与 Vite 两者都支持 各种代码转换加载器、热更新、环境变量 (需要安装 dotenv 插件)、服务代理、HTTPS 与 HTTP/2 等
Snowpack 与 Vite 的差异点
- 相同的功能,实现细节不同:Vite 支持类似“AAA/BBB”类型的子模块引用方式。而 Snowpack 目前尚不支持
- 工具稳定性:Vite 的最新版本为 v1.0.0-rc4。Snowpack 更新到了 v2.11.1 版本
- 插件体系:Snowpack 提供了较完善的插件体系,Vite 目前并没有提供自定义插件的相关文档
- 打包工具:Vite 使用 Rollup 作为打包工具。Snowpack 需要引入插件实现打包功能
- 特殊优化:Vite 中内置了对 Vue 的大量构建优化
无包构建的优点
- 01:初次构建启动快
- 02:按需编译
- 03:增量构建速度快
无包构建的缺点
- 浏览器网络请求数量剧增
- 浏览器的兼容性
总结
无包构建产生的基础是浏览器对 JS 模块加载的支持
主要介绍了无包构建工具中的 Vite 和 Snowpack
三、部署效率
1.部署初探:为什么一般不在开发环境下部署代码?
两个问题:
在前端项目的构建部署流程里,除了使用构建工具执行构建,还有哪些因素会影响整个部署流程的工作效率?
在部署系统中进行项目构建时,又会面临哪些和环境相关的问题和优化方案?
1.前端项目的一般部署流程
- 01:获取代码
- 02:安装依赖
- 03:源码构建
- 04:产物打包
- 05:推送代码
- 06:重启服务
2.本地部署相比部署系统的优势
- 获取代码的环节:直接获取更新内容并切换分支或版本的处理要更快一些
- 安装依赖的环节:更新依赖包的时间比在空目录下完整安装依赖包的时间更短
- 增量构建:在构建配置与项目依赖不发生变化的情况下,理论上,本地部署可以让构建进程长时间地驻留
- 快速调试:本地部署时,构建过程会直接在本地进行,远程的部署系统需要将一定的时间消耗在链路反馈和本地环境切换上
3.流程安全风险一一环境一致性
- 同一个项目,不同开发人员的本地环境都可能存在差异
- 由于 NodeJS 语义化版本(Semantic Version)在安装时自动升级的问题,不同开发人员的本地 node_modules 中的依赖包版本也可能存在差异
- 开发人员的本地环境和部署代码的目标服务器环境之间也可能存在差异
使用远程统一的部署系统
- 避免了不同开发人员的本地环境差异性
- 部署系统的工作环境可以与线上服务环境保持一致
4.流程安全风险一一过程一致性
过程的一致性:是尽可能地让每次部署的流程顺序、各环节的处理过程都保持一致,从而打造规范化的部署流程
5.工作效率问题一一可回溯性
- 日志:在部署过程中遇到各种问题,例如构建失败、单元测试执行失败、推送代码失败、部署后启动服务失败等需要有相应的日志来帮助定位
- 产物:部署系统中会留存最近几次部署的构建产物包,以便当部署后的代码存在问题时能够快速回滚发布本地部署在项目的开发目录下执行,通常只会保留最近一次的构建产物
6.工作效率问题一一人员分工
- 01:部署过程需要耗费时间
- 02:如果一个项目只有个别开发者的本地环境拥有部署权限,增加对有权限的开发者的工作时间的占用
- 03:部署流程会主动由测试人员而非开发人员发起,增加了相应的沟通成本
7.工作效率问题一一 CI/CD
持续集成 (Continuous Integration,CI) 和 持续交付 (Continuous Delivery,CD)
开发人员提交代码后,由 CI/CD 系统自动化地执行合并、构建、测试和部署等一系列管道化 Pipeline) 的流程从而尽早发现和反馈代码问题,以小步快跑的方式加速软件的版本迭代过程
总结
这节课主要讨论了相比远程部署系统,本地部署的优缺点
优点
- 流程简化
- 快速调试
缺点
- 流程安全风险
- 人员效率
2.工具盘点:掌握那些流行的代码部署工具
一个优秀的部署系统
- 提供过程日志、历史版本构建包、通知邮件等各类辅助功能模块,来打造更完善的部署工作流程
- 自动化地完整部署流程的各环节,能保证环境与过程的一致性,增强流程的稳定性,降低外部因素导致的风险
工具盘点:掌握那些流行的代码部署工具
1.Jenkins
Jenkins 是诞生较早且使用广泛的开源持续集成工具
2004 年,Sun 公司推出它的前身 Husdon,2011 年更名为 Jenkins
Jenkins 一一功能特点
- 搭建方式:基于 Java 的应用程序,支持分布式的服务方式,各任务可以在不同的节点服务器上运行
- 收费方式:完全免费的开源产品
- 多类型 Job:自定义项目、流水线、文件夹/多配置项目、Github 组织等
- 插件系统:Jenkins 架构中内置的插件系统为它提供了极强的功能扩展性
API 调用
Jenkins 提供了 Restful 的 API 接口,可用于外部调用控制节点、任务、配置、构建等处理过程
2.CircleCl
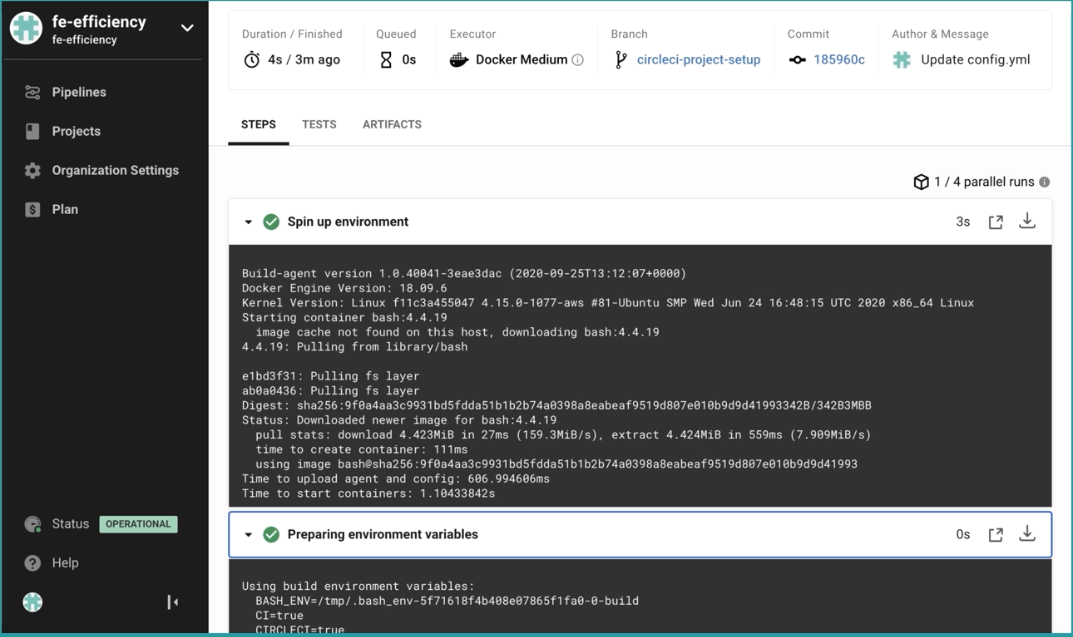
CircleCI 一功能特点
- 1.云端服务:无需搭建和管理即可直接使用,提供了收费的本地化搭建服务方式
- 2.收费方式:分为免费与收费两种
- 3.缓存优化:CircleCI 的任务构建是基于容器化的,能够缓存依赖安装的数据、
- 4.SSH 调试:提供基于 SSH 访河构建容器的功能,便于在构建错误时快速地进入容器内进行调试
- 5.配置简化:提供了开箱即用的用户体验
- 6.API 调用:提供了 Restfull 的 API 接口,可用于访问项目、构建和产物
CircleCI 项目流水线示例界面
3.Github Actions
Github Actions (GHA) 是 Github 官方提供的 CI/CD 流程工具用于为 Github 中的开源项目提供简单易用的持续集成工作流能力
Github Actions 一一功能特点
- 多系统:提供 Linux、Mac、Windows 等各主流操作系统环境下的运行能力,同时也支持在容器中运行
- 矩阵运行:支持同时在多个操作系统或不同环境下运行构建和测试流程
- 多语言:支持 NodeJS、JAVA、PHP、Python、Go、Rust 等各种编程语言的工作流程
- 多容器测试:支持直接使用 Docker-Compose 进行多容器关联的测试 (CircleCl 中需要先执行安装才能使用)
- 社区支持:Github 社区中提供众多工作流的模板可供选择,例如构建并发布 npm 包、构建并提交到 DockerHub 等
- 费用情况:对于公开的仓库,以及在自运维执行器的情况下是免费的。对于私有仓库则提供一定额度的免费执行时间和免费存储空间,超出部分需要收费
Github Actions 的工作流模板
Github Actions 中的矩阵执行示例
4.Gitlab Cl
- Gitlab 是由 Gitlab inc.开发的基于 Git 的版本管理与软件开发平台
- 具有在线编辑、Wiki、CI/CD 等功能
- 提供了免费的社区版本 (Community Edition,CE) 和免费或收费的商用版本 (Enterprise Edition,EE)
Gitlab CI 一一功能特点
- Gitlab CI 使用 yml 文件作为 CI/CD 工作流程的配置文件,默认的配置文件名为 gitlab-ci.yml
- 在配置文件中涵盖了任务流水线 (Pipeline) 的处理过程细节:
- 例如在配置文件中可以定义一到多个任务 (Job);
- 每个任务可以指定一个任务运行的阶段 (Stage) 和一到多个执行脚本 (Script)等
- Gitlab 中需要单独安装执行器Gitlab Runner 的作用是执行任务,并将结果反馈到 Gitlab 中
- 开发者在独立的服务器上安装 Gitlab Runner 工具 然后依次执行 gitlab-runner register 注册特定配置的 Runner。最后执行 gitlab-runner start 启动相应服务
Gitlab CI/CD 的任务列表示例界面

5.总结
Jenkins
优点一一插件功能丰富且完全开源免费缺点一一缺少特定语言环境工作流的配置模板,使用成本相对较高,服务器需要独立部署和运维
CircleCI 和 Github Actions
都提供了基于容器化的云端服务的能力 提供不同的收费策略以满足普通小型开源项目和大型私有项目的各类需求
CircleCl
支持 BitBucket、Heroku 等平台的流程对接
Github Actions
使用成本最低,提供了矩阵运行、多容器测试、多工作流模板等特色功能
Gitlab
Gitlab CI 是企业中较受欢迎的版本管理工具 Gitlab 中内置 CI/CD 工具,使用 yml 格式的配置文件,需要独立安装与配置 Runner
如果你所在的企业需要选择一款 CI/CD 工具你选择的主要依据有哪些呢?
- 选择付费系统还是免费系统,选择云服务还是自运维
- 所选的方案是否便于对接上下游系统流程
- 使用配置是否便捷,对用户而言是否有学习成本......
3.安装提效:部署流程中的依赖安装效率优化
3.1 五种前端依赖的安装方式
- npm:NodeJS 自带的包管理工具,测试时,使用默认安装命令 npm install
- Yarn:Yarn 是 Facebook 于 2016 年发布的包管理工具,Yarn 在依赖版本稳定性和安装效率方面通常更优测试时使用默认安装命令 Yarn
- Yarn with PnP:抛弃作为包管理目录的 node_modules,使用软链接到本地缓存目录的方式来提升安装和模块解析的效率测试时使用 yarn -pnp
- Yarn v2:Yarn 在 2020 年初发布了 v2 版本,通过 Set Version 的方式安装在项目内部测试时使用安装命令 Yarn
- pnpm:它支持依赖版本的确定性安装特性,同时使用硬连接与符号连接缓存目录的方式测试时使用安装命令 pnpm install
3.2 依赖安装的基本流程
- 01:解析依赖关系阶段: 分析项目中各依赖包的依赖关系和版本信息
- 02:下载阶段:这个阶段的主要功能是下载依赖包
- 03:链接阶段: 处理项目依赖目录和缓存之间的硬链接和符号连接
3.3 如何获取执行时间
使用系统提供的 time 命令获取执行时间
time npm i
time yarn
time pnpm i3.4 如何获取执行日志
- npm:使用 npm 安装时需要在执行命令后增加--verbose 来显示完整日志
- Yarn v1:Yarn v1 版本(包括 Yarn --PnP) 通过增加--verbose 来显示完整日志
- Yarn v2:Yarn v2 版本默认显示完整日志,可通过--ison 参数变换日志格式
- pnpm:pnpm 安装时需要在执行命令后增加 --reporterndison 来显示完整日志
3.5 环境状态的五个分析维度
| 场景名称 | Lock 文件 | 历史安装目录 | 本地缓存 | 示例中日志名称 |
|---|---|---|---|---|
| 纯净环境 | - | - | - | clean install.log |
| Lock 环境 | Y | - | - | lock_install.log |
| 缓存环境 | Y | - | Y | cached install.log |
| 无缓存的重复安装环境 | Y | Y | - | nocache reinstall.log |
| 重复安装环境 | Y | Y | Y | cached_reinstall.log |
3.6 纯净环境
| 安装工具 | npm(v6.9) | Yarn(v.1.21.1) | Yarn -PnP(v1.21.1) | Yarn(2.2.2) | pnpm(v5.8.0) |
|---|---|---|---|---|---|
| 安装时间 | 17.31s | 29.6s | 24.97s | 62.4s | 18.16s |
| 解析依赖阶段 | 4.52s | 5.39s | 6.82s | 11.38s | - |
| 下载阶段 | 10.01s | 16.57s | 16.63s | 46.74s | - |
| 链接阶段 | 2.78s | 7.64s | 1.52S | 4.49s | - |
npm < pnpm < Yarn v1 --PnP < Yarn v1 < Yarn v2
3.7 Lock 环境
| 安装工具 | npm(v6.9) | Yarn(v.1.21.1) | Yarn -PnP(v1.21.1) | Yarn(2.2.2) | pnpm(v5.8.0) |
|---|---|---|---|---|---|
| 安装时间 | 13.12s | 22.69s | 21.03s | 49.25s | 11.51s |
| 解析依赖阶段 | 0.847s | ~0s | ~0s | ~0s | 0.05s |
| 下载阶段 | 10.19s | 15.92s | 19.79s | 46.9s | 10.3s |
| 链接阶段 | 2.08s | 6.77s | 1.24S | 2.17s | 1.16s |
3.8 缓存 环境
| 安装工具 | npm(v6.9) | Yarn(v.1.21.1) | Yarn -PnP(v1.21.1) | Yarn(2.2.2) | pnpm(v5.8.0) |
|---|---|---|---|---|---|
| 安装时间 | 8.11s | 6.54s | 1.95s | 2.61s | 5.25s |
| 解析依赖阶段 | 0.859s | ~0s | ~0s | ~0s | 0.05s |
| 下载阶段 | 5.23s | ~0s | ~0s | 0.24s | 4.38s |
| 链接阶段 | 2.01s | 6.54s | 1.8S | 2.37s | 0.87s |
本地缓存主要优化的是下载依赖包阶段的耗时
3.9 无缓存的重复安装环境
| 安装工具 | npm(v6.9) | Yarn(v.1.21.1) | Yarn -PnP(v1.21.1) | Yarn(2.2.2) | pnpm(v5.8.0) |
|---|---|---|---|---|---|
| 安装时间 | 2.79s | 0.41s | 19.51s | 47.63s | 1.13s |
| 解析依赖阶段 | 0.964s | ~0s | ~0s | ~0s | 0.076s |
| 下载阶段 | ~0s | ~0s | 19.11s | 46.68s | 0.033s |
| 链接阶段 | 1.83s | ~0s | 0.4s | 0.77s | 0.222s |
存在安装目录这一条件首先对链接阶段能起到优化的作用
3.10 有缓存的重复安装环境
| 安装工具 | npm(v6.9) | Yarn(v.1.21.1) | Yarn -PnP(v1.21.1) | Yarn(2.2.2) | pnpm(v5.8.0) |
|---|---|---|---|---|---|
| 安装时间 | 2.76s | 0.51s | 0.84s | 1.55s | 1.10s |
| 解析依赖阶段 | 0.936s | ~0s | ~0s | ~0s | 0.076s |
| 下载阶段 | ~0s | ~0s | ~0s | 0.24s | 0.035s |
| 链接阶段 | 1.44s | ~0s | 0.69s | 0.76s | 0.221s |
3.11 不同安装条件
项目的依赖安装过程,效率最高的 3 个条件:存在 Lock 文件存在,存在本地缓存存在和存在安装记录
- Lock 文件的留存是最容易做到的,也是最可能被忽略的,大部分项目都会保留在代码仓库中
- 本地缓存是当安装记录不存在时最重要的优化手段。对于大部分部署系统,注意磁盘空间与效率的平衡在部署服务的个别项目中,执行清除缓存的操作也会影响其他项目。
- 本地安装记录对于部署系统需要占据较多的磁盘空间,建议确认所使用的部署系统是否支持相关设定
- 安装条件方面,有一些额外的不容易量化的条件,例如网速、磁盘 I/0 速度等
3.12 不同安装工具
单从效率而言,各工具在不同安装条件下的优劣各有不同
- 如果考虑各种场景下的综合表现,pnpm 是最稳定高效的
- 如果考虑现实情况中,Yarn v1 是更好的选择
- 如果考虑只有 Lock 文件的情况,则 npm 的表现要优于 Yarn
- 在无安装目录的情况下,Yarn v1 的 PnP 模式效率要高于普通模式
- Yarnv2 支持针对单个项目清除缓存而不影响全局
不同的安装工具对构建过程会产生影响
- Yarn v1 普通模式可以作为 npm 的直接替代,不对构建产生影响
- PnP 模式、Yarn v2 和 pnpm 在项目中选择工具时需要综合考虑
3.13 总结
这一课时主要讨论了部署流程中的依赖安装环节的执行细节问题
如果项目中使用的是 npm,在最佳条件下是否可以像 Yarn 那样耗时更趋近于零呢?
当然可以
1 提升依赖下载速度
依赖包下载源 (registry)
# npm设置下载源
npm config set registry xxxx
# yarn设置下载源
yarn config set registry xxxx进制下载源
npm config set sass-binary-site https://npm.taobao.org/mirrors/node-sass
npm config set puppeteer_download host https://npm.taobao.org/mirrors2 多项目共用依赖缓存
对于使用多台构建服务器的分布式 CI 系统,要考虑的是如何最大化地利用缓存
例如让使用相同依赖工具的项目共用相同的服务器,以及让技术栈相同的项目共用相同的服务器
3 安装目录缓存
缓存写入
以 package-lock.json 文件内容的 Hash 值作为缓存的 Key
将 node modules 目录压缩打包存储到缓存空间内
缓存读取
判断当前代码的 package-lock.ison 内容的 Hash 值
是否能够命中缓存目录中的 Key 值如果命中缓存,直接使用缓存中的 node modules 压缩包解压
使用时注意点
- 原生的依赖缓存:以单个依赖包为存储单元缓存空间中只会新增变更的版本数据
- 人工缓存安装目录:以 Lock 文件的 Hash 值为 Key,当个别依赖版本发生变更时,需要在依赖安装结束后重新缓存整个安装目录
影响安装的关联因素
- 前端项目:执行安装后的依赖包内容和项目中的依赖版本相关还和执行安装时的操作系统以及 NodeJS 版本有关
- 分布式的 CI 系统:如果共用缓存空间,必须在生成缓存 Key 时将这些变量因素也加入其中参与计算
检测项目 Lock 文件
Lock 文件对于依赖安装过程的重要性
- 01:需要项目的开发者注意对 Lock 文件的保存和维护
- 02:在 CI 系统的工作流程中加入对 Lock 文件的检测
4.流程优化:部署流程中的构建流程策略优化
4.1 代码构建阶段的提效
构建阶段是整个部署流程中最耗时的一个环节
CI 系统中的持化缓存
- CI 系统中项目的构建空间通常是临时的
- 在开始部署时创建项目工作目录,在部署结束后删除工作目录,以达到节约资源的目的
弊端一一无法利用构建过程中的持久化缓存机制
以 Webpack 为例
- 项目执行构建后,中间过程的缓存默认存放于 node_modules/.cache 目录下
- 再次构建时,无法利用持久化缓存来提升再次构建的效率
备份
- 项目构建结束后,对项目的目录结构进行扫描,找到.cache 目录
- 依据其相对项目根目录的路径生成备份目录名称
- 例如把项目中/client/node modules/.cache 多层目录转换为折叠目录
- client _node_modules .cache,然后将其备份到 CI 系统专用的持久化缓存备份空间中
还原
- 在部署过程进行到开始构建的阶段时,查看备份空间中是否存在对应项目的持久化缓存目录
- 若存在,则直接解析目录结构,将.cache 还原回项目相应的目录中
4.2 产物打包阶段的提效
CI 系统在构建结束后,需要将产物进行压缩打包,以便归档和在推送产物到服务器时减少传输数据量,提升传输效率
提升压缩效率的工具
| 压缩工具 | 压缩速度 (MB/s) | 解压速度 (MB/s) | CPU 占用% | 压缩率 |
|---|---|---|---|---|
| Gzip (default level 6) | 29.81 | 161.71 | 99 | 3.1067 |
| Gzip (level 1) | 78.34 | 161.71 | 99 | 2.7396 |
| Pigz (default level 9) | 72.71 | 301.69 | 776 | 3.0857 |
| Pigz (level 1) | 326.03 | 301.69 | 742 | 2.7087 |
| Zstd (default level 3) | 449.19 | 374.33 | 646 | 3.1777 |
| Zstd (level 1) | 1263.36 | 652.06 | 576 | 2.8802 |
使用时需要注意
- 如果待压缩的内容体积不大可以使用默认的 Gzip 压缩
- Pigz 和 Zstd 都启用了并行处理,处理过程中 CPU 和内存的占用会比 Gzip 更高
- Pigz 的压缩产物和 Gzip 格式是兼容的,Zstd 是不兼容的,往往被用于压缩与解压流程闭环的应用场景中
4.3 总结
- 01:依赖安装阶段的多维度提升安装效率
- 02:代码构建阶段的持久化缓存备份
- 03:产物打包阶段的提升压缩效率
本节课我们在哪些方案中使用了缓存机制?它们各自的作用分别是什么呢?
三种缓存机制:
- 多项目共用依赖缓存
- 作用:
- 依赖安装目录的缓存
- 作用:
- 构建过程的持久化缓存备份
- 作用:
5.容器方案:从构建到部署,容器化方案的优势有哪些?
5.1 什么是容器化
容器化 (Containerization) 通常指以 Docker 技术为代表,将操作系统内核虚拟化的技术占用空间更小、性能开销更低、启动更快、支持弹性伸缩以及支持容器间互联等优势
5.2 Docker
Docker 指运行在 Linux/Windows/macoS 中开源的虚拟化引擎用于创建、管理和编排容器
Docker 镜像(Image)
镜像一一创建容器实例的基础虚拟化模板
通过一个镜像可以创建多个容器实例,镜像之间也存在继承关系
一个基于 node:14 的镜像,在创建时包含了运行 node14 版本所需的 Linux 系统环境
还包含了额外打入到镜像内的 Yarn 程序
容器 (Container)
通常一个容器内包含了一个或多个应用程序以及运行它们所需要的完整相关环境依赖
通过 Docker 引擎可以对容器进行创建、删除、停止、恢复、与容器交互等操作
数据挂载与数据卷
解决持久化保留数据的两种方式:
- 挂载容器的宿主环境的目录
- 使用数据卷
网络
Docker 容器的网络有多种驱动类型,例如 bridge、host、overlay 等
bridge 一一用于点对点访问容器间端口或者将容器端口映射到宿主环境下
host一一直接使用宿主环境的网络
5.3 容器化的构建部署
容器化的构建部署把原先在部署服务器中执行的项目部署流程的各个环节,改为使用容器化的技术来完成
操作镜像阶段
#通过FROM指定父镜像
FROM node:12-slim
# 通过RUN命令依次在镜像中安装git,make和curl程序
RUN apt-get update
RUN apt-get -y install git
RUN apt-get install -y build-essential
RUN apt-get install -y curl在 Dockerfile 所在目录下执行构建命令,即可创建相应镜像
docker build --network host --tag foo:bar其他指令参照官方文档:
操作容器阶段
容器阶段的主要目标是基于项目的工作镜像创建执行部署过程的容器并操作容器执行相应的各部署环节:获取代码、安装依赖、执行构建、产物打包、推送产物等
# 创建容器
docker run -dit --name container_1 foo:bar bash
# 容器内执行命令
docker exec -it container_1 xxxx5.4 容器化部署过程的优势
- 环境隔离:防止共用一台服务器时可能产生的互相影响保证每个项目都可以自由定制专属的环境依赖
- 多环境构建:针对同一个项目生成多套不同的构建环境使项目可以同时检测多套环境下的集成过程
- 便于调试:通过 Xterm+SSH 的方式,通过浏览器访问部署系统中的容器环境容器化的方式可以在部署遇到问题时让用户第一时间进入容器环境中进行现调试
- 环境一致性与迁移效率:在支持 Docker 引擎的任意服务器中使用,无须考虑不同服务器操作系统的差异,在迁移时可以做到一键迁移
5.5 缓存问题
依赖缓存
默认情况,容器内的依赖缓存目录与宿主环境缓存目录不互通,每次部署流程都在新容器中进行
- 生成容器时挂载宿主环境依赖缓存目录
- 安装目录缓存
构建缓存
容器化的情况,每次部署过程都会基于新容器环境重新执行各部署环节构建过程的缓存数据会随着部署结束、容器移除而消失
- 在宿主环境中创建构建缓存目录并挂载到容器中,并在项目构建配置中将缓存目录设置为该目录
- 将缓存备份到宿主服务器或远程存储服务器中,在新部署流程中进行还原使用
性能问题
- 01.容器资源限制:创建容器时通过参数限制容器使用的 CPU 核心数和内存大小,限制系统资源在一定程度上导致执行过程性能的降低
- 02.copy-to-write:容器中环境的数据来自镜像层,新增的数据来自写入容器层。如果修改或删除的是镜像层的数据,容器会先将数据从镜像层复制到容器层,然后进行相应操作
5.6 总结
- 01:以 Docker 为代表的容器化技术的基本概念: 镜像、容器、数据挂载和网络等
- 02:容器化构建部署流程: 先创建镜像,然后根据镜像创建容器,最后在容器内执行相关部署环节
- 03:容器化部署具有隔离性高、支持多环境矩阵执行、易于调试和环境标准化等优势
容器化技术可以应用在部署过程中也更广泛地被应用在部署后的项目服务运行中试比较这两种场景下对容器化技术需求的差异性
- 容器持续时间不同:容器化部署的容器只在部署时创建使用,部署完成后即删除;容器化服务通常长时间运行
- 容器互联:容器化部署中的容器通常无须访问其他容器;容器化服务涉及多容器互联,以及更多弹性伸缩的容器特性
- 容器资源:容器化部署中涉及构建等 CPU 和 I/0 密集型处理;容器化服务对网络负载更敏感
6.案例分析:搭建基本的前端高效部署系统
分析一个基本的前端部署系统的工作流程、基本架构和主要功能模块的技术点
6.1 构建部署工作流程
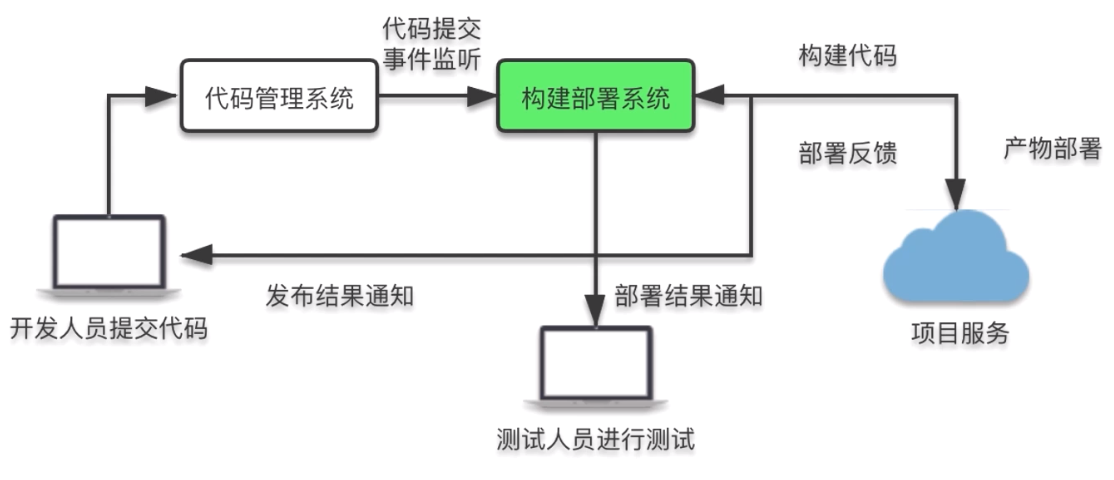
1.Webhook
部署系统将一个 Webhook 接口注册到代码管理系统(CVS) 中提交代码后,触发 CVS 的 Webhook,由 CVS 将提交事件通知给部署系统
2.项目构建
构建任务在执行时依次执行 代码获取、依赖安装、代码构建和产物打包等环节
3.产物部署
Push 模式
部署系统通过 SCP 等方式将产物包推送到目标服务器,并执行解压重启等发布流程
Pull 模式
提供下载接口,由下游发布环节调用,获取产物包以便执行后续发布流程,下游环节调用反馈接口,将发布结果反馈至部署系统
4.结果反馈
构建结果与部署结果会通过通知模块(消息、邮件等)的方式反馈至开发与测试人员
6.2 系统使用辅助流程
- 登录与用户管理:获取使用者的基本信息,并对其在系统内的使用权限进行管理
- 项目流程:系统内新增项目、修改项目部署配置获取项目列表与查看项目详情等
- 构建流程:呈现项目的构建记录列表、构建详情等信息并能通过界面操控构建任务的状态变更
- 发布流程:呈现项目的发布记录列表,并能通过界面操控构建记录的发布等
部署服务器环境准备
项目构建部署的服务器需要具备构建部署流程所需的相关环境条件
在非容器化的情况下,如果搭建的是分布式的服务,则需要尽量保证一些环境条件的一致
01:NodeJS
02:全局依赖工具
03:各类配置文件与环境变量
04:统所需其他工具
05:服务目录划分与维护
Webhook
- 01:在 CVS 系统中创建 Web 应用
- 02:在部署系统中新增接收 Webhook 消息的路由
- 03:在部署系统中新增项目时,调用创建 Webhook 的接口,根据需求设置特定的 Webhook 参数
任务队列
在部署系统接收到 Webhook 传递的代码提交信息后
根据提交信息创建构建记录,并执行构建任务
- 需要使用容器化构建部署,构建任务在独立容器内进行
- 需要对整个部署系统的同时执行任务数(Concurrency) 设定限制
// 创建任务队列
queue = new Queue(qname, {
redis: redisConfig,
});
queue.promiseDone = () => {};
queue.process(async (job, done) => {
const config = job.data;
const task = new BuildTask(config); // 创建并执行构建任务
queue.promiseDone = done; // 将任务完成函数赋值给外部属性,用于异步完成
return queue;
});
export const queueJobComplete = async (id) => {
queue.promiseDone();
};
export const queueJobFail = async (id, err) => {
queue.promiseDone(new Error(err));
};
export const queueJobAdd = async (id, data) => {
queue.add(data, {
jobld: id, // jobld of queue
});
};6.3 构建任务阶段与插件系统
初始化阶段
获取代码阶段
依赖安装阶段
构建执行阶段
产物打包阶段
1.明确构建执行进展,当构建中断时便于定位到具体的执行阶段
2.各阶段独立统计耗时便于针对性优化
3.使用 Tapable 定义各阶段的 Hooks,将复杂的构建任务执行过程拆分到各功能插件中
6.4 任务命令与子进程
# 依赖安装
npm install
# 执行构建
npm run build
# 产物打包
tar -zcf client.tar.gz dist/例子
import { spawn } from 'child process';
export const spawnPromise = ({ commands, cwd, onStdout, onStderr }) => {
return new Promise((resolve, reject) => {
onStdout = onStdout || (() => {})
onStderr = onStderr || (() => {})
const subProcess= spawn('bash', { detached: true, cwd })
subProcess.on('close', (code, signal) => {
if(signal==='SIGHUP'){
// abort callbackimmediately after kill
return reject()
}
if (code === 0){
resolve('ok')
}else {
reject()
}
})
subProcess.stdout.setEncoding('utf8');
subProcess.stderr.setEncoding('utf8');
subProcess.stdout.on('data', onStdout);
subProcess.stderr.on('data', onStderr);
subProcess.stdin.on('error', (e) => {
notifySysError('subprocess stdin error', e);
reject(e);
}
commands.forEach((command) => {
subProcess.stdin.write(command + '\n');
}
subProcess.stdin.end()
}
}6.5 状态、事件与 Socket
- 初始化:已部署服务接收到了 Webhook 的提交信息,并提取了构建所需的所有配置数据
- 同时也已创建了对应的构建记录
- 队列中:该构建任务已列入等待队列中
- 进行中:任务已开始执行
- 已取消:任务已被用户主动取消执行
- 已成功:构建任务已完成,用户可以进行下一步的发布流程已失败: 构建任务已失败,需要用户确认失败原因并调试修复
- 已超时:构建任务已超时
反馈过程
- 构建任务:当达到特定终止状态时由服务进程触发相应事件
- 构建事件处理器:根据监听到的不同事件执行相应的处理
- Socket 处理器:服务器端触发相应的 Socket 消息,网页端接收到 Socket 消息后,会变更页面中的构建记录显示状态
6.7 总结
- 流程梳理
- 核心技术模块分析
流程梳理
- 需要对构建部署的整体工作流程有一个比较清晰的认知掌握服务内部用户界面的各模块操作流程
核心构建流程的模块分析
- 了解操作层面的服务器环境的准备工作
- 代码架构层面的任务队列、构建任务阶段与状态拆分等
前端效率工程化总结
开发效率
- 脚手架工具
- 开发构建
- 热更新
- sourceMap
- mock 工具
- 编码效率工具
- 云开发
- 低代码开发
- 无代码开发
构建效率
- 构建工具历史
- webpack 构建流程分解
- 编译阶段提效
- 打包阶段提效
- 缓存优化
- 增量构建
- webpack 5
- no-bundle
部署效率
- 部署环境对比
- 部署工具介绍
- 安装阶段提效
- 流程策略优化
- 容器化部署
- 构建部署系统架构
前端效率工程化的未来展望
云工作流
开发效率方面,由 WebIDE 发展而来的云开发工具目前正逐渐成为几个大型厂商探索的方向之一
AI 生成页面
基于 AI 的生成页面工具(例如微软的 Sketch2Code) 可以进一步解放生产力
仍有各自的局限性
- 基于设计稿 (sketch/PSD) 的精准生成方式
- 基于草图乃至描述语句的 AI 匹配生成方式
Go/Rust
Webpack 5 带来了更完整的缓存策略和代码优化策略
但构建工具本身的性能仍然受到 NodeJS 自身语言的限制
基于 GoRust 等高性能语言的编译工具在未来或许能成为性能突破点之一
No bundle & HTTP/3
无包构建工具在生产环境下仍然采用打包构建的方式
随着网络技术的发展,或许最终可以在生产环境下同样采用无包构建
渐进式的使用方式也可能很快成为可实现的方向
总结
- 如果你目前主要做的是具体项目的开发维护工作,分析现有项目的构建工具、构建配置是一个很好的入手点
- 如果你目前承担着多个项目的选型与架构工作,希望开发效率模块的一些视角可以为你带来思路
- 如果你目前从事前端基础建设的相关工作,希望课程中提到的一些新的开发、构建和部署工具能为你提供一些着手方向
前端自动化/工程化
前端模块化规范
浏览器模块化规范 (过时不推荐)
AMD
- require.js
CMD
服务器端模块化规范
CommonJS
1.模块分为单文件 与 包
2.模块成员导出:module.exports 和 exports
3.模块成员导入:require('模块标识符')
大一统的模块化规范- ES6 模块化
是浏览器端与服务端通用的模块化开发规范
ES6 模块化规范中定义:
每个 js 文件都是一个独立的模块
导入模块成员 使用 import 关键字
暴露模块成员 使用 export 关键字
前端工程化
概念
开发流程
技术选型
代码规范
构建发布
工具
grunt 构建工具
对需要反复重复的任务,例如压缩、编译、单元测试、linting 等,自动化工具可以减轻劳动,简化操作
可用的 Grunt 插件
coffeescript
handlebars
iade
JSHint
less
sass
stylus
require.js
安装
官网
- www.gruntjs.net
官网有教程
webpack
概念/作用和官网
前端资源构建工具:前端的所有资源文件(js/json/css/img/css 预处理文件)都做模块化处理。 会根据模块依赖的关系进行静态分析,打包生成对应的静态资源(bundle)
作用
资源的压缩
代码的混淆
代码检查
转义
ES6
JSX
预处理
开发-热更新
webpack-dev-server
webpack-dev-middleware
官网
环境配置
webpack 5
新特点
- 通过持久缓存提高构建性能.
- 使用更好的算法和默认值来改善长期缓存.
- 通过更好的树摇和代码生成来改善捆绑包大小.
- 清除处于怪异状态的内部结构,同时在 v4 中实现功能而不引入任何重大更改.
- 通过引入重大更改来为将来的功能做准备,以使我们能够尽可能长时间地使用 v5.
下载安装
- npm i webpack@next webpack-cli -D
gulp
官网
核心概念
tasks
pipeline
插件
资源处理
gulp-uglify
gulp-sass
gulp-imagemin
gulp-concat
任务及状态管理
gulp-plumber
run-sequence
代码检查
gulp-jshint
gulp-eslint
热更新
gulp-livereload
browser-sync
yeoman
现代应用程序的 Web 的脚手架工具
官网
安装
- npm install -g yo
- 全局安装
- npm install -g yo
yo 命令
yo brian-gulp
- 下载形成项目文件目录
yo run build
- 运行
构建脚手架 generator
全局安装
- npm install -g generator-generator
运行
- yo generator
发布
npm config set registry https://registry.npmjs.org/
npm login
- 输入用户名密码登录
npm publish
- 发布
使用
- npm 官网查看
团队协作
版本管理
版本格式
1.2.3-beta.1 + meta
1
- 主版本
- API 的变化和接口的重启
- 主版本
2
- 次版本
- 可能会有 api 的更新或者迭代
- 次版本
3
- 修订号
- 解决小 bug
- 修订号
beta.1
- 先行测试版本
meta
- 元数据
常见版本名称释义
alpha
内部测试版本
有很多未测试的漏洞
beta
公测版本
消除了严重的错误,但是还会有很多小 bug
rc
发行候选版本
不会加入新功能,主要是排错修改 bug
release
- 发行版本
Git(版本管理)
1.下载和安装 Git
官网下载
傻瓜式安装
- 一直点下一步
2.git 基本工作流程
1.开发者向 git 提交项目状态
2.提交的状态会存在暂存区
3.然后再将暂存区的文件提交到项目工作目录
3.git 使用前配置
1.配置提交人姓名
- git config --global user.name zhangsan
2.配置提交人邮箱
- git config --global user.email 38781672@qq.com
3.查看 git 配置信息
- git config --list
配置只需执行一次,如果要对配置修改,重复上述命令即可
配置文件可找:C:\Users\admin 目录下的 .gitconfig 就是 git 配置文件 ,也可以在这里修改
4.提交步骤
1.初始化 git 仓库
git init
目录文件下会生成隐藏的.git 文件夹
2.查看文件状态
git status
显示信息
No commits yet
- 当前目录下没有任何提交
Untracked files:
(use "git add <file>..." to include in what will be committed)- 未被 git 跟踪管理的文件
3.文件列表,追踪管理文件
- git add
4.提交信息-向仓库中提交代码
- git commit -m 第一次提交
- 后面跟的是提交说明
- git commit -m 第一次提交
5.查看提交记录
git log
日志说明
commit
- 后面是提交的 ID
Author:
- 后面是提交的用户名和邮箱
Date:
- 后面跟着的是提交的时间
最下面
- 提交的说明
5.恢复记录(撤销)
git checkout 文件
- 恢复 暂存区中的文件到本地目录覆盖
git rm --cached 文件
- 将文件从暂存区中删除
git rest --hard commitID
将 git 仓库中 指定的 更新记录恢复出来,并覆盖暂存区和工作目录
先 git log 查看日志 查看并选定 copy commitID,再执行此命令+commitID 的值
6.分支管理
分支详细
主分支(master)
- 第一次向 git 仓库中提交更新记录自动产生的一个分支
开发分支(develop)
- 作为开发的分支,基于 master 分支创建
功能分支(feature)
- 作为开发具体功能的分支,基于开发分支创建
分支命令
git branch
- 查看分支
git branch 分支名称
- 创建分支
git checkout -b 子分支名
- 创建子分支
git checkout 分支名称
切换分支
切换分支前,当前分支工作区要先提交到仓库中,保证当前分支是完全干净的状态,否则会出现问题(后面的暂时保存和更改命令)
暂时保存和更改
存储临时改动
- git stash
恢复改动
- git stash pop
切换分支前使用
git merge 来源分支
合并分支
在主分支上合并开发分支
git branch -d 分支名称
- 删除分支(分支被合并后才允许删除)(-D 强制删除)
git push -u origin 分支名
- 推送新创建的分支到仓库
git push
Git 语法
git flow
命令
git pull
git push
合并相关
git merge
git fetch
git diff
进阶
git submodule
git subtree
冲突管理
merge request
code review
comment
rebase
reset
git repo
gitlab
gittea
github
gitee
git 工具
git bash
GUI
GitHub for Desktop
Source Tree
TortoiseGit
IDE
webstorm
VSCode
- GitLens
Xcode
Visual Studio
- Git Integration & GitHub Extension
代码托管服务平台
GitHub
代码托管服务和开源社区
多人协作开发流程
1.项目经理在自己的计算机中创建本地仓库
2.项目经理在 GitHub 中创建远程仓库
3.项目经理本地仓库推送到远程仓库
4.其他开发人员克隆远程仓库到本地开发
5.其他开发人员将本地仓库开发的内容推送到远程仓库
6.项目经理和其他开发人员将远程仓库中的最新内容拉到本地
流程方法
1.创建仓库
2.本地推送到远程仓库
3.远程仓库克隆到本地
子主题 4
6.解决冲突
7.跨团队协作
8.ssh 免登录
9.Git 忽略清单
10.仓库添加详细说明
码云 Gitee
Gitlab
Bitbucket
Codeberg
sourcehut
Gitee
gitrea
Git 服务器软件
开源的 Git 服务器软件
一个自托管的 Git 服务器,类似于开源的 GitHub/GitLab,自带 CI/CD 和看板功能。
Bower
一款包管理器
可以处理前端的静态资源
配合 npm 使用
FIS
百度前端开源工具框架
官网
- fis.baidu.com
CS 入门技能树 (csdn.net)
缺陷控制
概念
- 在项目的全生命周期 旨在提高软件的质量
方法论
常见问题
需求变更频繁
无代码 Review
团队各自为战
工期太紧
最佳实践
路径
质量
预防
监测
成本
人工
时间
资源投入
进度
分析原因
解决方法
进度
赶工
资源协调
客户沟通
压缩工期
质量
改进
返工
沟通
成本
工作流
质量管理
需求阶段
沟通
形成文档
客户确认
开发阶段
Lint 工具
Code Review
规范
运维规范
开发规范
测试
编写测试用例
自动化测试
运维阶段
监控
日志
更新迭代
责任到人
功能到点
时间设限
进度管理
需求阶段
从下至上分析
类比分析
经验分析
开发阶段
运维阶段
工具
代码类
ESLint
JSLint
StyleLint
流程类
禅道
Jira
Redmine
工具类
teambition
Trello
- 轻量
worktile
钉钉
石墨
自动化测试流程
文档管理分类
单元测试
组件测试(集成测试)
e2e 测试
framework
Mocha+Chai
jasmine
jest
Karma
工具
断言
Chai
Unexprected
快照测试
覆盖率
Istanbul
Jest
Blanket
codecov(展示)
e2e
Cypress
nightwatch
testcafe
文档管理
文档分类
接口文档
项目文档
使用说明
功能介绍
需求文档
流程图
原型图
详细需求
项目规划
成本估算
标准类文档
代码规范
运维规范
测试规范
文档管理工具
协同工具
国外
Google Docs
Ofiice 365
Alfresco
LogiclDOC CE
国内
WPS 云
语雀
石墨文档
有道云
一起写
其他
接口文档工具
Showdoc
elLinker
MinDoc
apizza
功能分类
协同
版本控制
在线编辑
文件保存
分享
本地化部署
其他
其他
gitbook
blog
注释产出 Api 文档
mock
RAP
APIJSON
打包构建工具
webpack
vite
Turbopack
介绍
Turbopack 是建立在 Turbo 之上的,Turbo 是基于 Rust 的开源、增量记忆化框架
Turbopack 建立在新的增量体系结构上,以获得最快的开发体验。在大型应用中,它展示出了 10 倍于 Vite 的速度,700 倍于 Webpack 的速度。在更大的应用中,差异更加巨大 —— 通常比 Vite 快 20 倍。
Turbopack 在开发环境只打包需要的最小资产,所以启动飞快。在一个 3000 个模块的应用里,Turbopack 只花了 1.8 秒启动,Vite 花了 11.4 秒
特性
1、天生增量,构建过的绝不重新构建
2、生态友好,支持 TypeScript、JSX、CSS、CSS Modules、WebAssembly 等
3、热更极快,比 Vite 快 10 倍
4、原生支持 RSC(React Server Components)
5、支持多环境,比如 Browser、Server、Edge、SSR、RSC
6、支持 NextJS
为啥快
1、基于 Rust 二进制语言
2、内置增量计算引擎。该引擎结合 Turborepo 以及 Google 的 Bazel 的增量计算的创新,可以将缓存提高到单个函数的水平
3、缓存。但现在只支持内存缓存,未来会支持持久化缓存,存文件系统或远程服务器
4、基于请求的按需编译。
网址
esbuild
其他项目工具
项目管理(Monorepo)方式
什么是 monorepo ?
Monorepo 是一种项目管理方式,在 Monorepo 之前,代码仓库管理方式是 MultiRepo,即每个项目都对应着一个单独的代码仓库每个项目进行分散管理这就会导致许多弊端,例如可能每个项目的基建以及工具库都是差不多的,基础代码的重复复用问题等等...
Monorepo 就是把多个项目放在一个仓库里面
Turborepo
介绍
TurboRepo 是构建 Javascript,Typescript 的 monorepo 高性能构建系统,Turborepo 抽象出所有烦人的配置、脚本和工具,减少项目配置的复杂性,可以让我们专注于业务的开发
用于 JavaScript 和 TypeScript 代码库的高性能构建系统。
网址
🚀Turborepo:发布当月就激增 3.8k Star,这款超神的新兴 Monorepo 方案,你不打算尝试下吗? - 掘金 (juejin.cn)
Bit
用于组件驱动开发的工具链
网址
Rush
一个可扩展的 web 单仓库管理器。
网址
Nx
具有一流的 monorepo 支持和强大集成的下一代构建系统。
网址
Lernajs
用于管理包含多个软件包的项目
网址
官网
github
项目代码风格指南
京东凹凸实验室前端代码规范
介绍
对比腾讯的代码规范,我更推荐凹凸实验室的代码规范,比较齐全。
HTML 规范
- 基于 W3C、苹果开发者等官方文档,并结合团队日常业务需求以及团队在日常开发过程中总结提炼出的经验而约定。
图片规范
- 了解各种图片格式特性,根据特性制定图片规范,包括但不限于图片的质量约定、图片引入方式、图片合并处理等。
CSS 规范
- 统一团队 CSS 代码书写和 SASS 预编译语言的语法风格,提供常用媒体查询语句和浏览器私有属性引用,并从业务层面统一规范常用模块的引用。
命名规范
- 从 “目录命名”、“图片命名”、“ClassName” 命名等层面约定规范团队的命名习惯,增强团队代码的可读性。
JavaScript 规范
- 统一团队的 JS 语法风格和书写习惯,减少程序出错的概率,其中也包含了 ES6 的语法规范和最佳实践。
网址
腾讯前端代码规范
网址
介绍
PC 端专题:快速上手、文件目录、页面头部、通用 title、通用 foot、统计代码、兼容测试
移动端专题:快速上手、文件目录、页面头部、REM 布局、通用 foot、统计代码、分享组件、兼容要求
百度前端代码规范文档
介绍
JavaScript 编码规范、HTML、CSS、Less、E-JSON 数据传输标准、模块和加载器、包结构、项目目录结构、图表库标准、react 编码规范
比如:缩进
[强制] 使用 4 个空格做为一个缩进层级,不允许使用 2 个空格 或 tab 字符。
[强制] switch 下的 case 和 default 必须增加一个缩进层级。
网址
网易编码规范
介绍
CSS 规范:一系列规则和方法,帮助你架构并管理好样式
HTML 规范:一系列建议和方法,帮助你搭建简洁严谨的结构
工程师规范:前端页面开发工程师的工作流程和团队协作规范
但是并不止于此,还有更多:
网址
谷歌开源项目风格指南
JavaScript Standard Style
除很多公司组织外,很多个人也在项目中使用的规范。
Airbnb 公司 JavaScript 风格指南
介绍
- 包含了:类型、对象、数组、字符串、函数、属性、变量、提升、比较运算符 & 等号、块、注释、空白、逗号、分号、类型转化、命名规则、存取器、构造函数、事件、模块、jQuery、ECMAScript 5 兼容性、测试、性能、资源、JavaScript 风格指南说明
网址
阿里巴巴
eslint-config-airbnb 翻译版
包含类型、对象、数组、字符串、函数、属性、变量、提升、比较运算符 & 等号、块、注释、空白、逗号、分号、类型转化、命名规则、存取器、构造函数、事件、模块、jQuery、ECMAScript 5 兼容性、测试、性能、资源、JavaScript 风格指南说明.
Vue 官方代码风格指南
介绍
这里是官方的 Vue 特有代码的风格指南。
如果在工程中使用 Vue,为了回避错误、小纠结和反模式,该指南是份不错的参考。
不过我们也不确信风格指南的所有内容对于所有的团队或工程都是理想的。
所以根据过去的经验、周围的技术栈、个人价值观做出有意义的偏差是可取的。
阮一峰的 ES6 编程风格
介绍
- 如何将 ES6 的新语法,运用到编码实践之中,与传统的 JavaScript 语法结合在一起,写出合理的、易于阅读和维护的代码。
Bootstrap 编码风格
介绍
内容包含 HTML 和 CSS。
HTML
- 语法、HTML5 doctype、语言属性、IE 兼容模式、字符编码、引入 CSS 和 JavaScript 文件、实用为王、属性顺序、布尔型属性、减少标签的数量、JavaScript 生成的标签。
CSS
- 语法、声明顺序、不要使用 @import、媒体查询(Media query)的位置、带前缀的属性、单行规则声明、简写形式的属性声明、Less 和 Sass 中的嵌套、Less 和 Sass 中的操作符、注释、class 命名、选择器、代码组织。
网址
风格检查美化工具
ESLint
介绍
目前绝大多数前端项目都会用到的 可组装的 JavaScrip t 和 JSX 检查工具。
发现问题
- ESLint 静态分析您的代码以快速发现问题。ESLint 内置于大多数文本编辑器中,您可以将 ESLint 作为持续集成管道的一部分运行。
自动修复
- ESLint 发现的许多问题都可以自动修复。ESLint 修复程序可识别语法,因此您不会遇到传统的查找和替换算法引入的错误。
定制
- 预处理代码,使用自定义解析器,并编写与 ESLint 内置规则一起使用的自己的规则。您可以自定义 ESLint,使其完全按照项目所需的方式工作。
网址
ESLint: https://eslint.org/
ESLint 中文网:https://eslint.bootcss.com/
Prettier
介绍
Prettier 是一个“有主见”的代码格式化工具。
简而言之,这个工具能够使输出代码保持风格一致。
也是目前绝大多数前端项目都会用到的哦。
网址
实用 .gitignore 文件模版:gitignore
介绍
- .gitignore 文件会告诉 git 要忽略项目中的哪些文件或文件夹。gitignore 是 GitHub 官方提供的 .gitignore 文件模版,收录了大量实用 .gitignore 模版,而该项目也是目前拥有 125k star、70.1 fork,是个实打实的明星项目。
网址
前端工程化工具 Feflow
介绍
- Feflow 是腾讯开源的用于提升工程效率的前端工作流和规范工具。目前已经在 NOW 直播、花样直播、花样交友、手 Q 附近、群视频、群送礼、回音、应用宝、企鹅号等业务广泛使用。
网址
JavaScript Obfuscator Tool:JavaScript 代码混淆工具
介绍
- 一个强大的 JavaScript 和 Node 混淆器.js
网址
项目架构
UI
基础知识
Git 命令
Node 环境
其他依赖环境
框架技术栈
动画
项目架构
跨域方案
目录规范
CSS 模块化
常用插件
路由封装
路由预加载和懒加载
缓存封装
接口请求封装
错误捕捉
打包构建优化
性能
js 压缩
开启 gzip 压缩
性能优化
其他知识
开发调试技巧
接口代理
Git 配置
服务器配置,Nginx 配置
项目部署
服务器购买和配置
Nginx 安装和配置
Node 环境安装和配置
项目部署和二级域名配置
项目开发 Plugin
有效利用 esLint、prettier、husky 以及 commitizen,因为使用了 TypeScript+ esLint 所以对代码的书写规范、类型、接口的使用必须有很高的要求,如果使用了不当的类型或者书写不规范,第一会导致代码提交到远程再到其他同学本地,会出现很多的 error,对这种情况,我们可以在 git 提交的钩子中进行代码的 per-commit,在这个阶段,主要是进行 lint&typecheck 操作,而且在进行 typecheck 的时候一定要加 noEmit,禁止有 error 的代码提交,同时使用 commitizen 规范 git commit 的信息,遵守 augular 规范。
模块化的导出和导入的区别
require 和 import 区别_邵天宇 Soy 的博客-CSDN 博客_import 和 require 的区别
module.exports、require 和 export、import 的关系 - 简书 (jianshu.com)